
시간 데이터 전처리
시간 데이터가 timestamp형식으로 되어있으면 python을 활용해서 다양한 정보를 뽑아낼 수 있다.
ex) 시간대별, 월별, 요일별, 윤년 여부까지
데이터 종류 확인
print(type(sparta_data['access_date'][1]))
# type() 함수로 데이터 종류 확인
# [1] 데이터 확인할 위치 to_datetime() : str -> timestamp
format='%Y-%m-%dT%H:%M:%S.%f'
sparta_data['access_date_time'] = pd.to_datetime(sparta_data['access_date'], format=format)
sparta_data.tail(5)
#to_datetime() 으로 해당 열의 데이터를 날짜와 시간 데이터로 바꿔줌%Y: Year, ex) 2019, 2020
%m: Month as a zero-padded, ex) 01~12
%d: Day of the month as a zero-padded ex) 01~31
%H: Hour (24-hour clock) as a zero-padded ex) 01~23
%M: Minute as a zero-padded ex) 00~59
%S: Second as a zero-padded ex) 00~59
ex) 2019-09-01 19:30:00 =(Directivs)=> %Y-%m-%d %H:%M:%S요일별 시간별 컬럼 추가
# [날짜 컬럼].dt.day_name : 해당 날짜의 요일 가져옴
sparta_data['access_date_time_weekday'] = sparta_data['access_date_time'].dt.day_name()
# [날짜 컬럼].dt.hour : 해당 날짜의 시간 값 가져옴
sparta_data['access_date_time_hour'] = sparta_data['access_date_time'].dt.hour- 추가 함수들
df['Birth_date'] = df['Birth'].dt.date # YYYY-MM-DD(문자)
df['Birth_year'] = df['Birth'].dt.year # 연(4자리숫자)
df['Birth_month'] = df['Birth'].dt.month # 월(숫자)
df['Birth_month_name'] = df['Birth'].dt.month_name() # 월(문자)
df['Birth_day'] = df['Birth'].dt.day # 일(숫자)
df['Birth_time'] = df['Birth'].dt.time # HH:MM:SS(문자)
df['Birth_hour'] = df['Birth'].dt.hour # 시(숫자)
df['Birth_minute'] = df['Birth'].dt.minute # 분(숫자)
df['Birth_second'] = df['Birth'].dt.second # 초(숫자)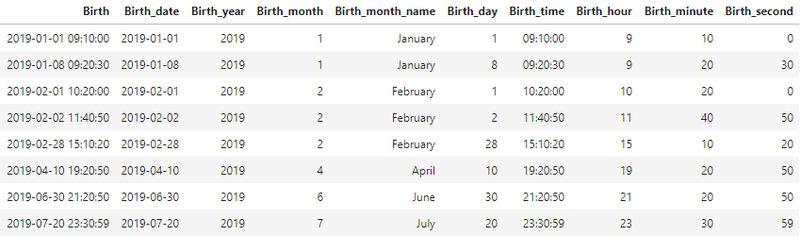
df['Birth_quarter'] = df['Birth'].dt.quarter # 분기(숫자)
