[개발일지 2022.4.21] Microsoft Azure(4)
1.학습한 내용
1) Azure Storage
Azure Storage

Azure Storage 서비스
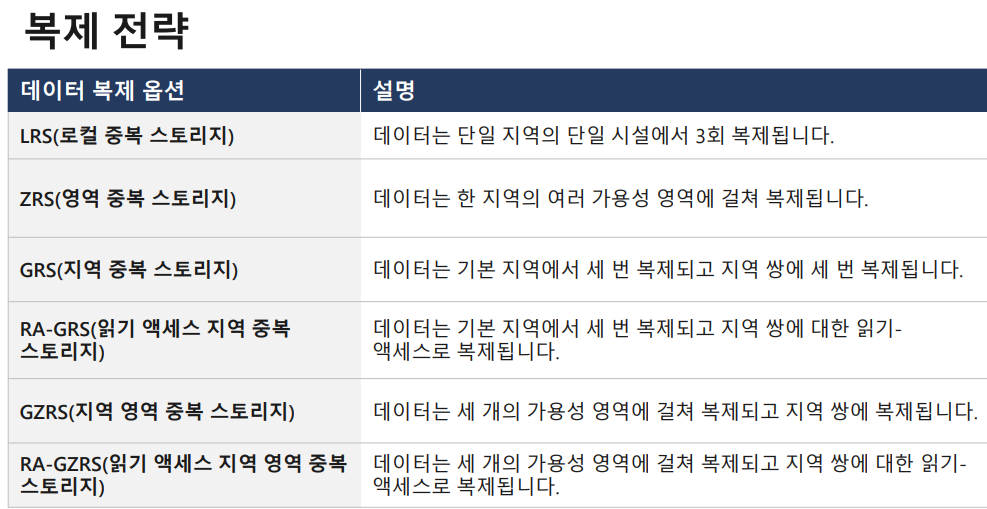
복제 전략
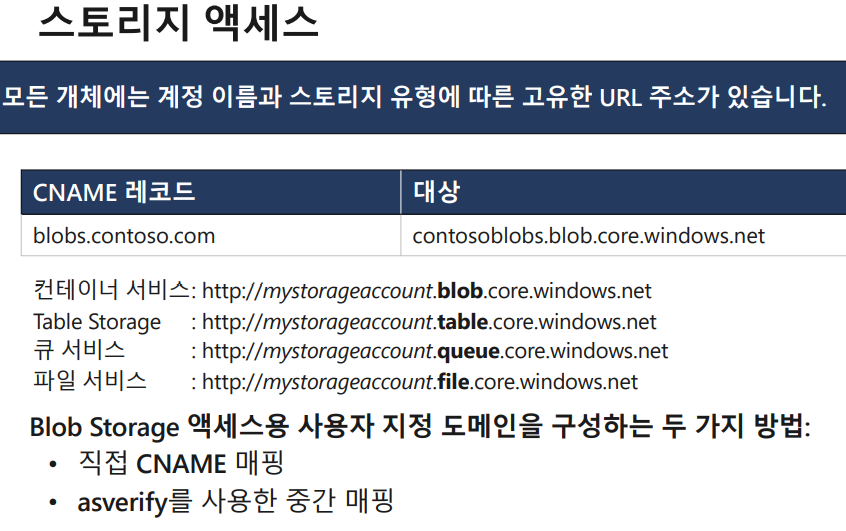
1-1) Storage Account
리소스 그룹 - 만들기 - 저장소 - 스토리지 계정
저장소계정 만들기 - 리소스 그룹 설정 -스토리지 계정 이름 labuserㅁㅁstorageaccount ,위치-korea central 만들기
생성된 스토리지에서 Blob 서비스 - +컨테이너 -이름 conㅁㅁ - 공욕 액세스 수준 - Blob- 만들기
파일 업로드 - 추가
업로드 된 파일을 들어가보면 URL이 나오는데, 이를 웹에서 입력하면 바로 보인다.
이때 주소는 아래와 같이 만들어진다.
이때 하나씩 업로드 하는것은 쉽지만
대량의 데이터를 업로드 할때는
REST API 를 사용한다.
file service
공유파일이다.
저장소 - 파일 서비스 - +파일 공유 - 이름 짓기 fileㅁㅁ - 계층 : 핫 - 만들기
1-2)Blob Storage


이러한 스토리지의 가격은
스토리지 비용,
데이터 액세스 비용(데이터에 액세스 한 횟수),
트랜잭션 비용(얼마나 다운받았는가),
지역복제 데이터 전송비용(지욕복제를 얼마나 했는가) ,
아웃바운드 데이터 전송 비용(검색할때의 데이터요금에 따라),
스토리지 계층 변경(스토리지의 계층을 바꿀때)
에 따라서 바뀐다.
