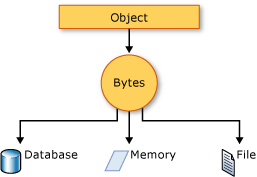
직렬 이라는 단어는 살면서도 많이 들어봤다.
CS에서 직렬을 말하면 가장 먼저 떠오르는 것은 CPU이다. CPU는 코어에서 순차적으로 데이터를 처리하기에 데이터를 직렬로 입력 받고 출력한다. 프로그래밍에서도 이와 같은 모습일 지 알아보자.
직렬화(Serialization)
직렬화는 이전 XML과 JSON 글에서도 간단하게 작성했었는데 여기서 개념부터 다시 짚어보자.
개념
- 객체를 다른 컴퓨터로 전송하거나 저장하기 위해 알맞은 형태로 변환하는 기술
→ 데이터를 저장하거나 통신에서 전송하기 위해 사용하는 형식으로 변환하는 것.
역직렬화(Deserializable)
직렬화가 기존 데이터를 알맞게 변환하는 거였으니 역직렬화는 예측이 간다. 개념부터 보자.
개념
- 저장과 통신에 맞는 형태로 변환되어 있는 데이터를 원래의 형태로 변환하는 기술.
→ 저장되거나 통신 등으로 전달받은 데이터를 원래의 형태로 되돌리는 것.
필요한 이유
사실 간단하게 생각해보면 바이트 스트림 변환 없이 그냥 전송해도 될 것 같다. 당장 우리가 알아보기 편할 것 같기도 하고 결국 모두 비트 단위로 되어있는데 말이다.
데이터의 메모리 구조
이 때 우리가 알고 넘어가야 하는 것이 데이터가 메모리에 저장 되는 형식이다.
- 값 형식 데이터
- int, float 처럼 우리가 프로그래밍 할 때 사용하는 자료형으로 선언하는 데이터이다. 이 데이터는 스택에 메모리가 쌓이고 직접 접근이 가능하다.
- 참조 형식 데이터
- 객체와 같은 참조 형식 변수는 힙에 메모리가 할당, 스택은 이 메모리를 참조하는 구조로 되어있다.
여기서 문제가 되는 것은 참조 형식 데이터이다. 참조형식 데이터는 스택에 실제 데이터가 아니라 참조하는 위치의 주소를 가지고 있다.
→ 주소값을 가지고 있다는 것은 해당 데이터를 그대로 저장한다 하더라도 실제 데이터를 저장하지 못한다는 뜻이다. 참조되는 주소는 실행 시마다 바뀔 수 있기 때문이다.
이 때 직렬화는 참조 데이터의 값도 모두 끌어와서 값 형식 데이터로 변환한다. 이런 데이터를 텍스트나 바이너리 형태로 변환하게 되면 저장이나 통신 시 유의미한 데이터를 사용할 수 있게 된다.
→ 직렬화는 유의미한 데이터를 만들기 위해 사용하고 역직렬화는 이렇게 받은 데이터를 원래대로 돌리기 위한 것이다.
직렬화의 종류
- CSV, XML, JSON 의 직렬화
- 사람이 읽을 수 있는 형태.
- 셋 모두 텍스트 기반이기에 저장 공간의 효율성이 떨어지고 파싱에 시간이 걸린다.
- 데이터 양 자체가 적을 때 사용한다.
- 최근엔 JSON을 통신에 많이 사용함에 따라 JSON 형태의 직렬화를 많이 한다.
- 텍스트 기반이기에 모든 시스템에서 사용 가능하다.
- Binary 직렬화
- 0과 1로 이뤄져 있어 사람이 읽을 수 없다.
- 저장공간에 효율적이고 파싱 시간이 빠르다.
- 데이터가 많을 때 주로 사용한다.
- 마찬가지로 모든 시스템에서 사용 가능하다. ex) 프로토콜 버퍼, Apache avro 아파치 아브로: 아파치에서 만든 프레임워크로 데이터 직렬화 기능을 제공한다.
그럼 자바에선?
앞으로 백엔드를 공부하며 자바도 같이 공부를 하기도 하고 앞서 Spring에 대해서 쓰기도 했으니 자바를 뻬고 이야기 할 순 없다. 하지만 자바의 직렬화 역직렬화를 말하기 전에 알아야 하는 것이 있다.
바이트 스트림(Stream of Bytes)
-
개념
- 1Byte를 입출력 할 수 있는 스트림.
- 스트림: 클라이언트나 서버 간 출발지 목적지로 입출력하기 위한 데이터의 통로.
