CNN 프로젝트를 할 때 항상 고민되는 건 데이터를 어떻게 가지고 올 것인지인 것 같다.
이미지 데이터는 저작권 문제도 있고 해서 어차피 상업용으로 쓰지는 못하고, 모델이나 데이터를 다른 곳에 제공하는 게 아니고 그냥 토이 프로젝트를 혼자 하는 경우라면 제일 만만한게 유튜브에서 영상을 끌고 와서 random하게 이미지를 추출하는 것이다.
YouTube에서 영상을 들고 와서 랜덤하게 잘라서 이미지를 추출한 다음, 영상에 대한 classification 모델을 만들 수도 있고 아니면 특징을 추출하는 것으로 해서 다양한 모델을 만들어볼 수 있을 것이다.
다만, 다른 사람의 영상을 맘대로 사용하는 것은 저작권법에 위반되는 행위니까 내가 사용하고자 하는 방향이 어떤 방향인지 사전 조사를 철저히 하길 바란다.
https://github.com/googleapis/google-api-python-client/blob/main/docs/start.md
추신: 데린이라 코드가 깔끔하진 않아요.. 돌아가는 것에 만족하는 수준이라..양해 부탁드립니다 😵💫채널 아이디를 통해 채널 영상 추출해오기
필요한 라이브러리
import pandas as pd
import numpy as np
import requests
from apiclient.discovery import build
from apiclient.errors import HttpError
from oauth2client.tools import argparser필요한 라이브러리는 이정도입니다.
1. Developer API 확인 및 가져오기
API를 다운받으려면 developerKey를 받아와야겠죠
https://developers.google.com/youtube/v3/getting-started?hl=ko
위 링크를 따라가서 천천히 따라하시고 api 를 이용하기 위한 developer key를 받아오세요
2. 채널 아이디 가져오기
일단 아이디를 확인하는 방법은 이렇습니다.

유튜브 채널 아이디는 받고싶은 채널의 메인 페이지로 들어가서
위의 주소창에 'channel/' 뒷부분에 해당하는 것을 가져오면 됩니다.
물론 이것도 코드로 구현할 수 있는데, 제가 오늘은 시간이 없어서..
추후 수정하겠습니다.
3. build를 통해 connection 만들기
이건 제가 쓰는 말이긴 합니다만.. docs를 읽어보시면 일단 build를 통해 내 developerKey와 어떤 서비스를 사용할 것인지, 어떤 버전인지를 입력한 다음 connection을 만들게 되어 있습니다.
따라서 우리는 얻어온 DeveloperKey를 통해 connection을 build해줍니다.
DEVELOPER_KEY = "AxxxxxxxxxxxxxuB_xxxxxxxxxxxxxxxpQY"
YOUTUBE_API_SERVICE_NAME = "youtube"
YOUTUBE_API_VERSION = "v3"
connection = build('youtube', 'v3', developerKey=DEVELOPER_KEY)4. response 받아오기
이제 connection을 만들었으니 이 connection으로 데이터를 response로 받아올 수 있겠죠!
response를 작성해줍니다.
https://developers.google.com/youtube/v3/docs/search/list?hl=ko#python,-예-1
굉장히 잘 설명되어 있으므로 docs를 참고하시면 많은 도움이 될 거에요.response = connection.search().list(
part="id, snippet",
channelId="UC0YCcDDGxxxxxxxxxCIVhQ",
maxResults=1
).execute()간단하게 설명 드리자면, connection을 통해 search하고, 그것을 List로 받아올게 정도로 이해할 수 있을 것 같습니다.
part는 필수 파라미터로, "id"는 기본적으로 받아오시는 게 좋아 보입니다. (식별자 정도로)
channelId는 영상을 가져올 채널의 id를 넣어주시면 됩니다.!
maxResults는 가지고 오고 싶은 영상 갯수를 넣어주시면 됩니다.
만약 가져오고 싶은 만큼 입력했는데 영상이 입력한 수만큼 들어오지 않았다면
youtube#playlist 같은 데이터가 같이 들어와서 걸러진 거라고 생각됩니다.
따라서 갯수를 조금 더 늘려보시길 추천드려용들어오는 데이터 타입 확인
제가 처음에 데이터 타입 확인에서 너무 헷갈렸기때문에 간단하게 짚고 넘어갈게요