또한 사용할 기간과 크기에 따라서 가격을 협상을 하는것 또한 가능하다.
2)Azure Database

Azure SQL Database-SQL Server (Microsoft사)
Azure Data base for MySQL(가장 많이 쓰인다), Azure Database for MariaDB, Azure Databse for PostgreSQL 을 오픈소스로,이미 공개되어있다.
2-1)MySQL

데이터베이스는 수를 늘리는것은 어렵기 때문에 보통 크기를 키우는 Scale up 을 한다.
MySQL 만들기
리소스그룹 - RGㅁㅁ - 만들기 - 검색 MySQL -
Azure Database for MySQL 만들기 - 유연한서버(PaaS) - 서버이름:daegumysqlㅁㅁ - 지역:Korea Central - MySQL 버전 : 8.0 - 관리자계정 : 사용자이름, 암호 설정 - 다음
네트워킹 - 퍼블릭 액세스(허용된 IP 주소) -방화벽 규칙 현재 클라이언트 IP 주소 추가 -다음
검토 및 만들기 - 만들기
2-2)MySQL workbench
SQL을 사용하기 위해서
MySQL workbench 을 사용한다.
만들어낸 Azure MySQL 개요에서 서버이름을 복사한다.
위의 Database - connect to database- hostname : 복사한 서버이름 입력 - username: MySQL 을 만들때 입력한 아이디 - password : Store in Keychain ... : 입력한 비밀번호 - OK
화면이 나오면
미리 준비한 sql파일을 불러온다.
이후 번개마크인 Execute (단축키 : Ctrl + Shift + Enter) 를 누르면 실행을 한다.
이를 통해서 데이터베이스가 생긴것을 확인할수있다.
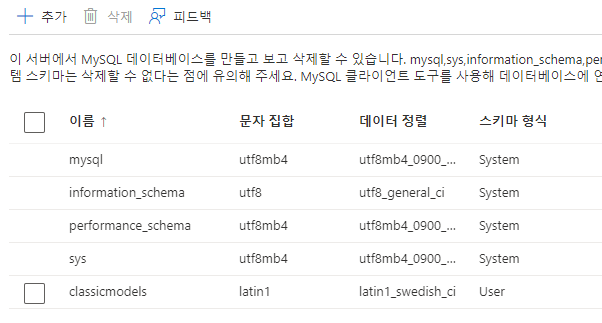
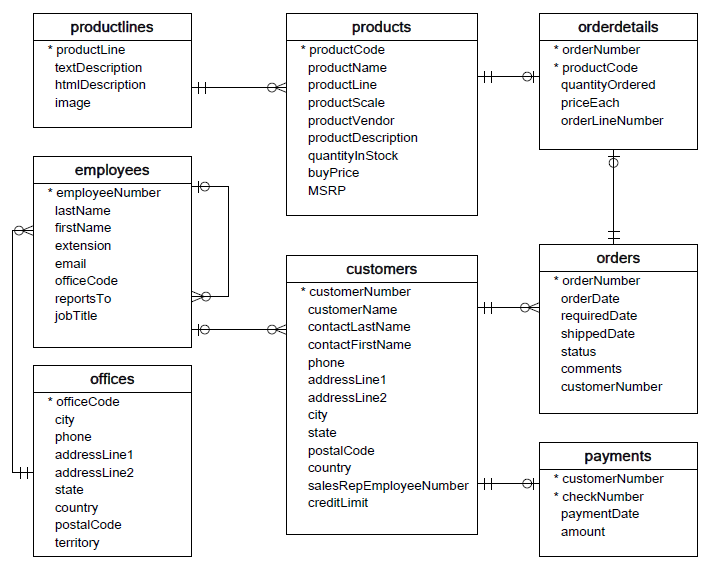
이때 만들어진 데이터베이스를 보기 쉽게 정리한것이
ERD (Entitiy Relation Diagram) 이다.
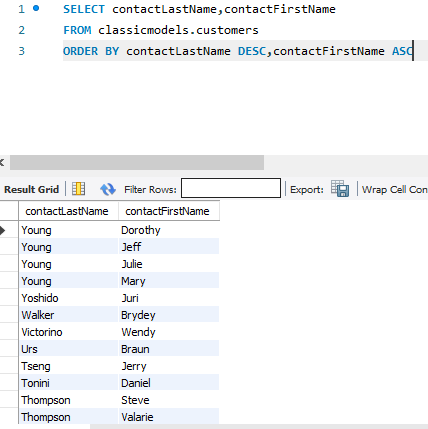
SELECT : 지정해서 연다, 이때 *는 전부를 의미한다.
USE: 데이터베이스를 지정한다.
