사실 이거는 별로 어렵지 않음
csv 형태로 잘 넣어주면 되기 때문에
docs: https://docs.influxdata.com/influxdb/cloud/write-data/developer-tools/csv/
다음의 공식 문서를 참고하면서 했음
#datatype measurement,tag,double,dateTime:RFC3339
m,host,used_percent,time
mem,host1,64.23,2020-01-01T00:00:00Z
mem,host2,72.01,2020-01-01T00:00:00Z
mem,host1,62.61,2020-01-01T00:00:10Z
mem,host2,72.98,2020-01-01T00:00:10Z
mem,host1,63.40,2020-01-01T00:00:20Z
mem,host2,73.77,2020-01-01T00:00:20Z중요한 건 윗 줄 두개인데, dataType과 field/tag명을 명시해 줘야 한다는 번거로움이 있음
measurement 와 tag 는 그냥 measurement, tag 이렇게 이름을 명시해주면 되고,
field의 경우에는 dataType을 지정해줘야 함. (그냥 field는 못읽는 것 같더라고요...,,,)
여튼 대충 저렇게 만들었다면 그 다음엔
influx write -b example-bucket -f path/to/example.csv이렇게 던져버렷!
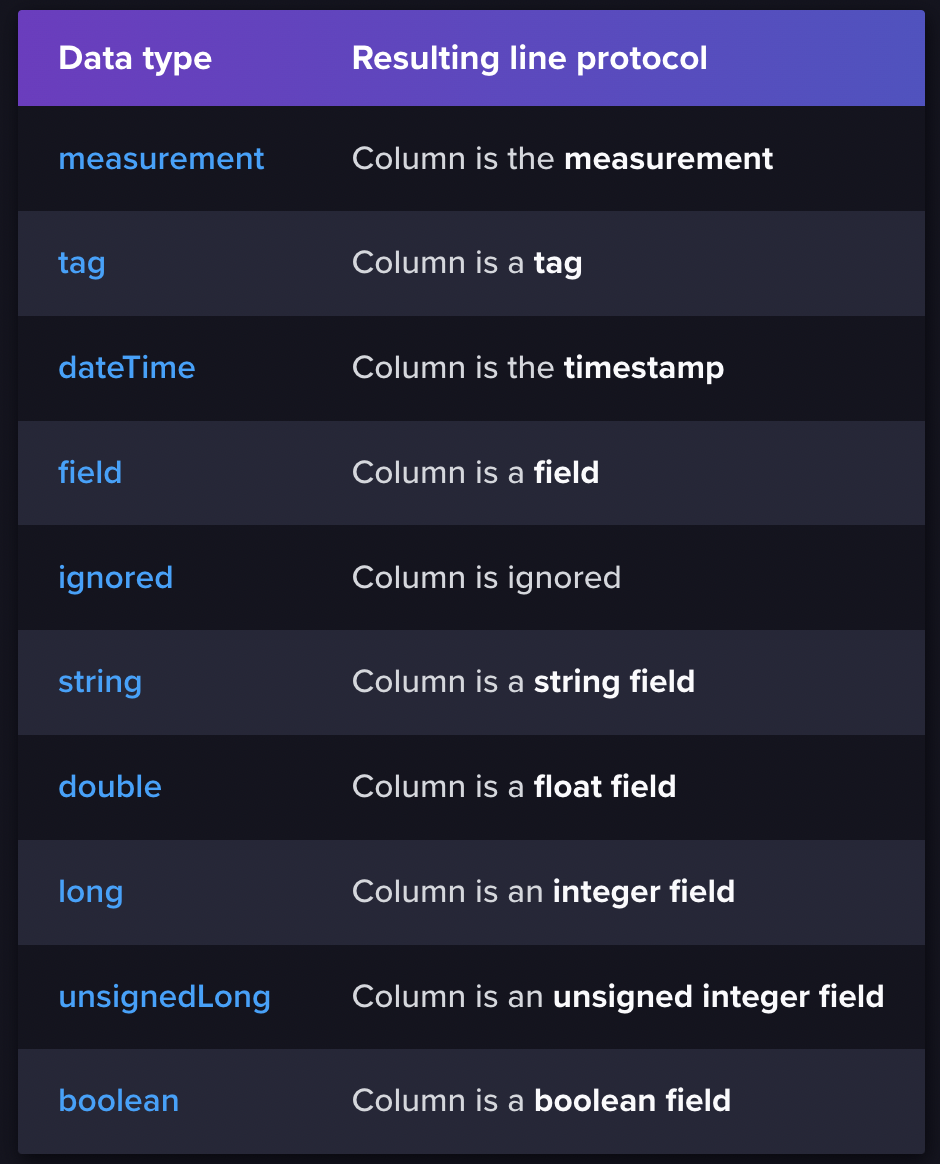
dateType의 경우에는 다음과 같이 string, double, long, boolean 정도를 제공함.