데이터는 다음과 같은 형태로 들어옵니다.
조금 복잡하죠 dict안에 str, dict 그리고 그 dict 안에 dict와 같은 형태로 들어옵니다.
for result in response.get("items", []):
for r,v in result.items():
if type(v) == dict:
for k1, v1 in v.items():
print(" ",k1,":",v1)
else:
pass
print(r,":",v)저는 다른 거 생각이 안나서 for 두개 돌렸습니다..ㅠㅠ암튼간에 이런 식으로 데이터 꼭 확인하시고 data append 작성하시면 좋을 것 같아요
5. pytube를 이용해서 영상 다운로드
이제 pytube를 이용해서 영상을 다운로드해봅시다.
추가 ) 에러
22.02.13 기준 AttributeError:'NoneType' object has no attribute 'span' 이슈가 있어서 확인했더니 작년 말부터 있었던 에러인 것 같습니다.
pip install pytube 하지 않고 pip install git+https://github.com/baxterisme/pytube을 함으로써 에러를 해결했습니다.
참고:https://pyquestions.com/pytube-attributeerror-nonetype-object-has-no-attribute-spanpip install git+https://github.com/baxterisme/pytube
from pytube import YouTubepip install 후 아까 불러온 비디오 제목 : 비디오 아이디 값을 아이디 리스트로 정리해줍니다.
vid_id_list = list(videos.values())아까와 마찬가지로 pytube도 기본적으로는 url을 통해 yt를 만들어서 이를 통해 영상을 가져온다고 생각하면 이해가 빠를 것 같습니다.
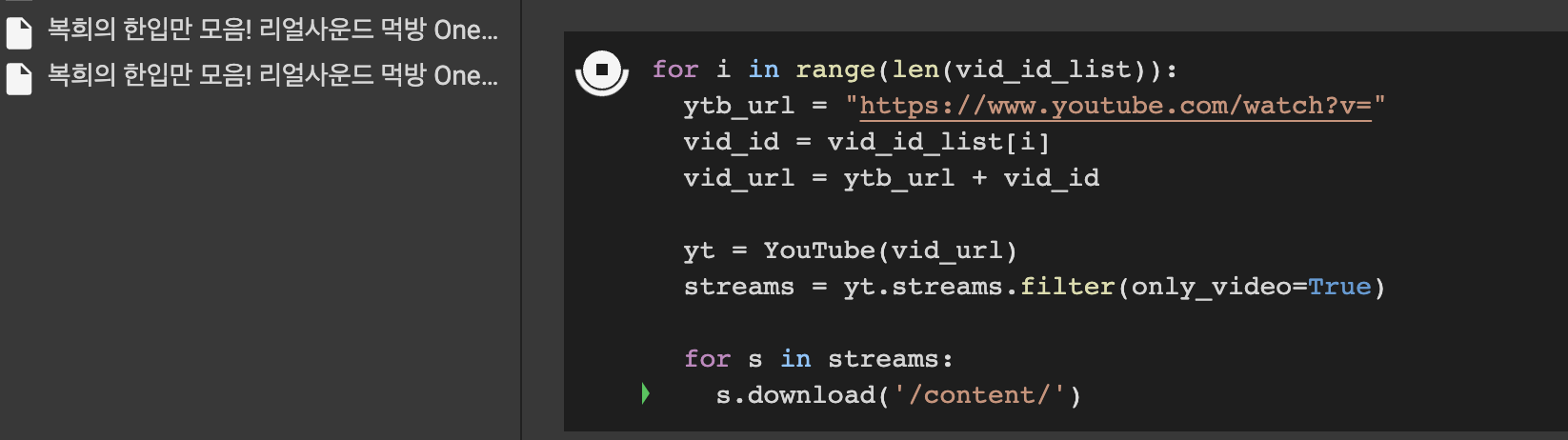
for i in range(len(vid_id_list)):
ytb_url = "https://www.youtube.com/watch?v="
vid_id = vid_id_list[i]
vid_url = ytb_url + vid_id
yt = YouTube(vid_url)
streams = yt.streams.filter(only_video=True)
for s in streams:
s.download('[저장 경로]')ytb_url에 해당하는 부분은 그냥 영상 기본 url 값입니다. 그냥 영상 몇 개 보니까 그렇더라고요..
그리고 filter 파라미터는
pytube docs 가시면 잘 설명되어 있습니다. 저는 audio 말고 이미지만 필요해서 only_video 했습니다.
마지막으로 다운로드 받아서 어디에 저장할건지 경로 설정까지 해주시면 끝입니다.
이렇게 영상이 잘 들어오는 걸 보실 수 있어요

구글에서 더블클릭하니 다운도 잘 됩니다.
확장자와 영상 화질 등에 대해
위 이미지를 보면 영상이 두개씩 들어오더라구요..
저도 처음에는 뭐지 했는데 확장자가 webm과 mp4로 두 개 다 들어옵니다.
영상 화질은 144로 들어오고 사이즈는 제각각인 것 같더라구요.
따라서 모델 돌릴 땐 전처리가 반드시 필요합니다.
