[리뷰]LORA: LOW-RANK ADAPTATION OF LARGE LANGUAGE MODELS
LORA: LOW-RANK ADAPTATION OF LARGE LANGUAGE MODELS 논문을 읽고 내용을 정리하였습니다.
0. Abstrct
대규모의 모델을 사전 학습시킬수록, 모든 모델의 파라미터를 재학습 시키는 Full Fine-tunning은 어려워진다. 따라서 LoRA(Low-Rank Adaptation)를 제안하는데, LoRA는 사전 학습된 모델의 가중치를 고정하고, 트랜스포머 아키텍처의 각 계층에 행렬을 삽입하여 downstream 작업에 필요한 학습 가능한 파라미터의 수를 줄일 수 있다.
1. Introduction
큰 모델일 수록 사전 학습 후에 finetunning시 많은 파라미터를 학습시켜야하기 때문에 시간 및 비용 측면에서 비효율적이다. Model을 GPU에 Load하고, fine-tunning 및 optimizer를 위한 저장 등에 모델의 weight수의 2,3배의 GPU vram이 필요하다. 일부 파라미터만 업데이트 하는 경우에도 inference latency가 발생하고 모델의 성능이 저하되는 경우도 흔했다. 이렇듯 시간이나 자원에 대한 비용이 많고 성능 저하도 발생할 수 있기 때문에 많은 파라미터를 가지는 모델을 실제로는 저차원에 두고 저차원의 instrinsic rank를 이용하여 fine-tunning하는 방법인 LoRA를 제시한다. 이는 사전에 학습한 모델의 weight는 업데이트 하지 않고, LoRA의 rank decomposition의 weight만 업데이트하는 것이다.
장점
- 사전 학습된 모델을 공유하고 다양한 작업을 위한 여러 작은 LoRA 모듈을 구축할 수 있다. 공유된 모델은 고정하고, fine tunning할 모델만 효율적으로 전환할 수 있어서 저장 요구 사항과 작업 전환 오버헤드를 크게 줄일 수 있다.
- LoRA는 훈련을 더 효율적으로 만들고 하드웨어 진입 장벽을 최대 3배 낮춘다. gradient를 계산하거나 optimizer 상태를 유지할 필요가 없기 때문에 훨씬 작은 크기의 저순위 행렬을 가질 수 있다.
- 설계가 단순하기 때문에 고정된 가중치와 합산할 수 있고, 파인튜닝된 모델에 비해 추론 지연이 발생하지 않는다.
2. PROBLEM STATEMENT
기존에는 아래와 같은 수식을 사용하여 업데이트했는데, 이 수식은 업데이트가 사전 학습에도 적용되고, fine-tunning 시에도 전체 파라미터 모두를 업데이트 한다.
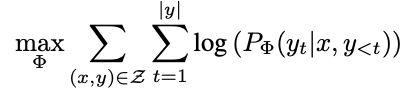
따라서 본 논문에서는 각 downstream task마다 다른 LoRA layer를 사용해 효율적으로 파라미터를 업데이트를 제안한다.
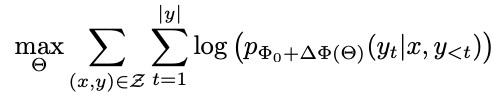
3. Aren't Existing Solutions Good Enough?
본 논문에서도 문제 해결을 위해 두 가지의 방법을 생각했었다.
Adding adapter layers
- Adapter라는 Layer를 transformer block에 추가해서 일부분만 학습 방식
- 추가적인 컴퓨팅 작업이 들어간다.
Optimizing some forms of the input layer activations
- 프롬프트 임베딩 방식
- 최적화가 어려우며 성능이 향상되지 않고 횡보하는 경우가 있다.
4. OUR METHOD
4.1 LOW-RANK-PARAMETRIZED UPDATE MATRICES
신경망의 많은 레이어들은 행렬의 곱으로 되어있는데 모든 사전학습된 모델은 더 작은 subspace로의 랜덤 projection에도 불구하고 low intrinsic rank를 가질 수 있다.
- adapter-based : 추가적으로 MLP 레이어를 학습해야 한다.
- prefix-based : input에 prompt embedding을 추가해야하기 때문에 long input sequences 추가하는데 한계가 있다.
4.2 APPLYING LORA TO TRANSFORMER
학습 가능한 파라미터의 수를 줄이기 위해 신경망에서 가중치 행렬의 모든 부분집합에 LoRA를 적용할 수 있다.
실질적인 이점과 한계
- 메모리와 저장 공간을 효율적으로 사용할 수 있다.
- 다른 downstream task를 진행할 때마다 다른 AB 매트릭스를 사용해야 한다.
5. Empirical Experiments
생략
6. RELATED WORKS
- Transformer Language Models.
- Parameter-Efficient Adaptation.
- Prompt Engineering and Fine-Tuning.
- Low-Rank Structures in Deep Learning.
7. CONCLUSION AND FUTURE WORK
- LLM을 fine-tunning하는 것은 시간과 비용이 많이 든다.
앞으로의 과제
- LoRA는 다른 효율적인 adaptation 방법들과 결합할 수 있고 앞으로의 개선의 가능성
- Fine-tunning이나 LoRA의 불분명한 작동원리
- LoRA에 적용할 가중치 행렬을 결정하는 기준이 모호함
- Δ W 의 rank 축소가 가능하다면 W 도 rank를 축소해도 되지 않을까 하는 의문
참고
https://openreview.net/pdf?id=nZeVKeeFYf9
https://openreview.net/forum?id=nZeVKeeFYf9
