
“Android 로봇은 Google에서 제작하여 공유한 저작물을 복제하거나 수정한 것으로 Creative Commons 3.0 저작자 표시 라이선스의 약관에 따라 사용되었습니다.”
크롤링(Crawlling)이란?
크롤링이란 웹페이지를 그대로 가져와서 데이터를 추출하는 것을 일컫는다.
여러가지 방법이 있지만 필자는 Android에서 사용하기 위해
Java에서 크롤링을 할 수 있게 도와주는 Jsoup라는 API를 사용할 예정이다.
Jsoup는 HTML을 파싱해서 특정 조건을 가진 태그만을 선택해서 가져올 수 있다.
시작해보자
먼저 Dependency를 추가해주자
implementation 'org.jsoup:jsoup:1.13.1'
그리고 permission도 manifest에 추가해주자
<uses-permission android:name="android.permission.INTERNET" />
그리고 코드를 아래와 같이 작성해주자
fun main() {
Thread {
val document = Jsoup.connect("https://velog.io/@jeep_chief_14").get()
val elements = document.select("h2")
elements?.let {
it.forEach { el ->
println(el.text())
}
}
}.start()
}참고로 Jsoup은 http connection을 사용한 네트워크 통신을 하기 때문에 반드시 비동기 처리를 해주어야한다.
안해줬다간 시뻘건 에러메세지를 조우하게 된다.
-
Document
타겟 페이지의 사본이라고 생각하면 편할 거 같다.
이Document의select메소드를 통해서
원하는 태그들을 가져올 수 있다. -
Elements
가져온 태그들(Element)의 집합체
실제로ArrayList<Element>를 상속받는다. -
Element
우리들이 실질적으로 원하던 그 태그.
text()메소드를 통해서 내용을 반환 할 수 있다.
그 외에도attr()메소드를 이용해서 속성값을 가져올 수도 있다.
타겟 페이지는 필자의 블로그로 하고 실행을 해보면..
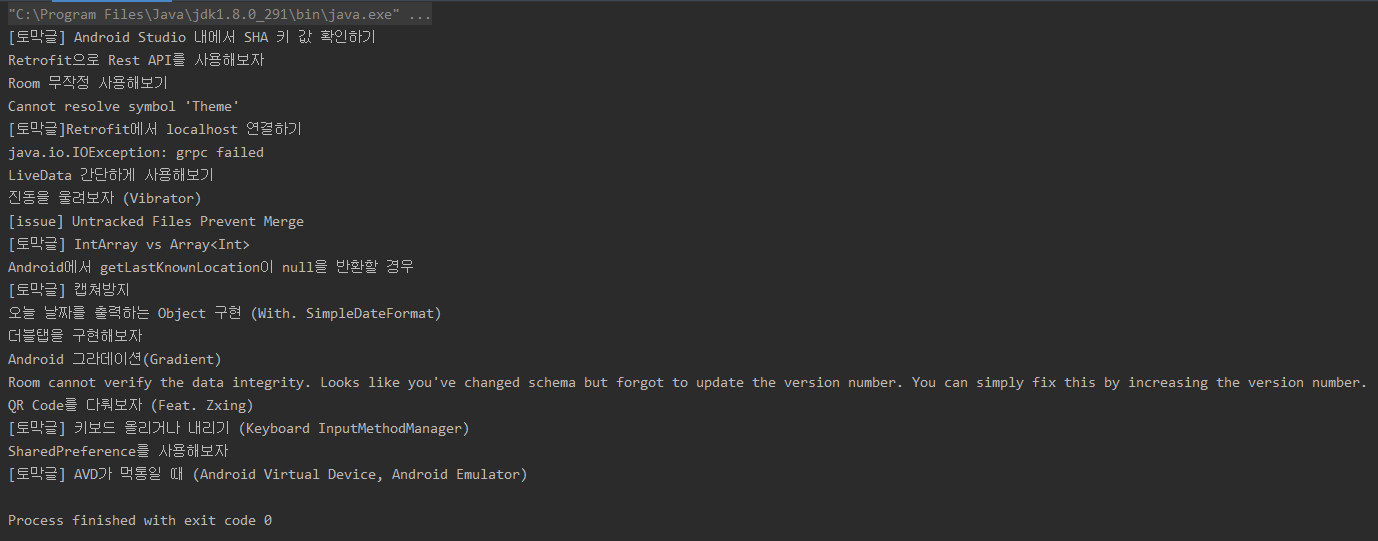
h2태그로 되어있는 포스팅 제목들만 골라서 가져온 것을 확인할 수 있다.
개인적으로 공부했던 것을 바탕으로 작성하다보니
잘못된 정보가 있을수도 있습니다.
인지하게 되면 추후 수정하겠습니다.
피드백은 언제나 환영합니다.
읽어주셔서 감사합니다.
