시퀀스형
2.1 내장 시퀀스 개요
자료형의 종류
컨테이너(Container) : 서로다른 자료형을 담음
list, tuple, collections.deque
- 가변형 :
list, deque- 불변형 :
tuple플랫(Flat) : 한 유형의 자료형만 담음
str, bytes, bytearray, array.array, memoryview
가변형 :
bytearray, array.array, memoryview불변형 :
str, bytes
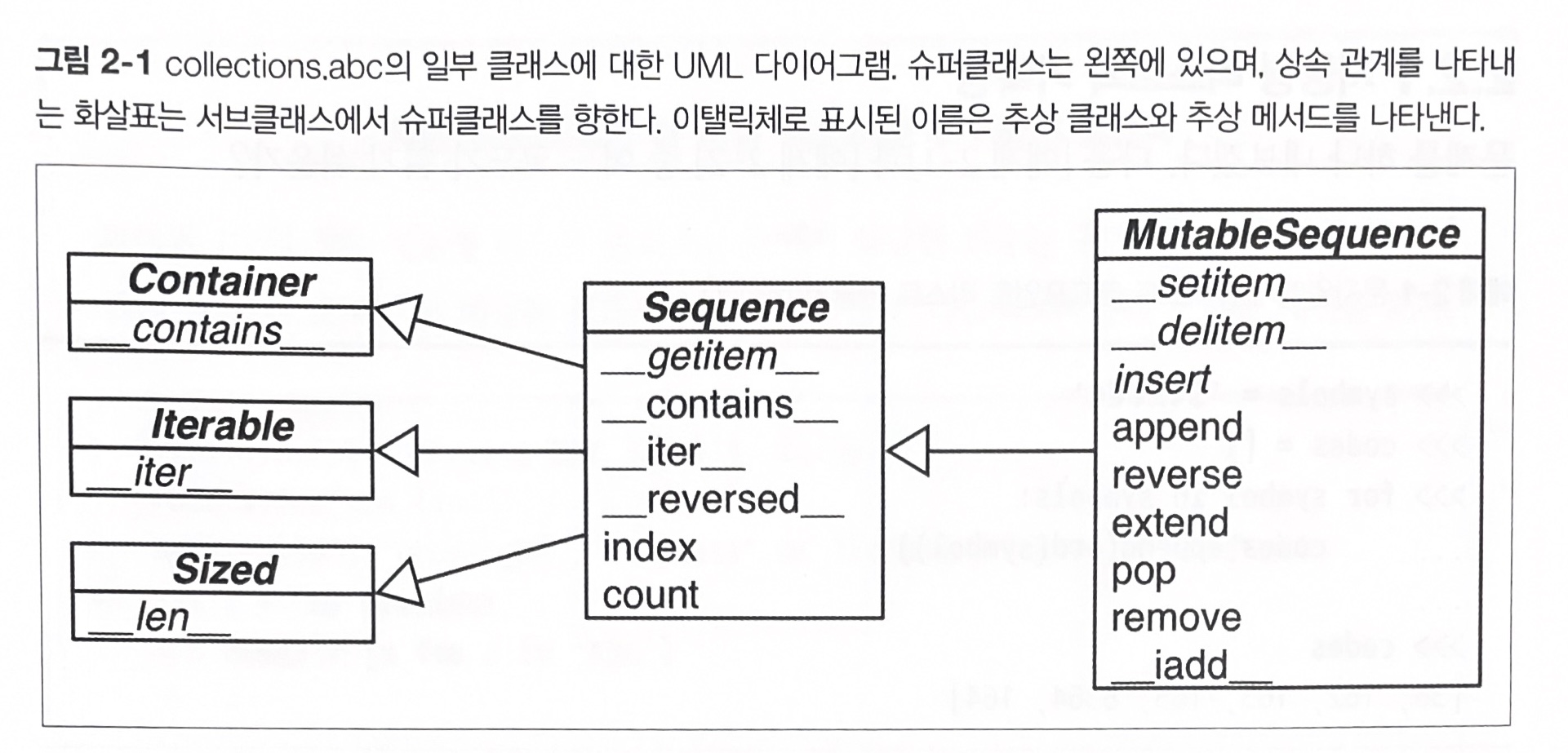
그럼 ImmutableSequence 중 하나인 tuple에는 진짜 맨오른쪽 박스에 있는 메소드들이 다 없을까?