df['Birth_weekday_name'] = df['Birth'].dt.weekday_name # 요일이름(문자) (=day_name())
df['Birth_weekday'] = df['Birth'].dt.weekday # 요일숫자(0-월, 1-화) (=dayofweek)
df['Birth_weekofyear'] = df['Birth'].dt.weekofyear # 연 기준 몇주째(숫자) (=week)
df['Birth_dayofyear'] = df['Birth'].dt.dayofyear # 연 기준 몇일째(숫자)
df['Birth_days_in_month'] = df['Birth'].dt.days_in_month # 월 일수(숫자) (=daysinmonth)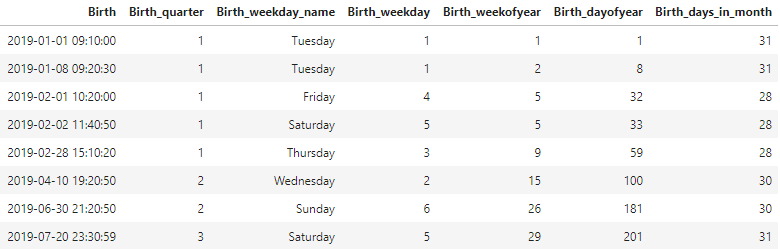
df['Birth_is_leap_year'] = df['Birth'].dt.is_leap_year # 윤년 여부
df['Birth_is_month_start'] = df['Birth'].dt.is_month_start # 월 시작일 여부
df['Birth_is_month_end'] = df['Birth'].dt.is_month_end # 월 마지막일 여부
df['Birth_is_quarter_start'] = df['Birth'].dt.is_quarter_start # 분기 시작일 여부
df['Birth_is_quarter_end'] = df['Birth'].dt.is_quarter_end # 분기 마지막일 여부
