Python이 그리워지는 나날들이다.. 언어 하나 배우는 건 진짜 말도 안되게 어려운 일이다.
근데 Haskell을 하려고 했다니 내가 미친게 틀림없어 ㅋㅋㅋㅋㅋ어쨌든, 오늘은 전에 프로젝트 할 때 다루었던 PyTorch로 data augmentation 간단하게 하는 방법을 정리해 둘 것이다.
배포하기 위해서 코드를 짰을 때는 OpenCV가 무거워서 그냥 numpy로 전처리하는 코드를 만들었었는데, 사실 그냥 데이터 augmentation 자체만으로는 pytorch에서 제공하는 걸 써도 되고 openCV에서 제공하는 걸 써도 상관없다.
개인적으로는 cv2를 이용해서 augmentation 하는 걸 선호했었는데, 다른 사람들도 알듯이 심플한 이유로 그냥 cv2가 사용하기 좋은 툴이어서 그랬다.
솔직히 근데 생각해보면 어차피 import 한 번 하는거 torch로 하면 두배로 쉽다는 게 팩트임.
torch
잡설 그만하고, 역시 참고자료는 PyTorch Docs이다. 이걸 독스라고 해도 되는걸까?
torchvision.transforms를 이용한다.

뭐 대충 이런 transform을 시킬 수 있다는 게 학계의 점심이다. (?난 이런 개그 좋아한다)
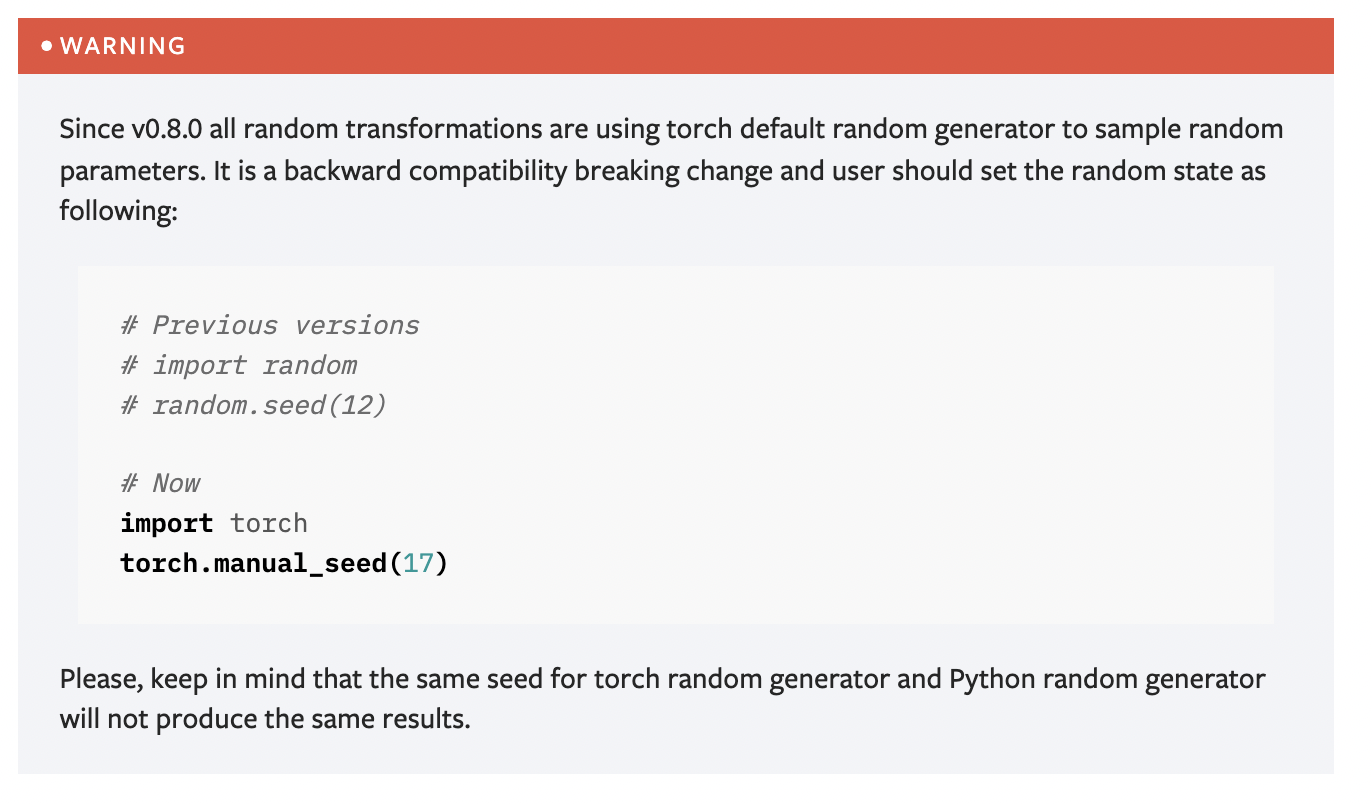
대충 8.0 버전부터 random_seed를 manual_seed로 사용해달라는 내용임.
