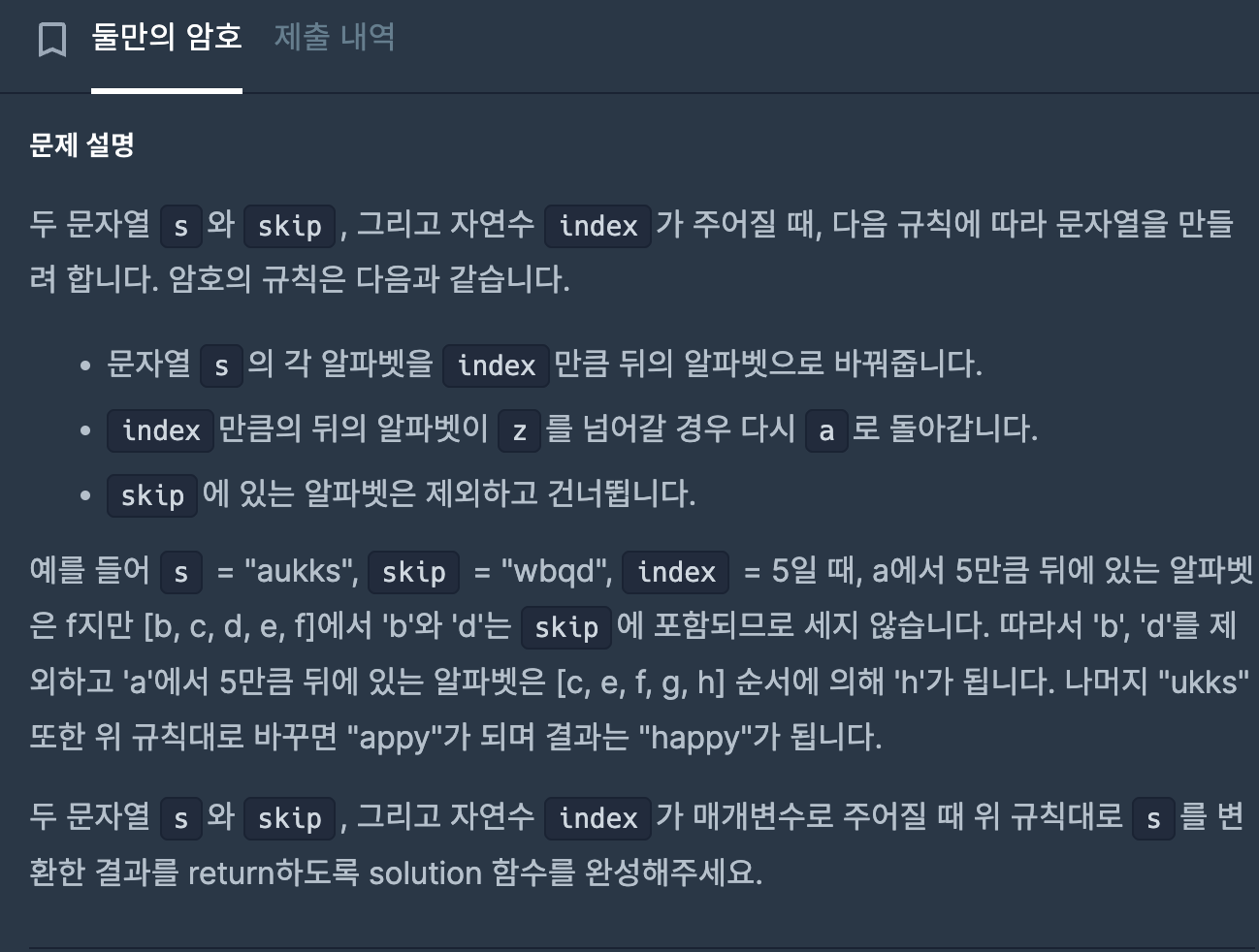
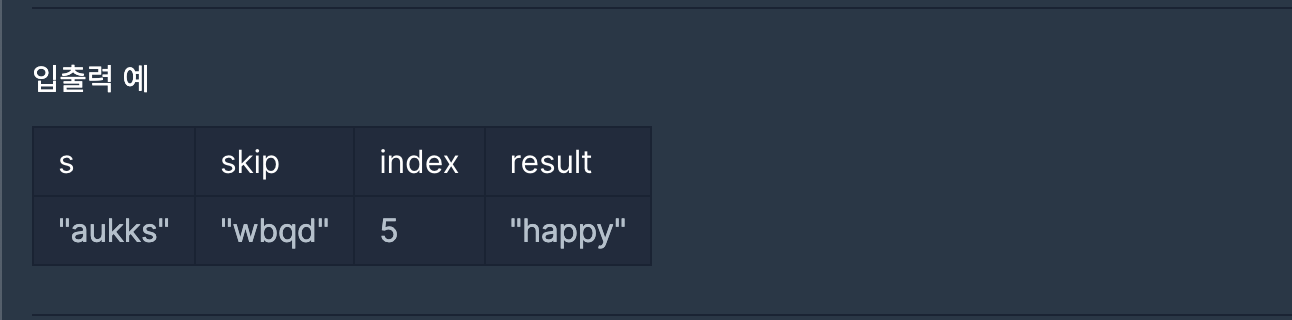
풀이
우선 알파벳들을 유니코드로 변환하는 함수를 찾았습니다.
ord(): 문자를 유니코드로 전환(int)
첫 시도(실패)
def solution(s, skip, index):
answer = ''
updateIndex = 0
for i in s:
sUni = ord(i) + index
for j in skip:
skipUni = ord(j)
if sUni > skipUni:
updateIndex += 1
print(f'스킵 유니 : {chr(sUni)} 업데이트 유니 : {updateIndex}')
if updateIndex > 0:
updateUni = chr(ord('a') + (sUni - ord('a') + updateIndex) % 26)
updateIndex = 0
answer += updateUni
return answer첫 시도의 실패 이유는
만약 s가 u인데 skip의 문자들을 거치지 않았음에도 updateIndex가 증가하여 실패했습니다.
두번째 시도
우선 두번쩨 시도하기전에 저는 죽어도 3중 반복문을 사용하기 싫었습니다.
그래서 skip의 데이터들을 배열로 형태로 정리하고
if문으로 skip안에 있는 데이터 들과 같을시 +2를 하기로 생각했습니다
def solution(s, skip, index):
answer = ''
skip_set = set(skip)
for i in s:
new_Char = i
for j in range(index):
new_Char = chr(ord('a') + (ord(new_Char) - ord('a') + 1) % 26)
if new_Char in skip_set:
new_Char = chr(ord('a') + (ord(new_Char) - ord('a') + 1) % 26)
answer += new_Char
return answer예시는 통과했지만 제출할때는 통과하지 못했습니다
이유는 건너뛰어야할 문자가 연속으로 있을시 처리하지 못한다는거였습니다.
결국 다른 사람 풀이를 보게 되었습니다
다른사람 풀이
def solution(s, skip, index):
alpha = "abcdefghijklmnopqrstuvwxyz"
answer = ""
for i in list(skip):
alpha = alpha.replace(i,"")
for a in s:
answer += alpha[(alpha.find(a) + index) % len(alpha)]
return answer먼저 알파벳을 순서대로 작성을하고
for문으로 skip에 있는 단어들을 replace로 해당 단어를 찾아 없앱니다.
마지막 반복문에
skip으로 인해 지워진 alpha변수에 해당 알파벳이 몇번째인지 찾고 + index 한뒤 % len(alpha)로 z가 넘어갈시 a로 다시 돌아가게 만들어 줍니다.

백엔드 개발에 관심있는 1인