서버에 대해 공부하다보면 "고가용성"라는 단어를 보게 된다.
이것이 의미하는바는 무엇이며, 이것을 만드는 방법은 어떤 것이 있을까?
고가용성
고가용성 (High Availability, HA)이란, IT 시스템이 다운타임을 제거하거나 최소화하여 거의 100% 상시 액세스 가능하고 신뢰성을 유지하는 능력이다.
말 그대로 높은 가용성을 확보한 상태를 의미하는 것이다.
그럼 가용성이란 정확히 어떤것을 의미하는걸까?
가용성
가용성이란, 정체 서비스 운영 중 서비스가 정상적으로 동작하는 비율이 얼마나 되는지 시간 측면의 관점으로 설명하는 지표이다.
100일을 운영한 서비스가 총 1일간 제대로 동작하지 않았다면, 이 서비스의 가용성은 99%이며 수식으로 나타내면 아래와 같다.
(uptime: 이용 가능 시간, downtime: 이용 불가 시간)
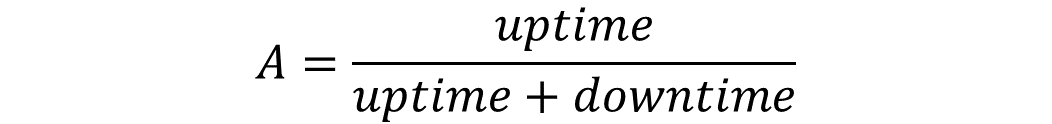
고가용성의 필요성
가용성이 95%인 시스템을 예로 들어보자.
수식에 대입하면 하루 24시간 중, 무려 1.2시간의 downtime이 발생하는 것이다.
만약 네이버가 하루 중 1.2시간동안 먹통이 되었다고 한다면 마음이 급한 한국인들이 가만 있을리가 없다. 금전적으로나 이미지 등 여러 분야에 큰 타격이 있을 것이다.
바로 이것이 앞선 정의에서 100%를 고가용성이라고 언급한 이유이다.
