SQL 문제 링크
https://school.programmers.co.kr/learn/courses/30/lessons/59413
오늘 SQL 문제를 풀다가 테이블도 하나이고 시간대별로 몇 개의 데이터가 있는지 뽑아내는 문제라 간단하다고 생각했다. 하지만 돌아오는 답은 '실패' ..
SELECT substr(DATETIME, 12, 2) as HOUR,
if(count(ANIMAL_ID) > 0, count(ANIMAL_ID), 0) as "COUNT"
FROM ANIMAL_OUTS
WHERE HOUR(DATETIME) BETWEEN 00 AND 23
GROUP BY HOUR
ORDER BY HOUR실행 결과
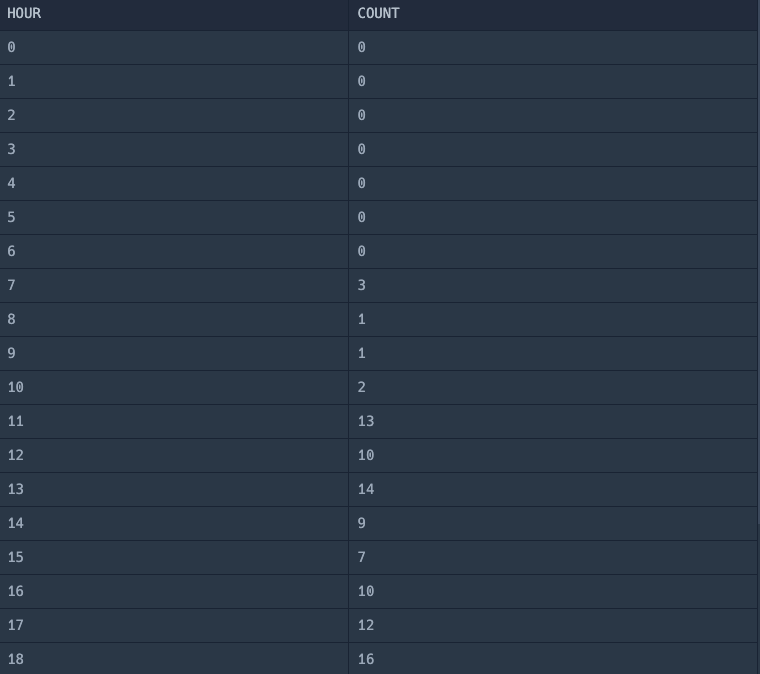
요구하는 답안은 0시 부터 23시 까지의 데이터, 데이터가 없는 시간대는 0을 넣어서 조회되도록 하는 것이다. 하지만 내가 짠 쿼리는 0시 ~ 23시 중 데이터가 있는 시간대와 갯수를 보여주고 있다.
SQL 변수
SQL 쿼리에서도 변수를 선언하고 사용할 수 있다는 걸 알게되었다. 변수를 사용하면 복잡한 계산을 저장하거나, 이전 행이나 쿼리에서 얻은 값을 재사용할 수 있다 !
변수 선언과 초기화
SET @counter = 1; -- 정수 값으로 초기화
SET @name = 'John'; -- 문자열 값으로 초기화변수 사용
SET @hour = 10;
SELECT *
FROM ANIMAL_OUTS
WHERE HOUR(DATETIME) = @hour;@hour 변수를 조건절에서 사용하여 DATETIME의 시간 값이 10인 데이터를 필터링 한다.
변수를 사용한 계산과 누적 합
변수를 사용하여 누적 합계나 카운트 같은 값을 계산할 수 있다. 이때 := 연산자를 사용하여 변수를 업데이트 한다.
SET @running_total = 0;
SELECT
item,
price,
@running_total := @running_total + price AS cumulative_total
FROM sales
ORDER BY item;이 예시 쿼리는 각 item별 price의 누적 합을 계산하여 cumulative_total 컬럼에 저장한다.
조건에 따라 변수 변경
변수를 조건에 따라 업데이트하거나 특정 조건을 필터링하는 용도로 사용할 수 있다. 예를 들어, 특정 조건을 충족할 때만 변수를 변경하거나 쿼리의 흐름을 조정할 수 있다.