- 자바 같은 경우 스트림의 기본 단위를 Byte로 두고 있기 때문에 네트워크, 데이터베이스로 전송하기 위해선 바이트 스트림으로 변환하여 처리해야 한다.
- 1Byte를 입출력 할 수 있는 스트림.
-
기능
저장&전달이 가능한 데이터 생성
-
기기마다 서로 다른 메모리 주소 공간을 가질 수 있기에 참조형 데이터는 전달 불가능.
-
따라서 주소값이 아니라 데이터 자체를 바이트 형태로 직렬화 하여 전달해야 파싱 가능한 데이터가 된다.
객체 데이터를 영구저장 가능
-
JVM과 같이 메모리에만 존재하는 데이터를 시스템 종료 후에도 사라지지 않는 데이터로 저장 가능하다.
- JVM: Java virtual Machine의 줄임말로 자바가 실행되는 가상 머신.
-
-
데이터를 저장하는 수단 중 하나. Byte 단위로 데이터를 저장하거나 전송하는 것.
직렬화와 역직렬화 in Java
- 직렬화
- 자바 내부에서 사용되는 객체 또는 데이터를 외부의 자바 시스템에서도 사용할 수 있도록 바이트 스트림 형태로 데이터 변환하는 기술.
- JVM의 메모리에 상주되어 있는 객체 데이터를 바이트 형태로 변환.
- 역직렬화
- 바이트 스트림으로 변환되어 있는 데이터를 원래대로 돌리는 기술이다.
- 바이트 스트림 데이터를 객체로 변환해 JVM으로 상주시킨다.
장점
우선 직렬화를 쓰는 이유는 참조 데이터를 가져와서 유의미한 데이터를 만들기 위해서 한다고 했다. 그렇다면 자바에서 직렬화를 써서 오는 장점은 무엇일까?
- 우선 자바 시스템에서의 개발에 최적화 되어있다.
- 객체를 비롯한 복잡한 데이터 구조도 직렬화의 기본 조건만 지킨다면 별 어려움 없이 직려화, 역직렬화가 가능하다.
- 데이터 타입이 자동으로 맞춰지기 때문에 역직렬화가 되면 기존 객체처럼 바로 사용이 가능하다.
단점
- 역직렬화를 할 때 클래스 구조에 변동이 있다면 문제가 발생한다.
- InvalidClassException 예외가 뜬다.
- 엄격한 타입 체크
- 변수명이 같더라도 객체의 변수 타입이 달라지면 타입 예외가 발생한다.
- 용량 문제
- 간단한 객체의 내용도 2배 이상의 용량 차이가 난다. 일반적이 메모리 기반의 Cache에선 데이터를 저장할 수 있는 용량의 한계가 있으므로 Json과 같은 경량화된 형태로 직렬화 하는 것이 좋다.
사용처?
- 서블릿 세션
- 서블릿 메모리 위에서 운용한다면 직렬화가 필요 없지만 파일 저장, 세션 클러스터링, DB 저장 등을 하게 되면 세션 자체가 직렬화되어 전달된다.
- 캐시
- Encache, Redis, memcached 등의 라이브러레 시스템에서 캐시 할 부분을 자바 직렬화된 데이터를 저장해서 사용한다. 다른 방식도 있지만 자바 직렬화가 가장 간편하다고 한다.
- 자바RMI
- 원격 시스템 간의 메시지 교환을 위해서 사용하는 자바에서 지원하는 기술이다.
주의사항
- 외부 저장소로 저장되는 데이터는 짧은 만료시간이 아니라면 자바 직렬화 사용을 지양한다.
- 역직렬화에서 문제가 생길 수 있다는 점을 인지하고 개발한다.
- 자주 변경되는 비즈니스적인 데이터 역시 문제가 생길 수 있기에 자바 직렬화 사용을 지양한다.
- 긴 만료시간을 가지는 데이터는 JSON 등 다른 포멧을 사용하여 저장한다.
→ 결국 자바 직렬화가 객체 데이터를 그대로 저장한다는 점에서 강점이 있지만 용량을 그만큼 많이 차지하고 변경에 대해 예민하기 때문에 사용을 지양해야 한다.
결론
- 직렬화와 역직렬화는 데이터를 저장하거나 송수신하기 위해 정해진 형태(json, scv, 바이트 스트림 등)로 변환하고 다시 원래대로 돌리는 것이다.
- 자바 직렬화는 객체를 저장한다는 점에서 강점이 있지만 문제점들이 있기 때문에 사용을 지양하는 것이 좋다.