df['Birth_is_year_start'] = df['Birth'].dt.is_year_start # 연 시작일 여부
df['Birth_is_year_end'] = df['Birth'].dt.is_year_end # 연 마지막일 여부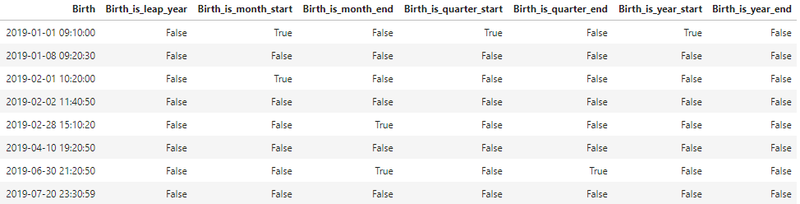
요일 별 시간 별 접속한 수강생 수 구하기
- 요일 별
weeks = ['Monday', 'Tuesday', 'Wednesday', 'Thursday', 'Friday', 'Saturday', 'Sunday']
weekdata = sparta_data.groupby('access_date_time_weekday')['user_id'].count()
weekdata = weekdata.agg(weeks)
weekdata
#week의 리스트에 따라 데이터들을 다시한번 재배열 할수 있어요! 요일 순 정렬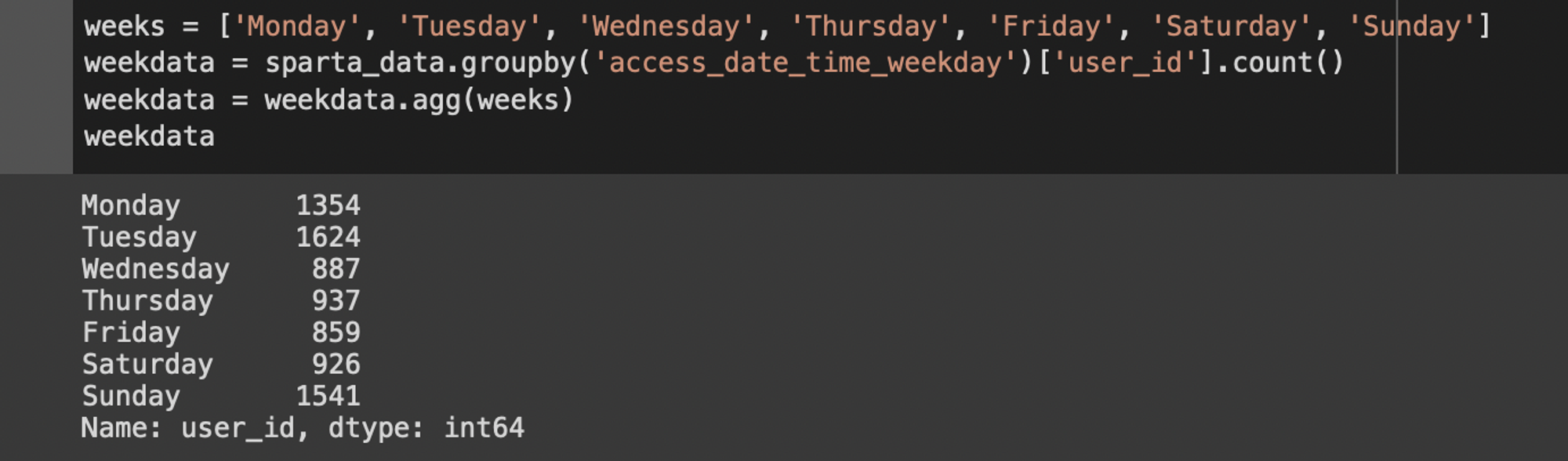
- 시간 별
hourdata = sparta_data.groupby('access_date_time_hour')['user_id'].count()
hourdata = hourdata.sort_index()
hourdata
# sort_index() : 오름차순
# sort_index(ascending=False) : 내림차순가장 적절한 고객 관리 타이밍 분석 및 시각화
- 요일별 수강생 수 바 그래프 그리기
#그래프 사이즈