가용성 증대를 위한 설계 방법
고가용성 설계는 단일 장애 지점을 식별하고 제거하는 것에 의해 좌우된다.
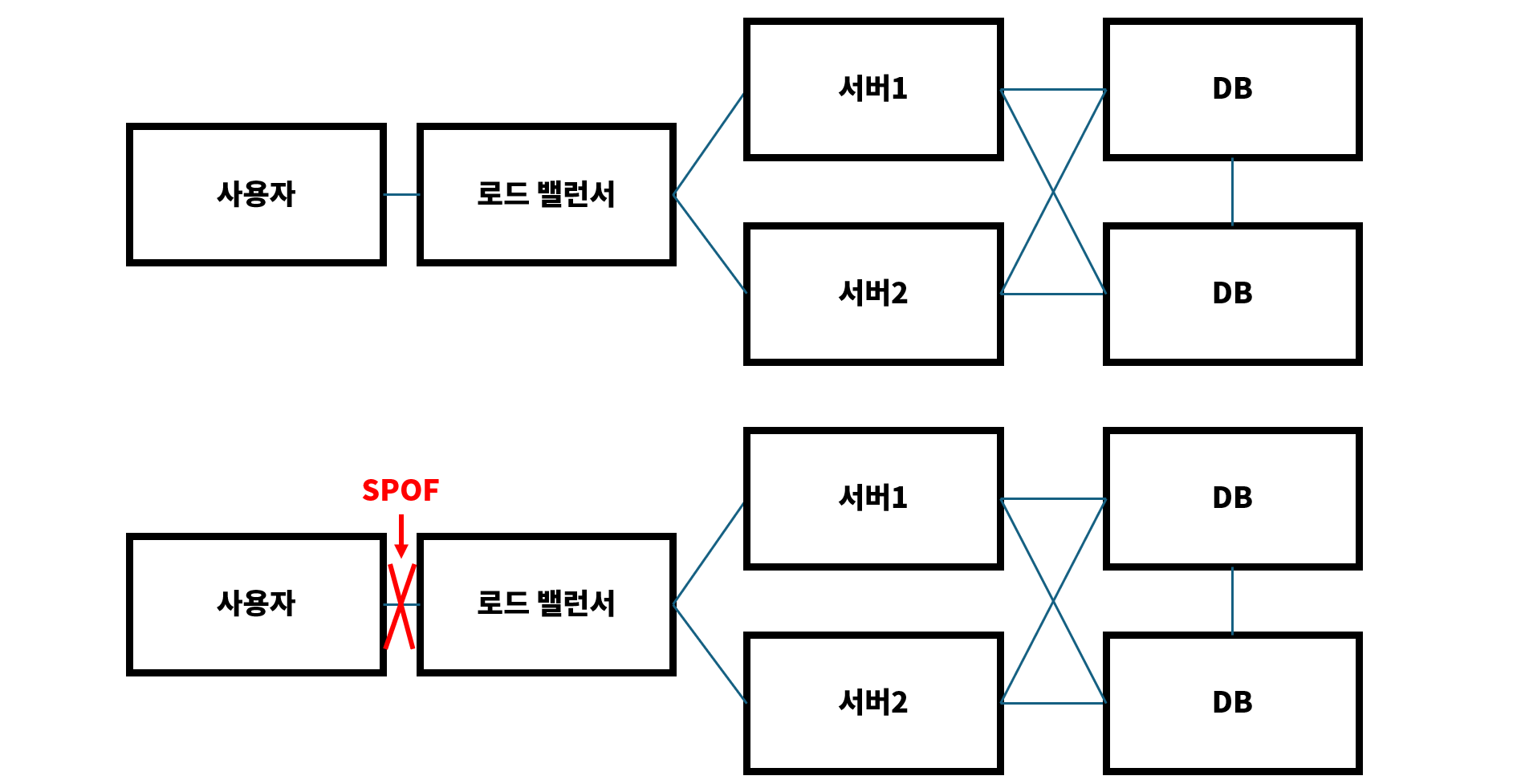
단일 장애 지점
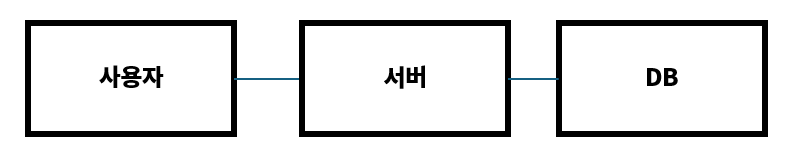
단일 장애 지점(Single Point of Failure, SPOF)이란, 시스템의 한 부분이 실패하면 전체 시스템이 영향을 받는 상황을 의미한다.
아래의 그림을 보면 이해가 빠를 것이다.
만약 SPOF가 하나라도 발생한다면 시스템 전체가 이용 불능 상태가 된다.
그림에서 SPOF는 모든 지점이 될 수 있다.
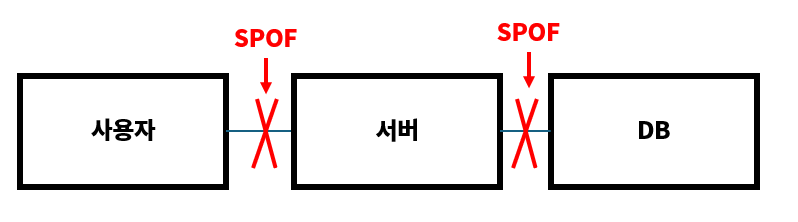
그렇다면 SPOF를 제거하여 가용성을 높이려면 어떻게 해야하는지 2가지 방법 소개하고자 한다.
1. 다중 영역 아키텍처 설계
우선 아키텍처 측면에선 SPOF가 되는 지점을 다중화 시키면 가용성을 높일 수 있다.
아래의 그림과 같이, 한 부분이 장애가 생겨도 다른 방법으로 요청을 처리 할 수 있게 된다.
2. 과부하 발생 시 단계적으로 서비스 수준 저하
두번쨰로는 과부하에 의해 서버가 죽는 상황이 발생하지 않도록... 과부하를 허용하도록 서비스를 설계해야한다.
과부하가 감지되면 사용자에게 낮은 품질의 응답을 반환하거나, 트래픽을 부분적으로 삭제해야 한다.
