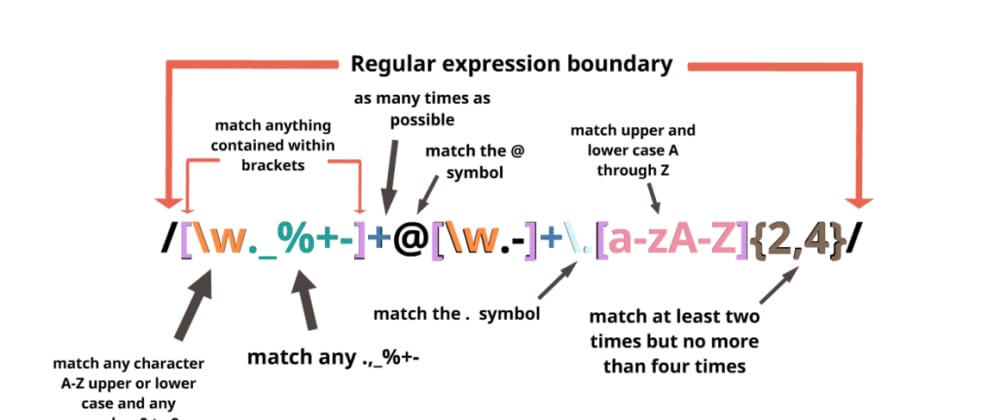
regular expression cheet sheet
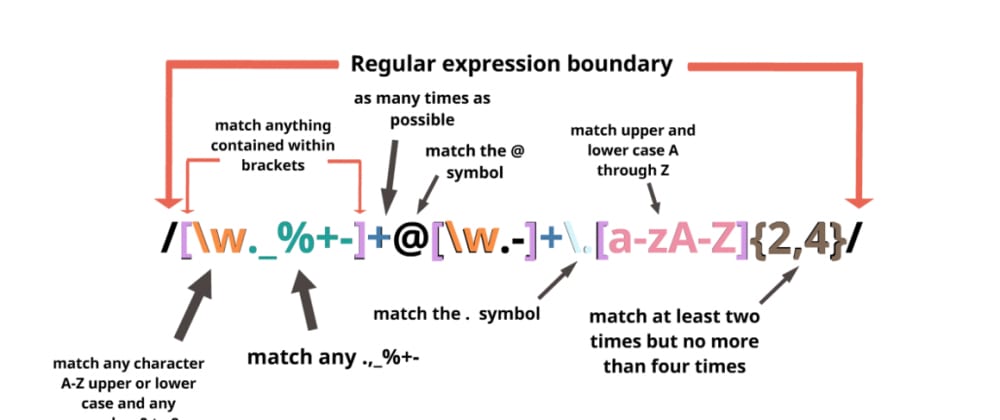
정규표현식 기호 모음
^ | Matches the beginning of a line |
$ | Matches the end of the line |
. | Matches any character |
\s | Matches whitespace |
\S | Matches any non-whitespace character |
* | Repeats a character zero or more times |
*? | Repeats a character zero or more times (non-greedy) |
+ | Repeats a character one or more times |
+? | Repeats a character one or more times (non-greedy) |
[aeiou] | Matches a single character in the listed set |
[^XYZ] | Matches a single character not in the listed set |
[a-z0-9] | The set of characters can include a range |
( | Indicates where string extraction is to start |
) | Indicates where string extraction is to end |
Greedy Match
Regular Expression을 통해 문자열 매칭시 가능한 매칭중 더 많은 문자가 포함되는 쪽으로 결과가 반환된다.
import re
x = 'From: Using the : character'
y = re.findall('^F.+:', x)
print(y)
> ['From: Using the :']참고 링크
https://www.py4e.com/lectures3/Pythonlearn-11-Regex-Handout.txt
더 자세한 정보
https://docs.python.org/3/howto/regex.html
