
확률적 경사 하강법(SGD)은 많은 머신러닝 알고리즘에서 사용되는 최적화 기법 중 하나입니다. 이 포스트에서는 SGD에서 데이터를 섞는 것이 왜 중요한지에 대해 설명하겠습니다.
1. 순서 의존성
- 데이터가 특정 순서로 정렬되어 있으면, 이 순서가 학습 과정에 반영될 수 있습니다. 예를 들어, 고양이와 개의 이미지가 섞이지 않고 차례대로 정렬되어 있다면, 모델은 고양이만 학습한 후 개만 학습하게 됩니다.
- 이로 인해 모델은 데이터의 순서에 과도하게 의존하게 되며, 새로운 순서의 데이터에 대한 일반화가 어려워질 수 있습니다.
- 이러한 순서 의존성은 과적합을 초래하고, 모델의 예측 성능을 저하시킬 수 있습니다.
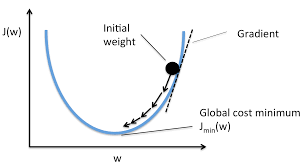
2. 지역 최소값에 갇히기 쉬움
- 데이터의 순서가 항상 동일하면, 알고리즘이 특정 지역 최소값에 갇힐 가능성이 높아집니다.
- 특정 패턴이 연속으로 나타나면, 그 지역의 최소값에 수렴하게 되어 전역 최적해를 찾지 못할 수 있습니다.
- 데이터를 섞는 것은 이러한 문제를 완화하고, 알고리즘이 전역 최적해를 찾을 수 있도록 돕습니다.
3. 수렴 속도
- 일정한 순서로 학습할 경우, 동일한 샘플 패턴이 계속 반복되어, 수렴 속도가 느려질 수 있습니다.
- 동일한 패턴의 반복은 알고리즘이 새로운 정보나 패턴을 학습하기 어려워질 수 있게 만듭니다.
- 데이터를 섞으면 이러한 반복성이 줄어들고, 알고리즘이 더 빠르게 수렴하고 다양한 패턴을 학습할 수 있습니다.
4. 온라인 학습과 미니배치
- 미니배치 학습에서 동일한 배치 순서로 항상 학습하면, 모델은 특정 배치의 패턴에 과도하게 적응할 수 있습니다.
- 다른 배치에서의 일반화가 어려워지며, 일부 배치에 과적합되는 문제가 발생할 수 있습니다.
- 데이터를 섞는 것은 배치 간의 다양성을 증가시키고, 모델이 전체 데이터 분포를 더 잘 학습하게 만듭니다.
결론
데이터를 섞는 것은 SGD와 같은 확률적 학습 알고리즘에서 중요한 단계입니다. 이를 통해 알고리즘이 더 효과적으로 수렴하고, 과적합을 피하며, 복잡한 패턴을 더 잘 학습할 수 있도록 돕습니다.

공감하며 읽었습니다. 좋은 글 감사드립니다.