호환성을 위해 그랬다고 한다.
data_transformation = transforms.Compose([
transforms.ToTensor(),
transforms.Resize((224,224)),
transforms.Normalize([0.5,0.5,0.5],[0.5,0.5,0.5])
])이렇게 사용했었..다 매우 간단-
그냥 data_transformation하는 방법을 transforms.Compose() 로 정의해주면 끝
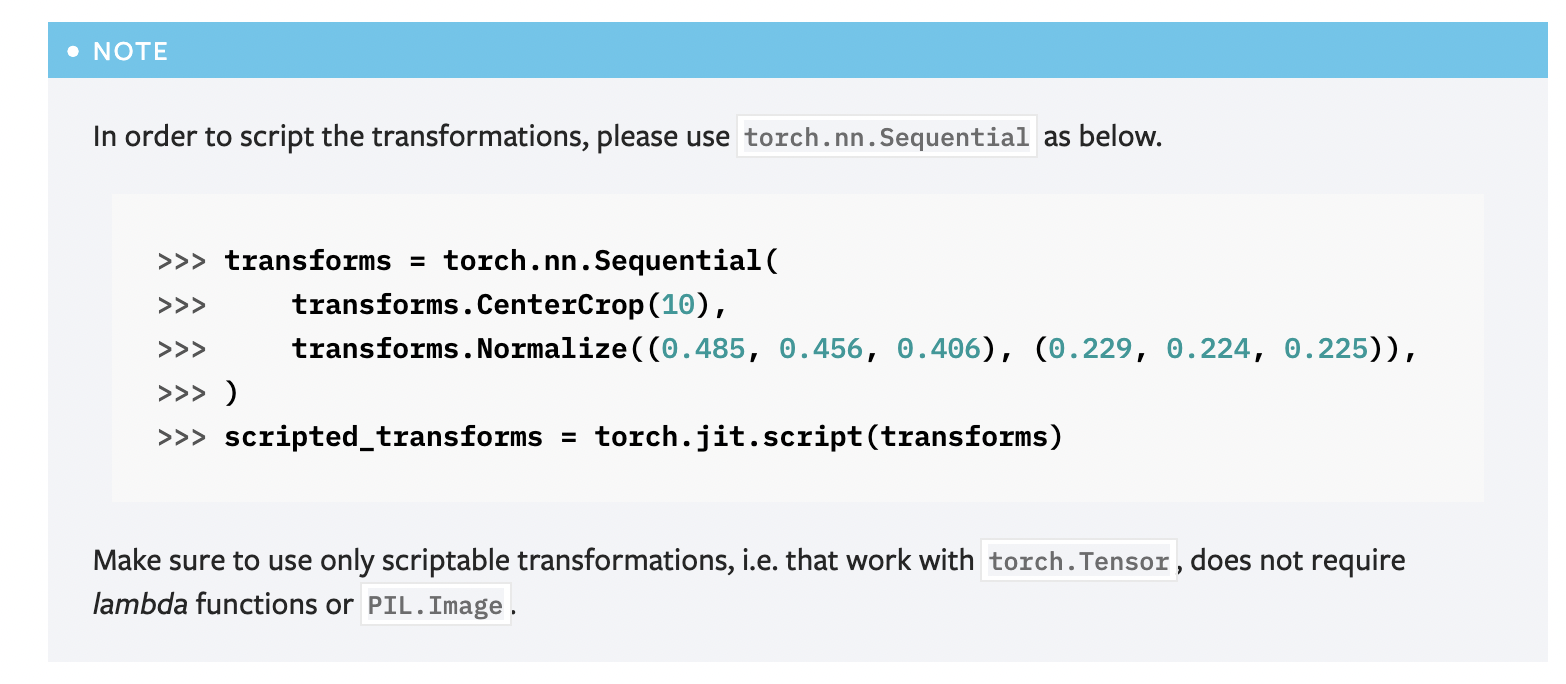
추가로 말하자면 Sequential로 만드는 것도 가능한 모양이다.
