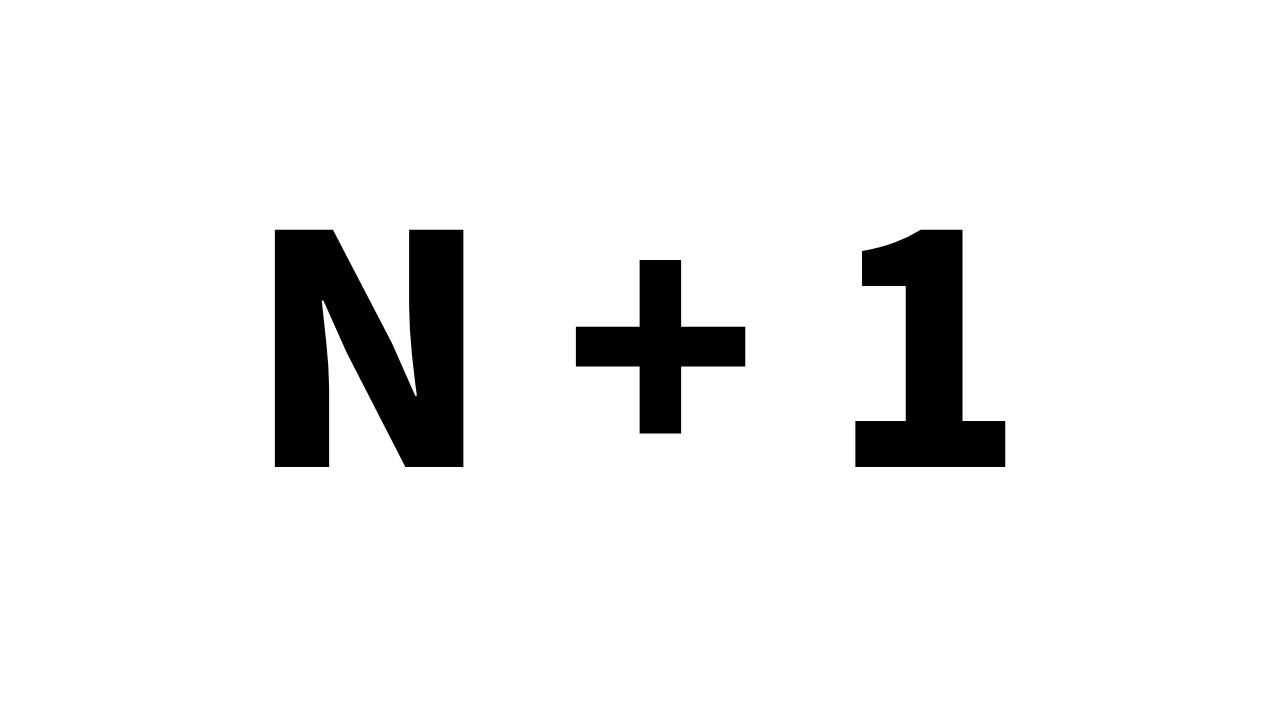
EverGreen 서버는 집에 있는 휴대폰으로 구현 할 예정이다.
휴대폰에 SD카드가 삽입되어 있어 저장공간은 문제 없지만, 오래되어 성능 문제가 있다.
그렇기 때문에 불필요한 쿼리를 최소화 해야한다고 판단했다.
1. N+1 문제 발생
1-1. N+1 문제란
N+1 문제란, JOIN 을 이용하지 않은 1개의 SELECT 쿼리 + 연관관계에 있는 데이터를 조회하기 위한 N개의 SELECT 쿼리로 총 N+1 개의 SELECT 쿼리가 발생하는 문제를 말한다.
1-2. 불필요한 쿼리 발생
PrayTitle 을 수정하기 위해 prayTitleRepository.findByUser(user)를 수행하는 경우 불필요한 쿼리가 발생하는 것이 확인된다.
User가 @ManyToOne으로 연관되어 있기 때문에 하나의 user가 조회되었다.
지금은 연관 엔터티가 하나밖에 없지만 않지만 추후 연관관계가 추가된다면 계속해서 쿼리가 추가될 것이고, 그 때문에 성능 저하가 발생하게 될 것이다.
쿼리
Hibernate: --> user로 PrayTitle 조회
/* <criteria> */ select
pt1_0.id,
pt1_0.contents,
pt1_0.nickname,
pt1_0.user
from
praytitle pt1_0
where
pt1_0.user=?
Hibernate: --> 연관관계에 있는 user가 함께 조회됨
select
null,
u1_0.email,
u1_0.image,
u1_0.nickname,
u1_0.password,
u1_0.role
from
user u1_0
where
u1_0.kakao_id=?
Entity
@Entity
@Table(name = "praytitle")
public class PrayTitle {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
private Long id;
@Column
private String nickname;
@Column(length = 5000)
private String contents;
@ManyToOne
@JoinColumn(name = "user")
private User user;
...