예를 들어 서비스에서 정적 웹 페이지를 통해 사용자 요청에 응답하고 처리하는 데 비용이 많이 드는 동적 동작을 일시적으로 사용 중지할 수 있다.
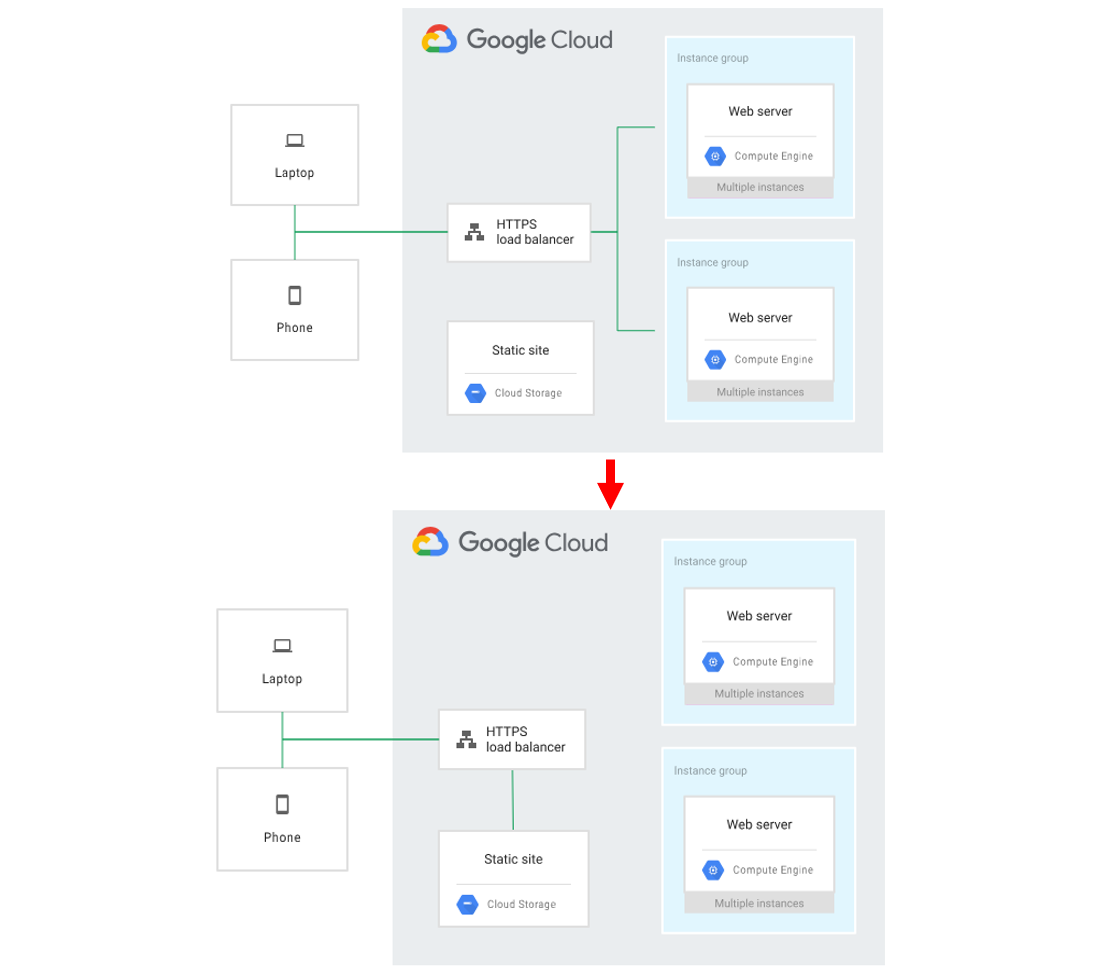
위의 그림과 같은 환경에서 과부하가 감지된다면, Cloud Storage로 트래픽을 보내도록 부하 분산기 구성을 업데이트하는 것이다.
이 외에도 트래픽 급증을 방지하고 완하는 방법은 다양하며 (큐에 추가, 부하 차단, 회로 차단, 중요 요청 우선순위 지정), 장애 이후 재해 복구 능력(복원력) 또한 중요하다.
다음에는 재해 복구에 대해 포스팅 해보고자 한다.
출처
