데이터셋 확인
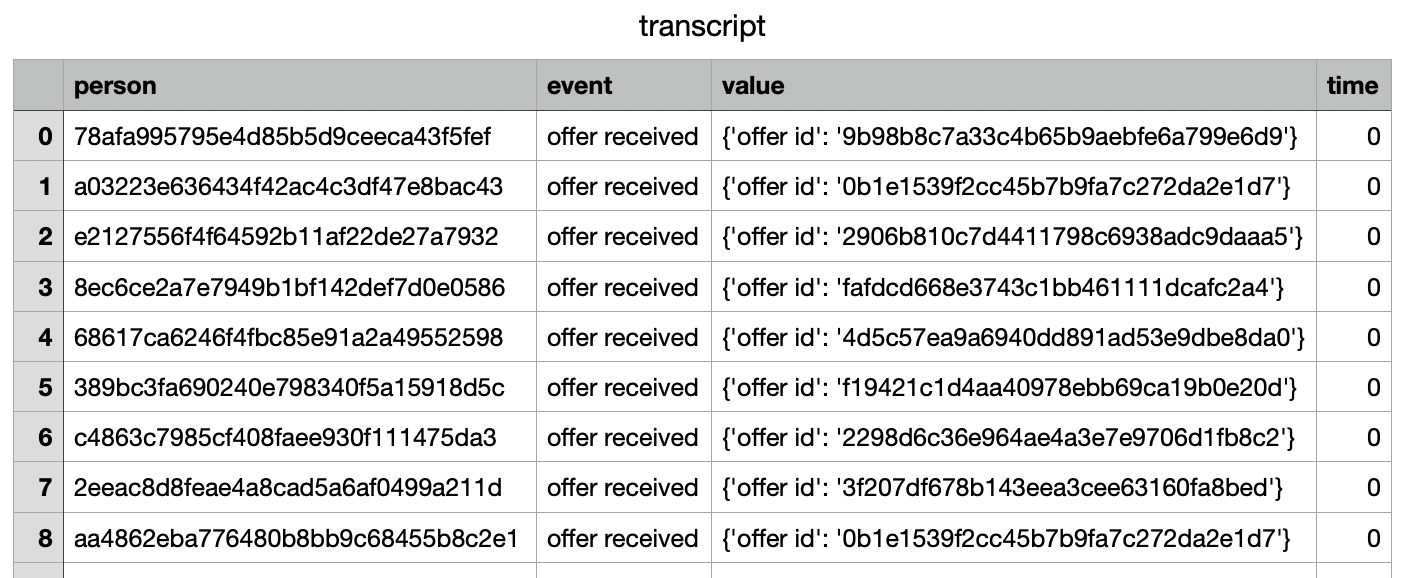
- value 컬럼을 보면 아래와 같이 묶여있는 것을 확인 할 수 있다.
이걸 풀어서 offer id 라는 새로운 컬럼을 생성해 그 안에 offer id 에 해당하는 값을 넣어줄 것이다.
{'offer id': '12345'}
- event = offer received -> offer id
event = offer viewed -> offer id
event = offer completed -> offer id , reward
event = transaction -> amount
이벤트가 뭐냐에 따라 value 컬럼에 들어있는 json 타입 데이터가 차이가 있다.
라이브러리 및 데이터 import
# 필요한 라이브러리 가져오기
import pandas as pd
import json
# CSV 파일에서 데이터를 읽어와 Pandas DataFrame에 저장
df = pd.read_csv('/Users/hj/Desktop/python1/sql_project/portfolio.csv')판다스와 json을 import 해주고,
가공할 데이터셋 불러온다.
데이터 형식 변경 및 문자열 추출
이중 따옴표 처리
Json에서 문자열은 이중따옴표로 둘러싸여 있어야 하지만, 원본 데이터는 홀따옴표로 묶여있는 걸 확인할 수 있다.
홀따옴표(') -> 이중따옴표(") 변경해야 함
replace 함수 사용
원본 json 형식 문자열
{'offer id': '12345'}변환 후
{"offer id": "12345"}JSON 로딩
json.loads(x) : 수정된 문자열 'x'를 JSON 객체로 로딩한다. 그리고 파이썬 딕셔너리 형태로 변환한다.
# JSON 문자열에서 정보를 추출하는 함수 정의
def get_offer_value(x):
x = x.replace('\'','"')
return json.loads(x)['offer id']
def get_offer_com(x):
x = x.replace('\'','"')
return json.loads(x)['offer_id']
def get_offer_com_reward(x):
x = x.replace('\'','"')
return json.loads(x)['reward']
def get_trans_value(x):
return x.replace('{\'amount\': ','').replace('}','')get_trans_value 에서는 'amount' 값을 추출하기 위함
데이터 전처리
# 'event' 열 값에 따라 다른 전처리 적용
d1 = df[df['event'] == 'offer received']['value'].apply(get_offer_value)
d2 = df[df['event'] == 'offer viewed']['value'].apply(get_offer_value)
d3 = df[df['event'] == 'offer completed']['value'].apply(get_offer_com)코드해석
df[df['event'] == 'offer received']
'event' 열이 'offer received'인 행만을 포함하는 데이터프레임 생성['value']
필터링된 데이터프레임에서 'value' 열 선택.apply(get_offer_value)
'value'열의 각 요소에 'get_offer_value' 함수를 적용.
해당 함수는 JSON 형식의 문자열에서 'offer id'를 추출
-> 'event' = 'offer received'인 행들에 대해 'value' 열에서 추출한 'offer id' 값을 포함하는 판다스 시리즈 d1 생성
d1을 실행하면 제 데이터프레임에서 'event'가 'offer received'인 행들의 'value' 열에서 추출한 'offer id' 값들이 출력됨
새로운 열 생성
# DataFrame에 처리된 데이터를 기반으로 새로운 열 생성
df['offer_id'] = pd.concat([d1, d2, d3])
df['reward'] = df[df['event'] == 'offer completed']['value'].apply(get_offer_com_reward)
df['amount'] = df[df['event'] == 'transaction']['value'].apply(get_trans_value)코드해석
df['offer_id'] = pd.concat([d1, d2, d3])
데이터프레임 df에 'offer_id' 라는 새로운 컬럼에 d1, d2, d3 를 이어 붙임.
따라서 'offer_id' 열은 'offer received' 의 value 열에서 추출한 'offer id'값들, 'offer viewed' 의 value 열에서 추출한 'offer id' 값들, 'offer completed' 의 value 열에서 추출한 'offer_id' 값들로 이루어져있다.df['reward'] = df[df['event'] == 'offer completed']['value'].apply(get_offer_com_reward)
'event' 가 'offer completed' 인 행들에 대해 'value' 열에서 'get_offer_com_reward' 함수를 적용해 reward 값을 추출하고, 그 결과를 'reward'라는 새로운 열에 추가하는 역할은 한다.
csv로 저장
# 수정된 DataFrame을 새로운 CSV 파일로 저장
df.to_csv('./transcript_prep.csv', index=False)현재 작업 디렉토리에 'transcript_prep.csv' 라는 파일이 생성됨
코드 자체는 파일을 다운로드 하지 않음.

데이터 애널리스트가 되고 싶은