plt.figure(figsize=(10,5))
#그래프 x축 y축
plt.bar(weekdata.index, weekdata)
#그래프 명
plt.title('요일별 수강 완료 수강생 수')
#그래프 x축 레이블
plt.xlabel('요일')
#그래프 y축 레이블
plt.ylabel('수강생(명)')
#x축 레이블을 90도로 변환
plt.xticks(rotation=90)
#그래프 출력
plt.show()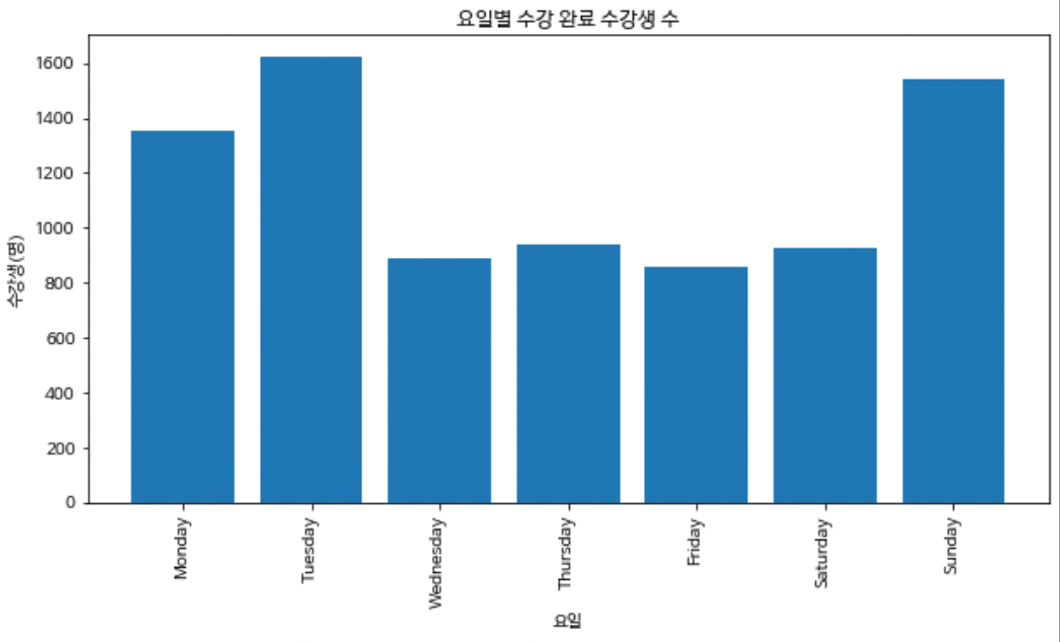
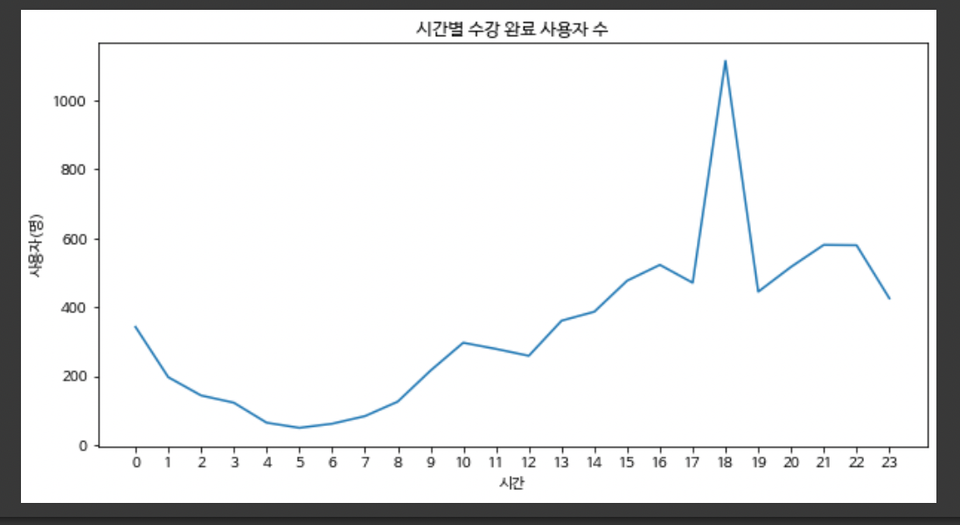
- 시간 별 접속하는 수강생 수 라인 그래프
#그래프 사이즈 변경
plt.figure(figsize=(10,5))
#그래프 x축 y축
plt.plot(hourdata.index, hourdata)
#그래프 명
plt.title('시간별 수강 완료 사용자 수')
#그래프 x축 레이블
plt.xlabel('시간')
#그래프 y축 레이블
plt.ylabel('사용자(명)')
#x축 눈금 표시 하기
plt.xticks(np.arange(24))
#그래프 출력
plt.show()np.arange :
numpy 모듈의 arrange 함수는 반열린구간 [start, stop] 에서 step의 크기만큼 일정하게 떨어져 있는 숫자들을 array 형태로 반환해주는 함수.
stop 매개변수의 값은 반드시 전달되어야 하지만 start, step은 꼭 전달되지 않아도 됨.
