
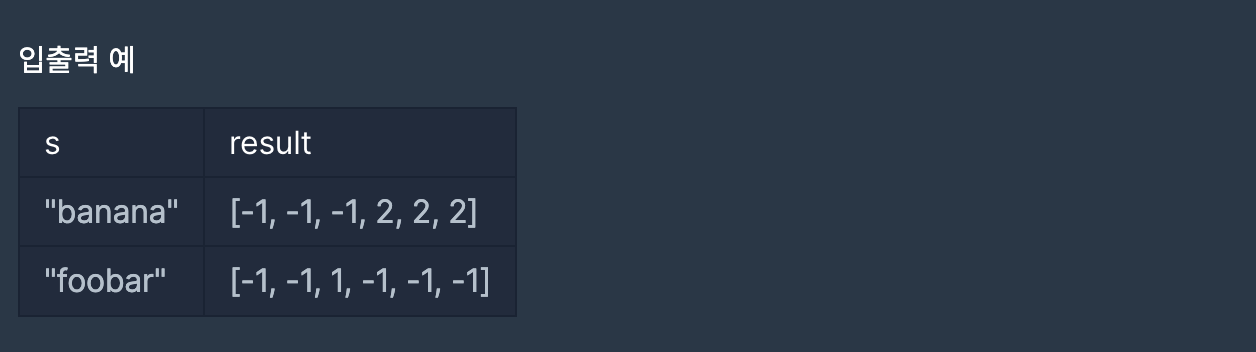
첫 시도
def solution(s):
answer = []
#지나간 s의 index값을 저장하는 변수
save = ''
#enumerate를 사용하여 인덱스 번호와 현재 요소의 값을 가져옵니다.
for index, value in enumerate(s):
#.find 는 값이 없으면 -1 을 반환합니다.
if save.find(value) == -1:
#지나간 value를 저장
save += value
answer.append(-1)
#값이 있을시
elif save.find(value):
#중복 값의 위치를 배열로 저장
indices = []
#enumerate 를 사용해서 인덱스 번호와 현재요소 값을 찾아서 중복값 위치를 indices에 저장
for j, char in enumerate(save):
if char == value:
indices.append(j)
#마지막 중복값 위치를 저장
last_indices = indices[-1]
#인덱스 위치와 마지막 중복값 위치를 빼서 정답에 입력
answer.append(index-last_indices)
save += value
return answer- 우선 해당 단어를 저장할 공간
save변수를 만들어서for문이 반복 될때마다 해당 값을 저장 하는 공간을 만들었습니다. - 다음
for문으로 어떻게 값의 위치와 값을 쉽게 저장할 방법을 찾다가enumerate를 찾았습니다.
enumerate: 이 함수는 반복문에서 반복 가능한 객체(리스트, 튜플 등)의 인덱스와 값을 동시에 추출할 수 있도록 도와줍니다.
.find는 값을 찾지 못했을때-1이 출력되는걸 알고 해당 값이 나타났을때save에 해당 문자를 저장하고answer에-1을 대입 해주었습니다.
4.이후elif로save에서 해당 문자를 찾았을시에indices라는 변수를 만들어 중복값의 위치를 배열로 저장하였습니다.
5.for문과enumerate를 사용해서 다시index와value를save에서 처음 반복된 문자와 비교해서 있을시 해당 위치를indices에 저장했습니다.- 마지막 중복값 위치를 저장하기 위해
last_indices변수를 만들었습니다.
7.마지마으로 정답에index-last_indices를 하여서 해당 값만큼answer에 저장했습니다.
실패 이유
하지만 해당 코드는 예제는 성고했지만 알고리즘 테스트에서는 실패 하였습니다.
조건문 문제
이후 해당 코드가 왜 잘못 되었는지 찾았습니다.
지금의 answer와 save에 값을 넣을때의 if문은
if save.find(value) == -1:
......
elif save.find(value):
.....이렇게 되어있습니다.
if를 사용했을때는 ture값이 나와야합니다.
하지만 python에서 0은 거짓(false)이기 때문에 index의 위치가 0일때 if에서 false 이기 때문에 해당 조건은 잘못된것이 됩니다.
해결된 코드
def solution(s):
answer = []
#지나간 s의 index값을 저장하는 변수
save = ''
#enumerate를 사용하여 인덱스 번호와 현재 요소의 값을 가져옵니다.
for index, value in enumerate(s):
#.find 는 값이 없으면 -1 을 반환합니다.
if save.find(value) == -1:
#지나간 value를 저장
save += value
answer.append(-1)
#값이 있을시
else:
#중복 값의 위치를 배열로 저장
indices = []
#enumerate 를 사용해서 인덱스 번호와 현재요소 값을 찾아서 중복값 위치를 indices에 저장
for j, char in enumerate(save):
if char == value:
indices.append(j)
#마지막 중복값 위치를 저장
last_indices = indices[-1]
#인덱스 위치와 마지막 중복값 위치를 빼서 정답에 입력
answer.append(index-last_indices)
save += value
return answer해결된 코드는 간단합니다
elif대신에 else를 사용해서 save에 값이 없을때만 조건을 주고 나머지는 번호를 찾아서 정답 위치에 넣었습니다.
좀더 쉬운 코드
def solution(s):
answer = []
# last_seen: 각 문자가 마지막으로 등장한 인덱스를 저장하는 딕셔너리
last_seen = {}
# s를 순회하며 i(인덱스), ch(문자)를 하나씩 꺼내온다.
for i, ch in enumerate(s):
# 1) 만약 ch가 last_seen에 없다면(처음 등장하는 문자라면)
if ch not in last_seen:
answer.append(-1)
else:
# 2) 이미 last_seen에 있다면(한 번 이상 나왔던 문자라면)
# 현재 인덱스(i) - 마지막 등장 인덱스(last_seen[ch]) = 거리
answer.append(i - last_seen[ch])
# 어떤 경우든 마지막 등장 인덱스를 갱신한다.
last_seen[ch] = i
return answer
GPT에게 물어보아서 위에 코드를 수정해달라고 해서 찾았습니다.
해당 코드와 제가한 코드의 차이점은
- 딕셔너리 사용 코드
- 마지막 인덱스를
key-value로 관리
- 문자열 누적 코드
save에 이미 본 문자열을 전부 이어 붙임- 중복 여부를 검사할 때마다 문자열을 검색하므로 효율 떨어짐
가장 큰 차이점은 중복 문자의 마지막 위치를 어떻게 추적하느냐입니다.
이를 딕셔너리로 관리하면 편하고 버그도 안생기며
성능면에서도 더 좋습니다.
딕셔너리란?
해당 코드를 보면서 나중에도 쓸일이 많을거 같은 딕셔너리(Dictionary)를 따로 작성해 머리속에 넣어둘려고 합니다.
딕셔너리 : python에서 key와 value쌍을 하나로 묶어서 데이터를 저장하는 자료형 입니다.
예시코드:
my_dict = {
"name": "Alice",
"age": 25,
"city": "Seoul"
}Key : "name", "age", "city"
value : "Alice", 25, "seoul"
딕셔너리는 인덱스(0,1,2...)이 아니라 Key를 통해서 값을 바로 찾아볼 수 있습니다.
이를 해시라고 부르며, 보통 리스트에 비해 탐색속도가 O(1)로 훨씬 빠릅니다.
또한 값을 생산하거나 새로 추가하기도 쉽습니다.
my_dict["age"] = 26: 기존"age"키의 값을 갱신my_dict["country"] = "South Korea": 새로운 키-값 쌍을 추가

백엔드 개발에 관심있는 1인