추가적으로 잘 보면 ignored가 있는데, 만약 csv 내에 하나의 field를 무시하고 싶다 (데이터를 넣고 싶지 않은 컬럼이 있다) 라고 한다면 저 ignored를 사용해주면 됨.
사실 처음엔 뭣도 모르고 그냥
sed -i '1 i\anything' file이걸 써서 추가했는데, 나중에 알고 보니 header에 달아주는 방법도 있더라
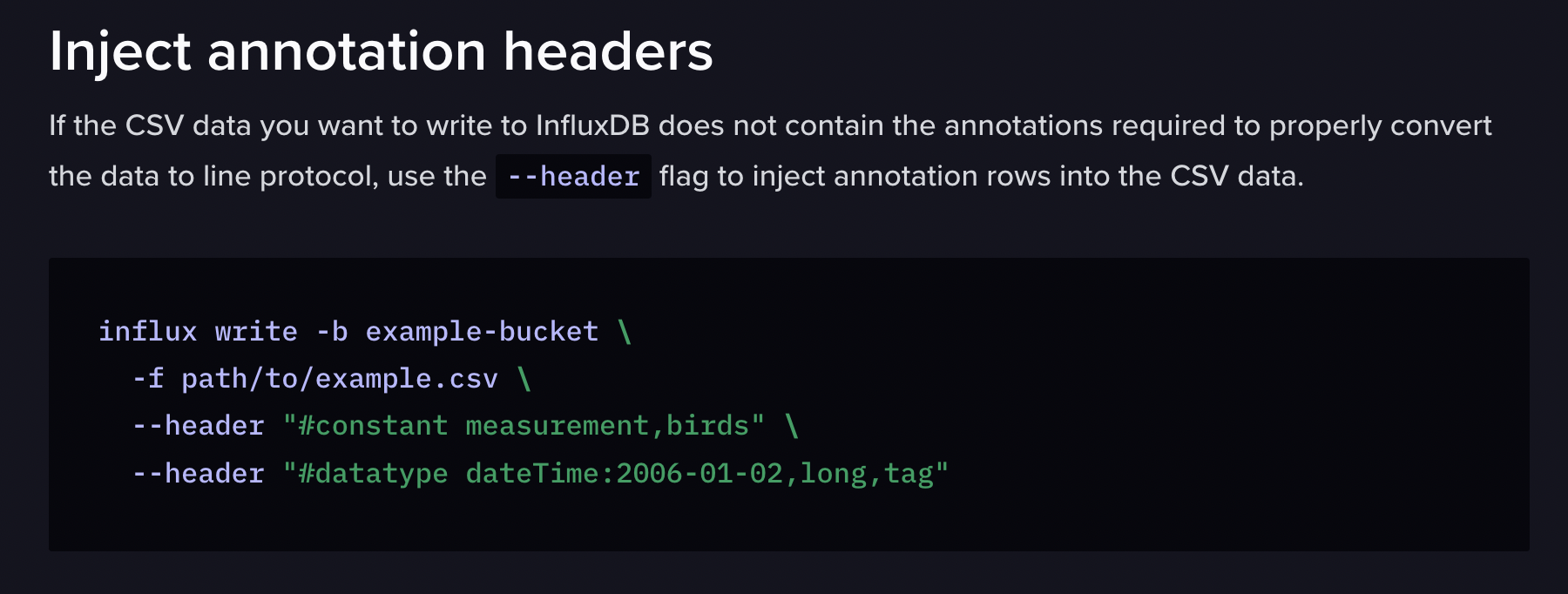
이렇게 그냥 헤더에 달아가지고 날리면 알아서 읽어가기도 하는 모양임!

분명히 처음엔 데린이었는데,, 이제 개린이인가..