ORDER BY ㅁㅁ: ㅁㅁ를 기준으로 정렬을 한다 이때, ㅁㅁ 뒤에 DESC 를 입력하면 역순으로 정렬이 된다 ,ASC는 정렬한다.
이후
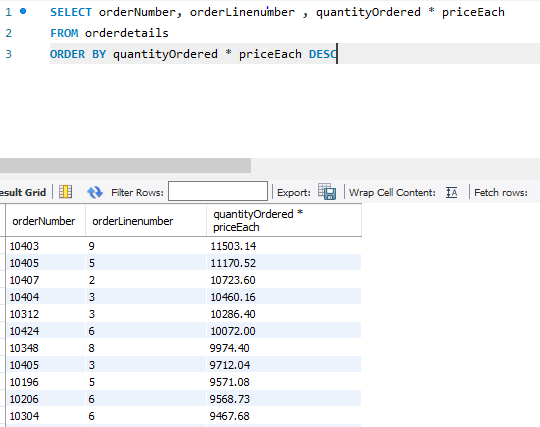
이렇게 표를 표현하는것을
AS 로 변수로 치환을 하면
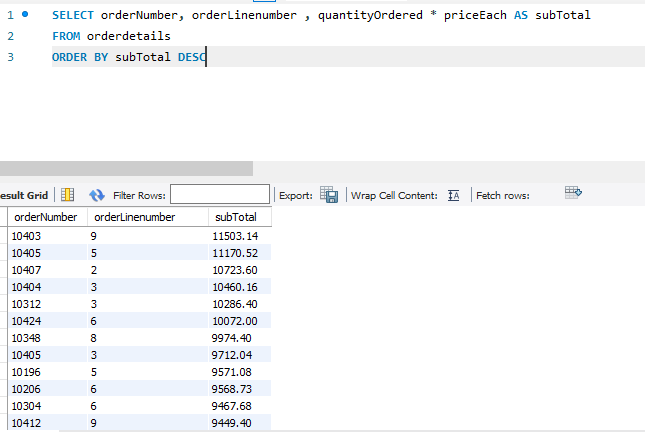
변수를 취하는것으로 코드를 더짧고, 보기 쉽게 만들어진다.
WHERE : 조건을 주는 명령어.
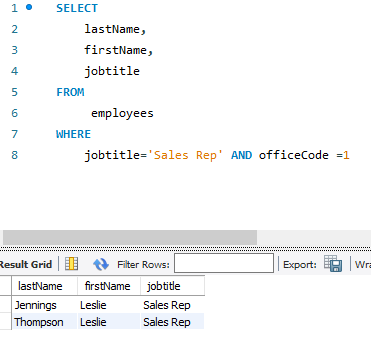
그림과 같이 jobtitle 이 Sales Rep 인 사람중에서 officeCode가 1인사람만 나올때 2명이 표기가 된다.
AND : 그리고
OR : 또는
BETWEEN a AND b : a와 b 사이를 불러온다.
% : 전후에 붙은 데이터를 찾는다.
LIKE: 전체에서 찾아보는 명령어 (전체에서 뒤져보는것이기 때문에, 자주 사용해선 안되는 명령어이다)
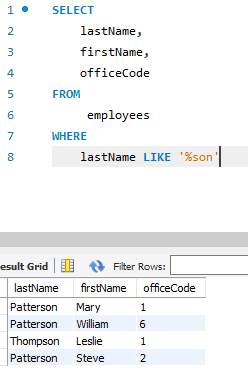
IN (a,b) : a또는 b인것들을 불러온다.
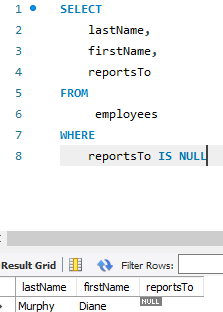
IS NULL : Null 값을 찾는 명령어
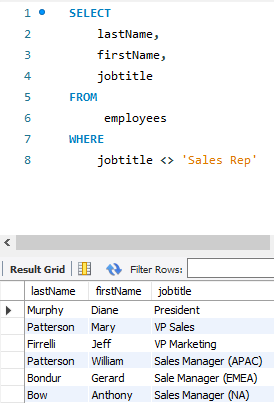
<> : =과 반대로 해당 경우가 아닌 경우를 불러온다.
DISTINCT : 중복을 제거하는 명령어
Alias : AS와 비슷하게 지정하는것이지만 그 사이에 띄어쓰기만 한다 ,
ex) employees as E = Employees e
GROUP BY: 그룹을 짜는 명령어.
