
인덱스란 ?
추가적인 쓰기작업과 저장 공간을 활용하여 데이터베이스 테이블의 검색 속도를 향상시키기 위한 자료구조이다.
데이터베이스에서도 테이블의 모든 데이터를 검색하면 시간이 오래 걸리기 때문에 데이터와 데이터의위치를 포함한 자료구조를 생성하여 빠르게 조회할 수 있도록 돕는 것이다.
예시로 책의 목차로 생각하면 좋다. 주로 쿼리의 성능을 높이기 위해 사용
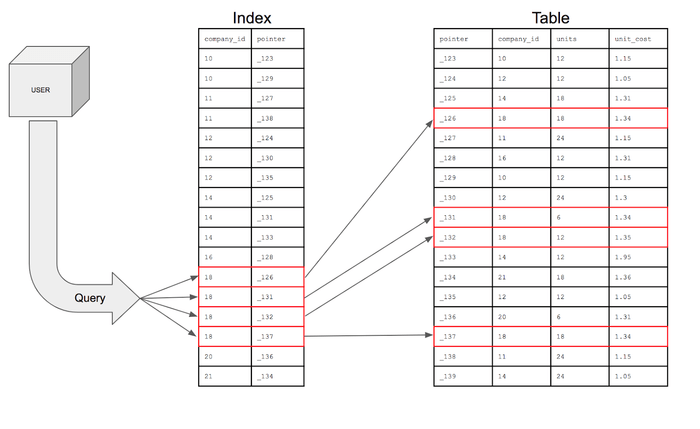
인덱스의 자료구조
인덱스는 여러자료 구조를 이용해서 구현 할 수 있는데, 대표적인 자료구조로 해시테이블과 B+Tree가 있다.
- 해시 테이블
해시 테이블은 컬럼의 값과 물리적 주소를 (key,value)의 한 쌍으로 저장하는 자료구조이다. 하지만 해시 테이블은 실제로 인덱스에서 잘 사용하지 않는다.
이유는 해시테이블은 = 등호 연산에 최적화 되어있기 때문이다. 데이터베이스에서는 <> 부등호 연산이 자주 사용되는데, 해시 테이블 내의 테이버들은 정렬되어 있지 않으므로 특정 기준보다 크거나 작은 값을 빠른 시간 내에 찾을수가 없다.

- B+Tree
B+Tree는 대부분의 DBMS 그리고 오라클에서 특히 중점적으로 사용하고 있는 가장 보편적인 인덱스이다. 구조는 Root Node / Branch Node/ Leaf Node로 구성되며 계층적 구조를 가지고 있다.

인덱스의 장단점
장점 : 인덱스를 사용하는 이유
- 데이터가 정렬되어 있기 때문에 테이블에서 검색과 정렬 속도를 향상시킨다.
- 조건 검색 Where절의 효율성: 보통 Where절의 사용할 때 특정 조건에 맞는 데이터를 찾기 위해 데이터를 처음부터 끝까지 다 비교해야 하는데, 인덱스를 통해 데이터가 정렬되어 있으면 빠르게 찾아낼 수 있다.
- 정렬 Order by 정의 효율성: 인덱스를 사용하면 Order by에 의한 Sort과정을 피할 수 있다. 본래 Order by는 괴장히 부하가 많이 걸리는 작업이기 때문에 인덱스를 통해 이미 정렬되어 있으면 부하가 걸리지 않을 수 있다.
- MIN, MAX의 효율적인 처리가 가능: 이것또한 인덱스를 통해 데이터가 정렬되어 있기 때문에 처음부터 끝까지 뒤져서 찾는 것이 아닌 인덱스로 정렬된 데이터에서 MIN,MAX를 효율적으로 추출 할 수 있다.
-
인덱스를 사용하면 테이블 행의 고유성을 강화시킬 수 있다.
-
시스템의 전반적인 부화를 줄일 수 있다.
단점 : 인덱스 사용시 주의할 점
-
인덱스의 가장 큰 문제점은 정렬된 상태를 계속 유지시켜야 한다는 점이다.
인덱스가 적용된 컬럼에 정렬을 변경시키는 INSERT, UPDATE, DELETE 명령어가 수행된다면 계속 정렬을 해주어해서 그에 따른 부하가 발생한다. 이런 부하를 최소화하기 위해 인덱스는 데이터 삭제라는 개념에서 인덱스를 사용하지 않는다 라는 작업으로 이를 대신한다. -
인덱스 스캔이 무조건 좋은 것은 아니다.
예를 들면 검색으로 1개의 데이터가 있는 테이블과, 100만개의 데이터가 들어있는 테이블이 있다고 가정하면 100만개의 데이터가 들어있는 테이블이라면 풀 스캔보다 인덱스 스캔이 유리하겠지만, 1개의 데이터가 들어있는 테이블은 인덱스 스캔보다 풀 스캔이 더 빠르다. -
속도 향상을 위해 인덱스를 많이 만드는 것은 좋지 않다.
인덱스를 관리하기 위해서 데이터베이스의 약 10%에 해당다는 저장공간이 추가로 필요하다. 때문에 많은 인덱스를 생성하면, 하나의 쿼리문을 빠르게 만들수는 있지만, 전체적인 데이터베이스의 성능 부하가 일어날수있다. 때문에 무조건적인 인덱스 생성보다 SQL문을 효율적으로 짜고, 인덱스 생성은 마지막 수단으로 사용해야한다.