start 값이 전달되지 않았다면 0을 기본값으로 가지고, step 값이 지정 안됐다면 1 을 기본값으로 가짐.
ex)
np.arange(3)
array([0, 1, 2])
히트맵으로 나타내기
히트맵이란?
x축과 y축을 특정하게 제한된 변수로 설정하고 균일한 블록으로 나누어 각 칸에 수치형 변수를 채우는 방식
데이터 값이 높거나 양이 많은 경우 진한색을,
낮거나 적은 경우 연한 색을 사용하여 시각적 패턴을 만듦
#피벗테이블 만들기
#values : 열에 들어 가는 부분
#index : 행에 들어가는 부분
#aggfunc : 데이터 축약시 사용할 함수
sparta_data_pivot_table = pd.pivot_table(sparta_data, values='user_id',
index=['access_date_time_weekday'],
columns=['access_date_time_hour'],
aggfunc="count").agg(weeks)
sparta_data_pivot_table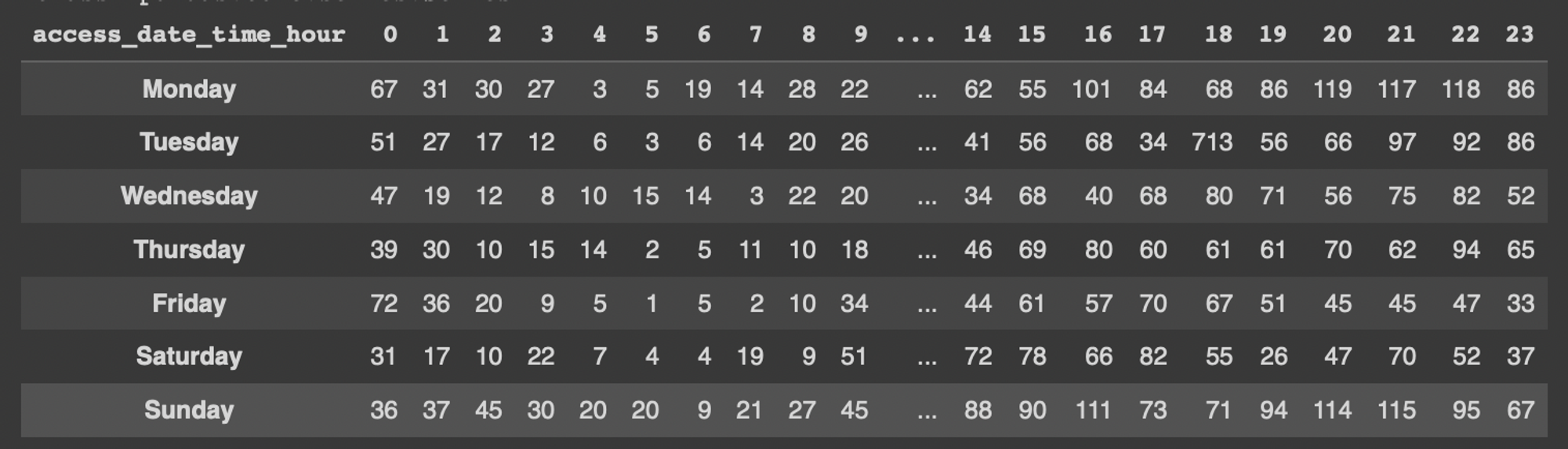
#그래프 사이즈 변경
plt.figure(figsize=(14,5))
#pcolor를 이용하여 heatmap 그리기
plt.pcolor(sparta_data_pivot_table)
#히트맵에서의 x축
plt.xticks(np.arange(0.5, len(sparta_data_pivot_table.columns), 1), sparta_data_pivot_table.columns)
#히트맵에서의 y축