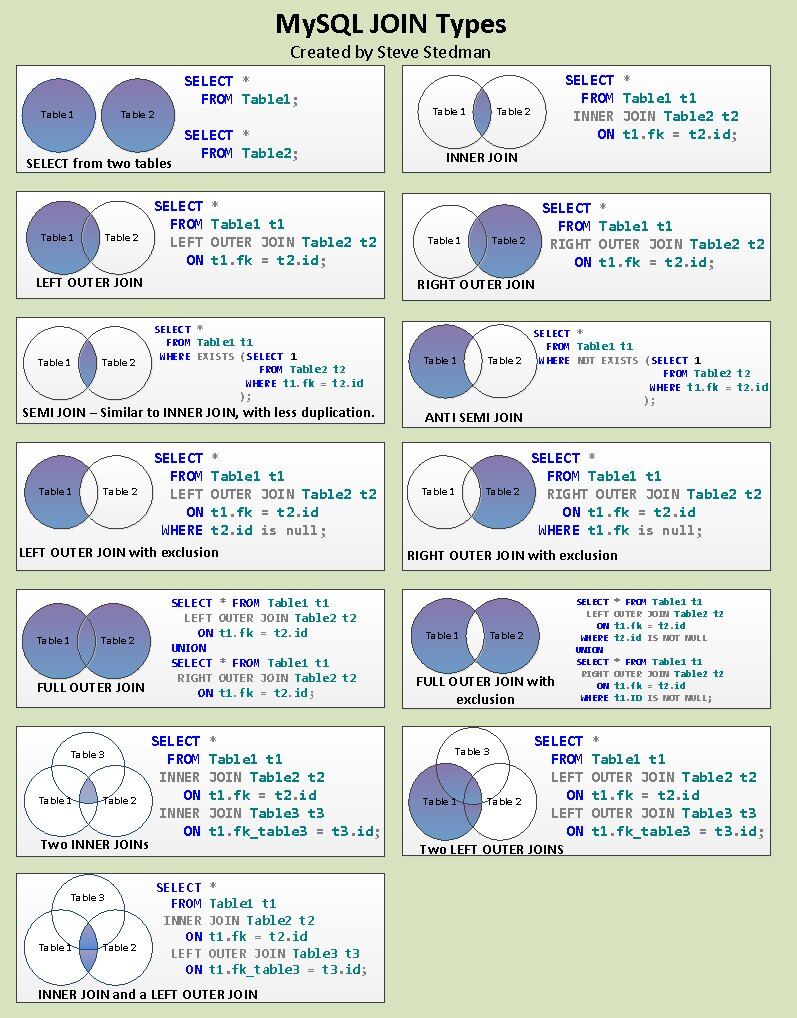
JOIN TYPEs
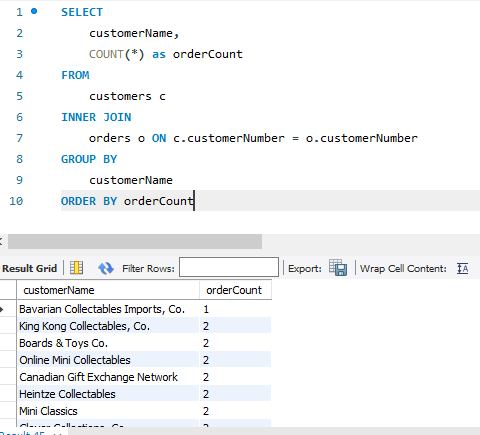
HAVING : 집계한 결과의 조건(WHERE 와 다르다)
UPDATE WHERE: 업데이트 하는 명령어
DELETE WHERE: 삭제하는 명령어
※이위의 두개의 명령어의 경우에는 WHERE 을 설정하지 않으면 전체에 적용이 되므로 반드시 주의해야한다
위의 명령어들은 해외 사이트에 정리도 되어있다.
2.학습내용 중 어려웠던 점
JOIN 부분을 공부하는 과정에서 이야기 하는것이 바로바로 이해하기가 어려웠다.
3.해결방법
강사님이 보내주신 이미지를 통하여서 복습하면서 헷갈릴때마다 다시 확인하는것으로 이해를 하고있지만, 헷갈릴 때 항상 보고하기는 어려울수있으니 이또한 자주 보면서 기억해두는것이 좋을것 같다.
4.학습소감
이전에 데이터베이스의 기본적인 것만 배웠다가, 이번에 쿼리를 다양하게 배울수 있었다, 하지만 이것 또한 직관적으로 의미를 알수있는 단어들을 사용하는것으로 대부분은 뜻을 이해할수있었지만, JOIN과 같은 명령어 구문같은것들은 문장 자체를 이해하는것도 중요하다는것을 알게되었기 때문에, 이에 대해서 더 자세히 알아보아야 할것같다.
또한 강사님이 수업에서 가르쳐주시지는 못했지만, 찾아보면 좋은 개념에 대한 키워드로
PK FK INDEX VIEW 이렇게 네가지를 주었는데, 이에 대해서도 영상을 찾아보아야 할것이다.