}2. N+1 해결 방안
N+1 문제를 해결하는 방법은 3가지가 있다.
2-1. Batch Size 조절
Batch Size 조절이란, N개의 쿼리가 너무 많기 때문에 특정 개수로 묶어 In Query 를 날려서 쿼리의 개수를 줄여주는 것이다.
이것은 사실 N+1 문제를 근본적으로 해결하는 것은 아니다.
또한 현재는 2개의 쿼리를 1개로 줄이려는 노력이기에 적절하지 않다.
하지만 내가 놓친 부분에 대해서 최소한의 방어책(불상사를 피하는...)이 되어줄 수 있기에 옵션을 설정은 해놓자.
Batch Size 설정
application.properties 에
spring.jpa.properties.hibernate.defalt_batch_fetch_size= 10 을 설정하여 Batch Size를 조절 할 수 있다..
2-2. Fetch Join
Fetch Join 은 JPA 에서 지원하는 JOIN 방식이다.
연관관계에 있는 Entity 까지 한번에 조회해 영속화해준다.
Fetch Join 구현
JPQL 로 JOIN FETCH 구문을 사용해 구현할 수 있다.
(JPA 뿐만 아니라 QueryDSL 에서도 Fetch Join 을 위한 메소드를 제공)
구현해야하는 쿼리를 말로 설명해보자면,
"pt을 PrayTitle에서 조회하는데, pt의 user를 FETCH JOIN 한다."
(prayTitle과 PrayTitle이 헷갈릴까봐 pt로 alias를 사용했다.)
public interface PrayTitleRepository extends JpaRepository<PrayTitle, Long> {
@Query("SELECT pt FROM PrayTitle pt JOIN FETCH pt.user WHERE pt.user = :user")
Optional<PrayTitle> findByUserWithFetchJoin(@Param("user") User user);
}이 때 user는 @Param 으로 값을 받아와서 넘겨주었다.
Fetch Join 결과
PrayTitle 조회시 쿼리가 하나로 줄어든 것을 확인할 수 있다.
Hibernate:
/* SELECT
prayTitle
FROM
PrayTitle prayTitle
JOIN
FETCH
prayTitle.user
WHERE
prayTitle.user = :user */ select
pt1_0.id,
pt1_0.contents,
pt1_0.nickname,
u1_0.kakao_id,
u1_0.email,
u1_0.image,
u1_0.nickname,
u1_0.password,
u1_0.role
from
praytitle pt1_0
join
user u1_0
on u1_0.kakao_id=pt1_0.user
where
u1_0.kakao_id=?2-3. EntityGraph
@EntityGraph 는 JPA에서 제공하는 어노테이션으로, 쿼리를 실행할 때 특정 연관된 엔티티를 함께 로드하도록 설정한다. (Eager Loading)
(해당 Entity 의 연관관계에 대한 정보를 넣어주는 것이다.)
EntityGraph 구현
attributePaths 속성은 함께 로드할 속성을 지정한다.
따라서 PrayTitle 엔티티와 연관된 User 엔티티를 한 번의 쿼리로 함께 로드하는 것이다.
public interface PrayTitleRepository extends JpaRepository<PrayTitle, Long> {
@EntityGraph(attributePaths = {"user"})
Optional<PrayTitle> findByUser(@Param("user") User user);
}EntityGraph 결과
@EntityGraph 를 이용하는 경우 꼭 기억해야할 것은 Outer Join 이 발생한다는 것이다. (Left Join 은 Left Outer Join 의 약자이다.)
Outer Join 특성상 상황에 따라 중복 데이터가 나올 수 있는데,
그런 경우에는 Set<> 자료구조를 사용하거나 distinct 키워드를 통해 중복을 제거할 수 있다.
(PrayTitle 에서 User 는 @ManyToOne 이기에 적용의 여지는 없다.)
Hibernate:
/* <criteria> */ select
pt1_0.id,
pt1_0.contents,
pt1_0.nickname,
u1_0.kakao_id,
u1_0.email,
u1_0.image,
u1_0.nickname,
u1_0.password,
u1_0.role
from
praytitle pt1_0
left join
user u1_0
on u1_0.kakao_id=pt1_0.user
where
pt1_0.user=?3. 선택
1번의 Batch Size 조절은 근본적인 해결책도 아니고 현재 프로젝트와 같은 적은 수의 쿼리에 적합한 것은 아니다.
3번의 @EntityGraph 는 연관관계가 복잡해질 경우 복잡도가 급증하는 문제도 존재한다.
따라서 2번의 Fetch Join 를 선택하여 쿼리를 줄였다.
현재는 2개의 쿼리를 1개로 줄인 것 뿐이기에 유의미한 성능 차이는 없겠지만 앞으로 연관 엔터티가 추가되는 경우에는 N+1 문제로 인한 성능 저하를 막아줄 것이다.