plt.yticks(np.arange(0.5, len(sparta_data_pivot_table.index), 1), sparta_data_pivot_table.index)
#그래프 명
plt.title('요일별 종료 시간 히트맵')
#그래프 x축 레이블
plt.xlabel('시간')
#그래프 y축 레이블
plt.ylabel('요일')
#plt.colorbar() 명령어를 추가하면 그래프 옆에 숫자별 색상값을 나타내는 컬러바를 보여 줍니다
plt.colorbar()
plt.show()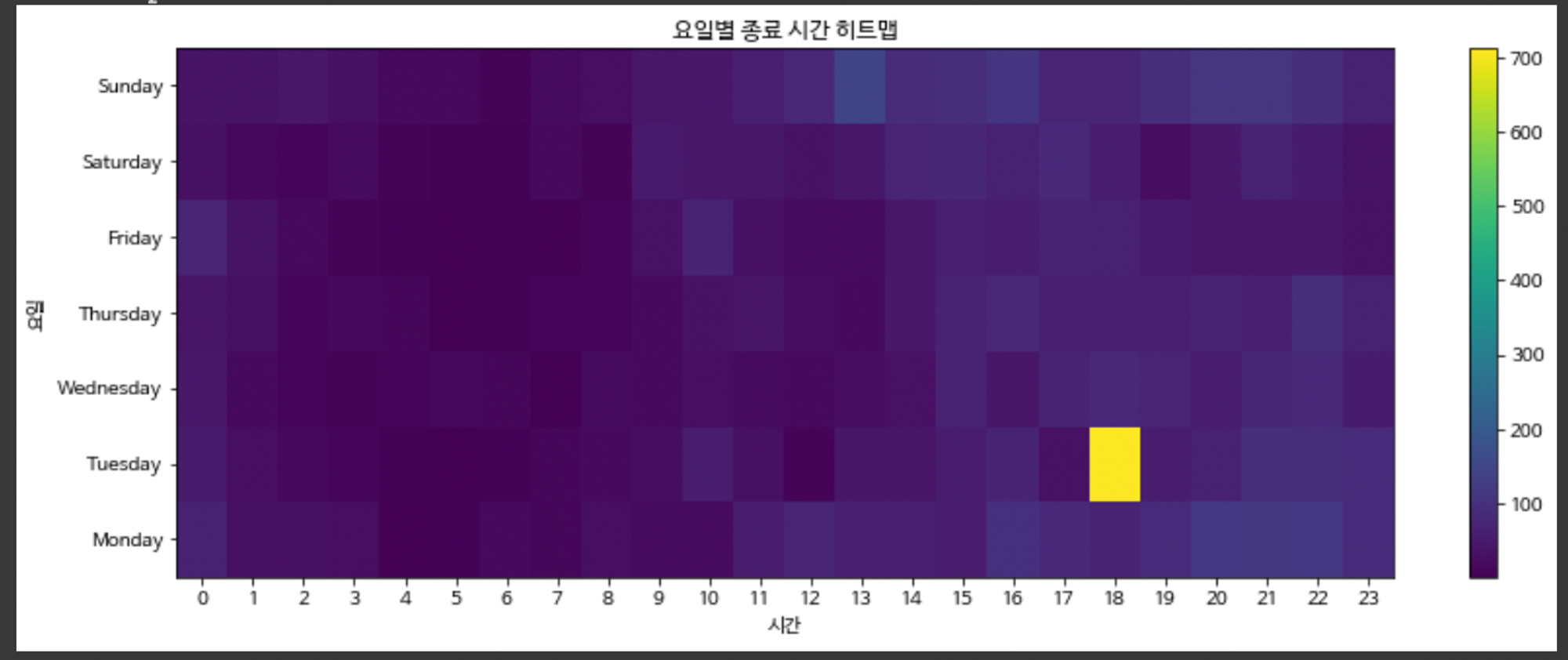
최종 결론
-
수강생들의 접속 일자
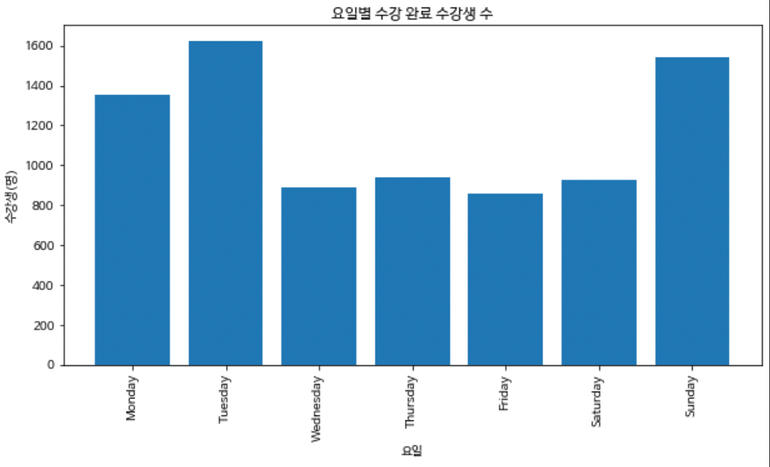
<화요일> 다음으로 <일요일>에 수강을 듣는 학생이 제일 많았고,
<금요일>, <수요일>에 수강하는 인원이 가장 적은게 확인됨 -
일별 접속 시간 추이
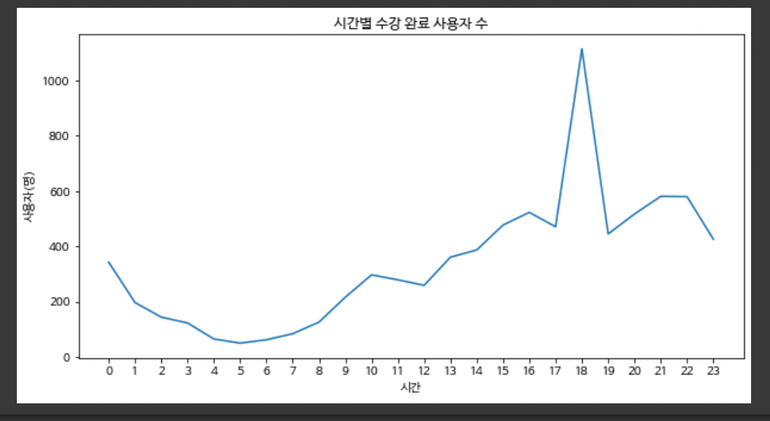
18시쯤이 폭발적으로 많았고, 밤 21시부터 감소하는 추세를 보임 -
요일, 시간대 별 히트맵
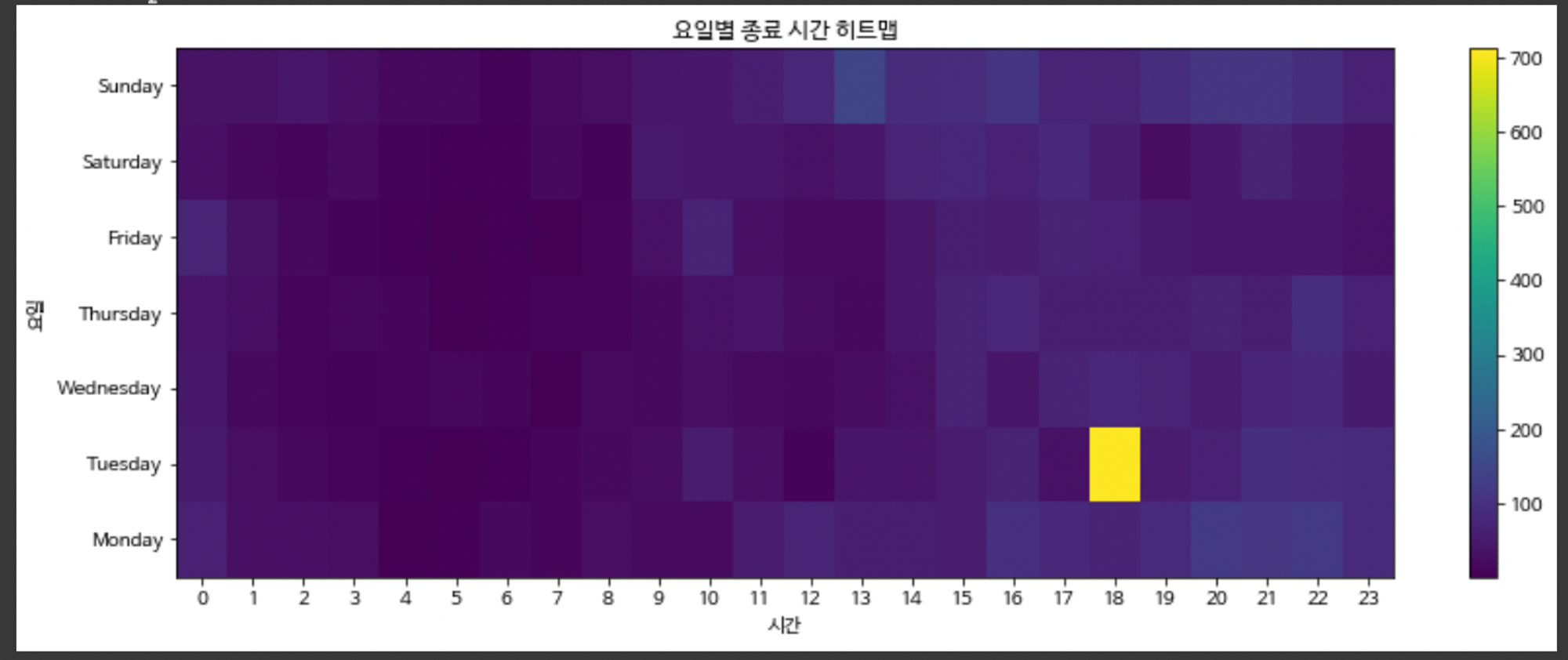
화요일 18시에 가장 많은 접속자가 있다는 것을 확인할 수 있었다.
따라서 고객관리 문자는 가장 수강을 많이 한 `화요일, 일요일 저녁시간` 쯤에 독려 문자를 가장 수강을 적게 한 `금요일, 수요일 오전` 시간에 동기부여 문자를 보낼 것을 제안 가능하다.

데이터 애널리스트가 되고 싶은