다시 본론으로 돌아와, 앞에 내가 사용한 코드에서 보면 ResNet에 적용하기 위해서 (224, 224)로 resize를 해준거다.
ToTensor()를 통해 tensor로 바꿔주고 (텐서라는 말 너무 귀여움)
그런 다음에 resize를 진행해줘야 한다.
Resize(224)를 하면 224*224가 된다고 분명히 독스에서 읽었는데, 내가 적용할 때는 버전 문제인지 에디터 문제인지 셀 문제인지 OS문제인지 잘 모르겠지만 (문제가 많다.ㅋㅋ) 어쨌든 적용이 안되어서 하나하나 지정해주었다.
지정해줄 땐 꼭 () 두번 써주기! 여기서 에러떠서 엉엉 울었던 기억이 있음ㅋㅋㅋㅋ
사실 에러의 대부분은 오타에서;
그리고 마지막으로 Normalize를 해주는데, Normalize 이게 또 이론이 참 재미있었다.
0.5로 주는 이유는 그냥 간단하게 0과 1의 사이가 0.5라서.. 원래는 RGB 각각의 평균을 내서 넣어주어야 한다는 점이다. 말 그대로 정규화니까.. -1에서 1 사이의 값으로 만들어준다고 한다.
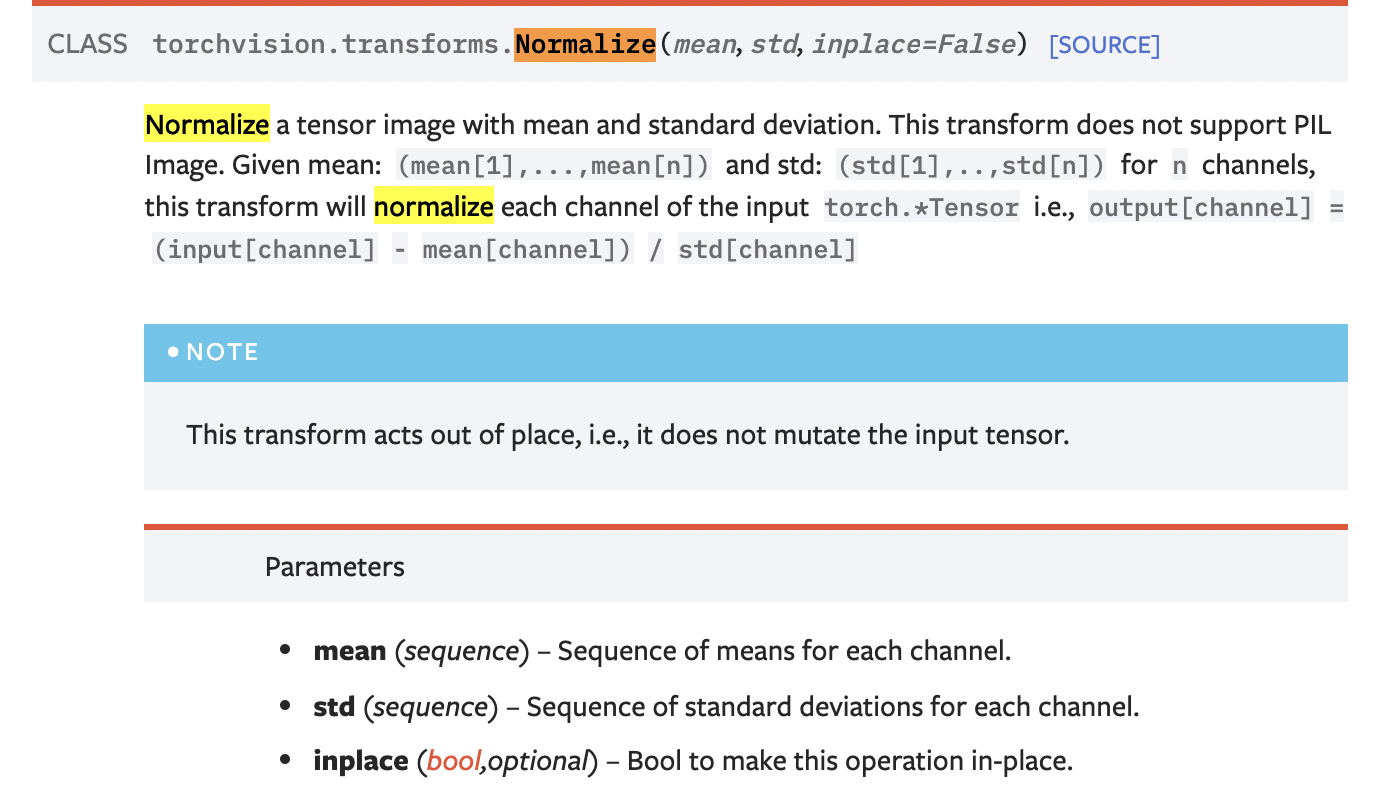
이거 덕에 코랩이 많이 뻗었다.transforms.Normalize([meanRed, meanGreen, meanBlue], [stdRed, stdGreen, stdBlue])원랜 이게 맞음... ㅎ.ㅎ.... std는 standard deviation, 표준편차임.
만약 찾고 싶다면 for문 돌려서 계산할 수 있다.
근데 이 Normalize 계산의 단점은 시간이 너무너무너무너누머누너무너무 오래 걸린다. 그도 그럴게 모든 셀의 RGB를 각각 연산.. 어후