SET @status = 'pending';
SELECT
order_id,
CASE
WHEN amount > 100 THEN @status := 'high value'
ELSE @status
END AS order_status
FROM orders;amount 값이 100보다 큰 경우 @status 변수를 'high value'로 변경하고, 그렇지 않으면 기존 상태인 'pending'을 유지한다.
변수를 사용한 루프와 시퀀스
변수를 사용하여 특정 범위 내에서 값을 반복적으로 증가시키는 방식으로 시퀀스 생성에 활용할 수 있다.
SET @hour = -1;
SELECT (@hour := @hour + 1) AS hour
FROM some_table -- 반복을 위해 사용되는 테이블 (데이터 수와 무관)
WHERE @hour < 23;변수 사용 시 주의해야 할 것
- 변수는 세션별로 존재하므로 세션이 종료되면 변수도 사라진다. (영구저장 X)
- 상관 서브쿼리나 복잡한 조건을 설정할 때는 성능에 주의해야한다.
결론 : SQL 변수는 반복적 계산과 조건을 간단하게 표현하는데 매우 유용하며, 특히 복잡한 쿼리의 가독성을 높이는데 도움이 된다 !
그럼 다시 처음으로 돌아가 문제의 답안을 적어본다.
- 변수를 이용해서 수정한 SQL
SET @HOUR = -1;
SELECT (@HOUR := @HOUR + 1) AS HOUR,
(SELECT COUNT(HOUR(DATETIME))
FROM ANIMAL_OUTS
WHERE HOUR(DATETIME)= @HOUR
) AS COUNT
FROM ANIMAL_OUTS
WHERE @HOUR < 23;- HOUR라는 변수를 선언하고 -1로 설정한다.
- @HOUR := @HOUR + 1; , HOUR 변수의 값을 1씩 증가시키며, 각 행마다 0부터 23까지의 숫자를 HOUR 컬럼으로 표시한다.
- 서브쿼리에서 ANIMAL_OUTS 테이블에서 DATETIME의 시간 필드가 현재 @HOUR 값과 일치하는 행을 찾고, 그 개수를 COUNT로 반환한다.
- WHERE @HOUR < 23: @HOUR이 23이 될 때까지 쿼리를 실행하도록 제한한다. 이 조건이 없으면 계속해서 @HOUR가 증가하여 쿼리가 종료되지 않을 수 있다.
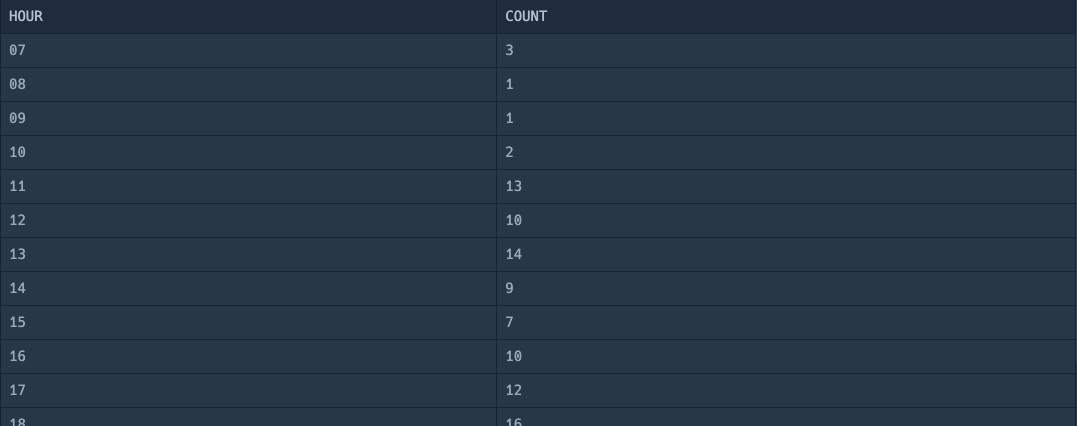
실행 결과