Parsing dates with date parts
datepart()
datename()
parts :
- year/month/day
- day of year
- day of week
DECLARE
@SomeTime DATETIME2(7) = SYSUTCDATETIME();
-- Retrieve the year, month, and day
SELECT
YEAR(@SomeTime) AS TheYear,
MONTH(@SomeTime) AS TheMonth,
DAY(@SomeTime) AS TheDay;comparing dates
DECLARE
@BerlinWallFalls DATETIME2(7) = '1989-11-09 23:49:36.2294852';
-- Fill in each date part
SELECT
DATEPART(YEAR, @BerlinWallFalls) AS TheYeardateadd : add dates with intervals
DECLARE
@LeapDay DATETIME2(7) = '2012-02-29 18:00:00';
-- Fill in the date parts and intervals as needed
SELECT
DATEADD(DAY, -1, @LeapDay) AS PriorDayFormatting dates for reporting
: useful for converting one data type to another data type
CAST() :
- no control over formatting from dates to strings
- ANSI SQL standard, meaning any relational and most non-relational DB have this function
CAST(@SomeDate AS NVARCAHR(30)) AS ACONVERT() :
- some control over formatting from dates to strings using the style parameter
- specific to T-SQL

DECLARE
@CubsWinWorldSeries DATETIME2(3) = '2016-11-03 00:30:29.245';
SELECT
CONVERT(DATE, @CubsWinWorldSeries) AS CubsWinDateForm,
CONVERT(NVARCHAR(30), @CubsWinWorldSeries) AS CubsWinStringForm;FORMAT() :
- much more flexibility over formatting from dates to strings than either
CAST()orCONVERT() - specific to T-SQL
T-SQL?
Transact-SQL : SQL 표준에서 확장하여 문자열 처리, 날짜 처리, 계산 등을 위한 다양한 지원 함수, delete 및 update 문에 대한 변경, 절차적 프로그래밍, 지역 변수를 포함함
이러한 부가 기능들은 트랜잭트 SQL을 튜링 완전으로 만든다.튜링 완전? : 튜링 기계와 동일한 계산 능력을 가진다는 의미.. 튜링 기계는 여러가지 기호들을 일정한 규칙에 따라 바꾸는 기계인데.. 이 기계는 적당한 규칙과 기호를 입력한다면 일반적인 컴퓨터의 알고리즘을 수행할 수 있는 것이라고 한다.. 컴퓨터 CPU의 기능을 설명하는데 상당히 유용하다
오 이거 참 흥미롭기는 하지만 더 들어가면 너무 산으로 빠질 것같다
ref : https://ko.wikipedia.org/wiki/%ED%8A%B8%EB%9E%9C%EC%9E%AD%ED%8A%B8_SQL
ref : https://ko.wikipedia.org/wiki/%ED%8A%9C%EB%A7%81_%EC%99%84%EC%A0%84
ref : https://ko.wikipedia.org/wiki/%ED%8A%9C%EB%A7%81_%EA%B8%B0%EA%B3%84
++ format이 다른 함수들보다 좀 느린 경향이 있다.
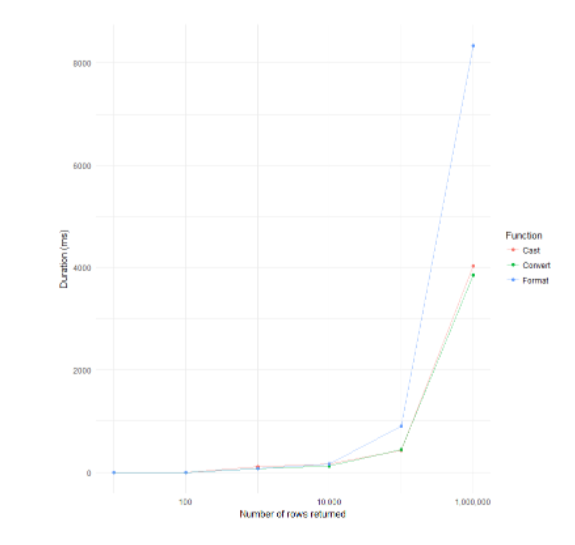
DECLARE
@Python3ReleaseDate DATETIME2(3) = '2008-12-03 19:45:00.033';
SELECT
-- 20081203
format(@Python3ReleaseDate, 'yyyyMMdd') AS F1Working with calendar tables
Apply()
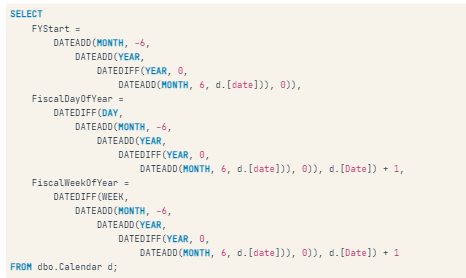