아, 마지막으로 하나!!
여기 순서 진짜 중요하다. github보면 어떤 코드는 ToTensor()가 맨 뒤로 가있거나 한 코드가 있는데,
사실 나도 이유를 자세하게 알진 못한다. 근데 나는 Tensor 변환을 먼저 해주지 않으면 이상한 에러가 뜨더라..^^
그 외에도 다양한 파라미터를 제공한다.
크롭을 하거나, 패딩을 넣거나, 당연히 돌리는 것도 가능하다.
grayscale도 가능함.
나의 경우, 수집한 데이터의 특징이 굉장히 뚜렷해서, 롤 게임 이미지를 초록색 칠판으로 인식하고 뭐 이런 문제가 발견이 됐다.
그래서 grayscale을 넣어주거나 하는 방법도 시도를 했다.
사실 정확도에 엄청난 변화가 있진 않았음. 지금 생각하면 이왕 들고올 거 좀 잘 들고올걸
transform = transforms.Compose([
transforms.RandomHorizontalFlip()
])예시용으로 하나 들고온건데, randomhorizontalflip은 랜덤하게 수평으로 뒤집겠다는 거임.
다른 말로 사진 10장 중에 무작위로 몇 장을 수평으로 뒤집어서 학습시키겠다는 것!
이런 augmentation에서 주의할 점은, "random"이기 때문에 augmentation 할 때마다 달라진다는 거
그래서 아까 seed..
그리고 또 하나, "랜덤하게" flip하기 때문에 flip을 안하거나, 왼손-오른손을 구분하는 태스크 등에 노이징을 할 수 있다는 점.. 이런 것들을 꼭 생각해야한다.
다음번에는 이미지를 불러오는 여러가지 방법에 대해 포스팅해봐야겠다.
PIL, OpenCV, torchvision dataset등.. 다양한 방법이 있긔 8ㅁ8