내 눈으로 보기 전엔 믿을 수 없어서, 직접 확인해봤다.
a = [1, 2, 3]
b = (1, 2, 3)
print(a.__dir__(), '=='*50)
print(b.__dir__(), '=='*50)['__repr__', '__hash__', '__getattribute__', '__lt__', '__le__', '__eq__', '__ne__', '__gt__', '__ge__', '__iter__', '__init__', '__len__', '__getitem__', '__setitem__', '__delitem__', '__add__', '__mul__', '__rmul__', '__contains__', '__iadd__', '__imul__', '__new__', '__reversed__', '__sizeof__', 'clear', 'copy', 'append', 'insert', 'extend', 'pop', 'remove', 'index', 'count', 'reverse', 'sort', '__class_getitem__', '__doc__', '__str__', '__setattr__', '__delattr__', '__reduce_ex__', '__reduce__', '__subclasshook__', '__init_subclass__', '__format__', '__dir__', '__class__'] ====================================================================================================
['__repr__', '__hash__', '__getattribute__', '__lt__', '__le__', '__eq__', '__ne__', '__gt__', '__ge__', '__iter__', '__len__', '__getitem__', '__add__', '__mul__', '__rmul__', '__contains__', '__new__', '__getnewargs__', 'index', 'count', '__class_getitem__', '__doc__', '__str__', '__setattr__', '__delattr__', '__init__', '__reduce_ex__', '__reduce__', '__subclasshook__', '__init_subclass__', '__format__', '__sizeof__', '__dir__', '__class__'] ====================================================================================================set(a.__dir__()) - set(b.__dir__()){'__delitem__',
'__iadd__',
'__imul__',
'__reversed__',
'__setitem__',
'append',
'clear',
'copy',
'extend',
'insert',
'pop',
'remove',
'reverse',
'sort'}=> 진짜 없다.
2.2 지능형 리스트와 제네레이터 표현식
지능형 리스트(Comprehending Lists)
Comprehending Lists : 가독성이 좋고, 실행속도도 빠름
=> 따라서 데이터가 클 경우엔 List comprehensions을 추천함 (큰 차이는 없음)
- 오로지 새로운 리스트를 만드는 일만 함
- => 따라서 생성된 리스트를 사용하지 않을 거라면 사용 XXX
- => 또한 두 줄 이상 넘어가면, 코드 분할 or for문 사용!
for문으로 접근
# Comprehending Lists
import time
chars = '+)(*&^%$#@!)' # str은 불변형
code_list1 = []
for s in chars:
code_list1.append(ord(s))
print(code_list1)[43, 41, 40, 42, 38, 94, 37, 36, 35, 64, 33, 41]listcomp. 로 접근
code_list2 = [ord(s) for s in chars]
print(code_list2)[43, 41, 40, 42, 38, 94, 37, 36, 35, 64, 33, 41]
변수의 유효범위 이슈
x = 'ABC'
dummy = [ord(x) for x in x]
print(x)
print(dummy)ABC # x의 값이 유지된다.
[65, 66, 67] # listcomp.도 기대했던 대로 완성!2.2.3 데카르트 곱(별로 중요해보이진 않음)
데카르트 곱은 두 개 이상의 리스트에 있는 모든 항목을 이용해서 만든 튜플로 구성된 리스트이며, 지능형 리스트를 통해서도 만들 수 있다.
colors = ['black', 'white']
sizes = list('SML')
# color 다음에 size를 배치해서 만든 튜플 리스트를 생성
tshirts = [(color, size) for color in colors for size in sizes]
tshirts[('black', 'S'),
('black', 'M'),
('black', 'L'),
('white', 'S'),
('white', 'M'),
('white', 'L')]# size 먼저 반복 후, color 반복도 가능
tshirts = [(color, size) for size in sizes
for color in colors]2.2.4 제네레이터 표현식
다른 생성자에 전달할 리스트를 통째로 만들지 않고 iterator protocol(반복자 프로토콜)을 이용해서 항목을 하나씩 생성하는 제네레이터 표현식은 메모리를 더 적게 사용한다.