Building from parts
DATEFROMPARTS(y, m, d)TIMEFROMPARTS(h, m, s, fraction, precision)DATETIMEFROMPARTS(y, m, d, h, minute, s, ms)DATETIME2FROMPARTS(y, m, d, h, minute, s, fraction, precision)SMALLDATETIMEFROMPARTS(y, m, d, h, minute)DATETIMEOFFSETFROMPARTS(y, m ,d, h, minute, s, fraction, hour_offset, minute_offset, precision)

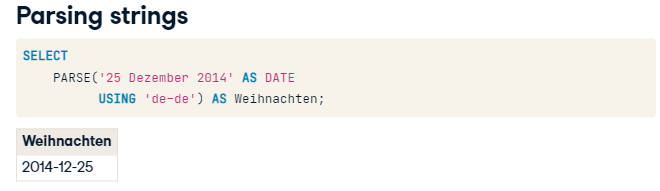
Translating date strings
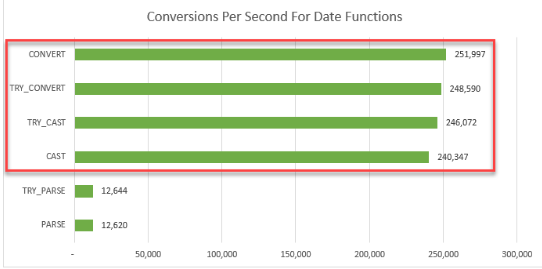
Cost of parsing
| function | conversions per sec |
|---|---|
CONVERT() | 251,997 |
CAST() | 240,347 |
PARSE() | 12,620 |
- 따라서 양이 크다면
CONVERT()나CAST()를, 작으면서 퍼포먼스가 좋길 바란다면PARSE()를 사용하길 권함
Handling invalid dates
- Unsafe : CAST, CONVERT, PARSE
- Safe : TRY_CAST, TRY_CONVERT, TRY_PARSE

에러를 뱉지 않고 이렇게 리턴해준다고 한다.
Basic aggregation functions
| counts | other aggregates |
|---|---|
COUNT() | SUM() |
COUNT_BIG() | MIN() |
COUNT(DISTINCT) | MAX() |
SUM(CASE WHEN ir.NumberOfIncidents > 5 THEN 1 ELSE 0 END) AS NumberOfBigIncidentDays,- AVG() : mean
- STDEV() : standard deviation
- STDEVP() : population standard deviation
- VAR() : variance
- VARP() : population variance
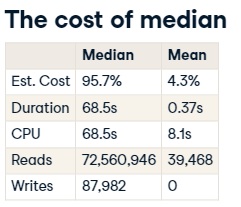
sql에서 median 의 경우 전체 row를 모두 본 다음에 리턴하기때문에 힘들다는 것..
Downsampling and upsampling data
| Downsampling | Upsampling |
|---|---|
| Aggregate data | Disaggregate data |
| Can usually sum or count results | Need an allocation rule |
| Provides a higher-level picture of the data | Provides artificial granularity |
Grouping
-
ROLLUP: hierarchical data -
CUBE: cartesian aggregation -
GROUPING SETS: to any

Using aggregation functions over windows
ROW_NUMBER() : unique
RANK() : not unique, can skip numbers
DENSE_RANK() : does not skip numbers
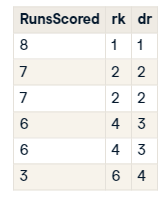
Partitions :
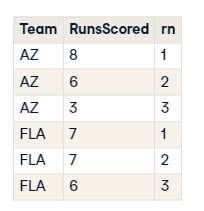
- RANK PARTITIONed by some standard
LAG( ) and LEAD( )
LAG(): return prior rowLEAD(): return next row
+ CTE (Common Table Expression)
CTE :
- 쿼리 실행 중에 메모리에 존재하는 테이블
- 쿼리 내부에서 임시 테이블을 정의하는 것
- 예비 동작 없이 쿼리문 내부에서 모든 것을 일괄 처리
with구문으로 쿼리문에 대해 이름을 붙여 생성