- listcomp.와 동일한 구문. 대괄호 대신 괄호로만 해주면 됨.
tuple_l = [ord(s) for s in chars]
print(tuple_l)[43, 41, 40, 42, 38, 94, 37, 36, 35, 64, 33, 41]-> 이걸 제네레이터 표현식으로 바꿔보자.
예제 2.5
tuple_g = (ord(s) for s in chars)
print(tuple_g)
print(type(tuple_g))
print('=='*10)
print(next(tuple_g))
print(next(tuple_g))
print(next(tuple_g))
print(next(tuple_g))
print(next(tuple_g))
print(next(tuple_g))
print(next(tuple_g))<generator object <genexpr> at 0x110a692e0>
<class 'generator'>
====================
43
41
40
42
38
94
37import array
array_g = array.array('I', (ord(s) for s in chars))
print(array_g)
print(type(array_g))
print(array_g.tolist()) # 왜 리스트로 바꾸면 'I'는 날라갈까?array('I', [43, 41, 40, 42, 38, 94, 37, 36, 35, 64, 33, 41])
<class 'array.array'>
[43, 41, 40, 42, 38, 94, 37, 36, 35, 64, 33, 41]예제 2.6
colors = ['black', 'white']
sizes = list('SML')
tshirts = (f'{color} {size}' for color in colors for size in sizes)
for tshirt in tshirts:
print(tshirt)black S
black M
black L
white S
white M
white L~~ object is not subscriptable
tshirts[1]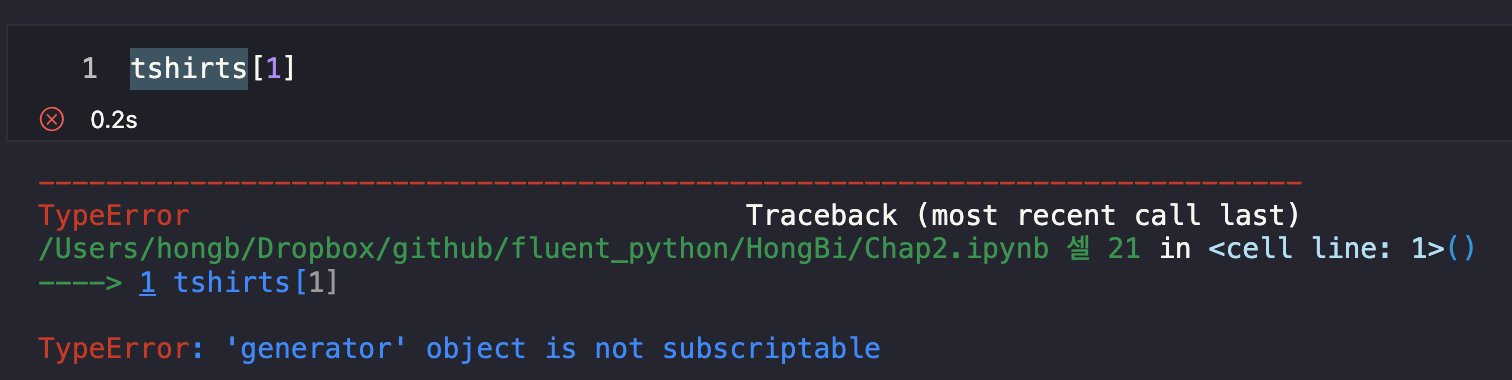
- Python 객체가 "subscriptable"하다
-> getitem() 메서드가 구현되어 있는, "컨테이너" 객체인 것 => 그럼 generator에는 getitem이 없을까?


단아와라라