[개발일지 2022.4.4] AI 기본이론
1.학습한 내용
1)머신러닝 Machine Learning
머신러닝은 인공지능 AI가 나오고 발전하면서, AI에 대한 기대치가 올라가서 수학이 아닌 사람이 하는 일을 하는것 목표로써
인간이 개발한 알고리즘을 컴퓨터 언어를 통해서 기계에게 학습시키는 행위를 뜻한다.
일반적인 컴퓨터 사이언스는, 사람이 방법을 찾아서 기계에게 알려주는것과 달리
머신러닝은 대량의 데이터를 주고 기계에게 방법을 찾게하는 방식이다.
2)머신러닝 알고리즘 Machine Learning Algorithm
머신러닝의 알고리즘으로는 머신러닝 버블차트(Machine Learning Bubble Chart)를 보고 이해하는것이 좋은데.
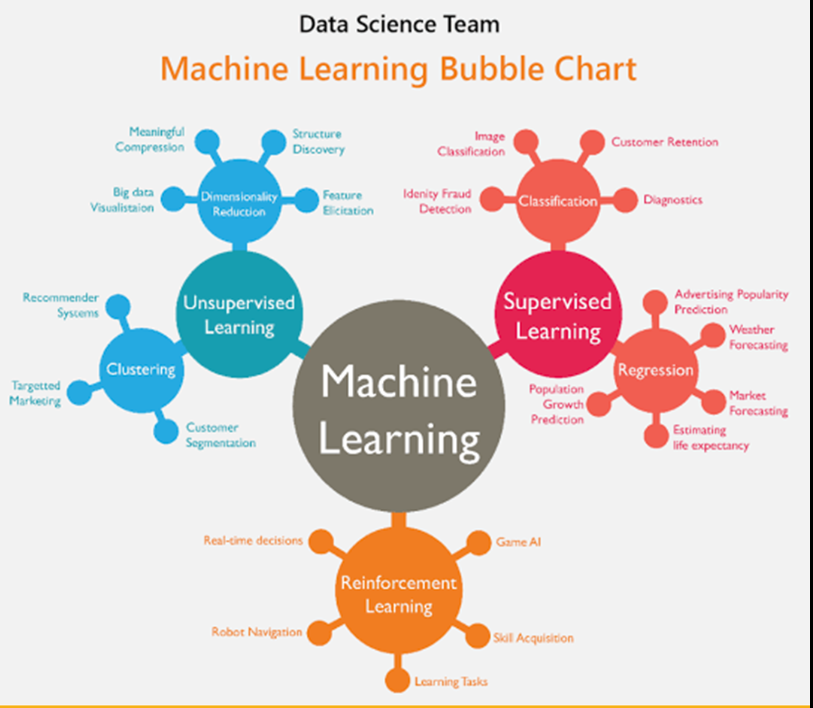
(Machine Learning Bubble Chart)
2-1) Supervised Learning(지도학습)
supervised Learning 의 경우에는 문제와 정답(Feature & Label) 을 기계에 제공하고, 그를 통해서 예측, 추정, 분류 (Regression(회귀) ,Forecast, classfication) 하여 데이터를 얻는 것이다.
2-2) Unsupervised Learning(비지도학습)
supervised Learning 과 다르게 unsupervised learning 의 경우에는, 문제(Feature)만을 제공하고, 패턴,구조를 발견하여 그룹화하는 방식이다.
예를 들어 Anomaly 의 경우에는 카드사에서 많이 사용되는데,
평소에 지불하는 금액과 다르게 임계치를 넘어서는 금액의 결제라는 이상징후를 감지하게되면 결제를 멈추고 전화를 통하여서 확인하는것으로 금융사고를 방지한다.
2-3) Reinforcement Learning(강화학습)
피드백을 통하여 보상(reward)이 제공이 되며, 보상에 대한 인과관계가 중요하다.
게임과 로봇 등에 사용이 된다.
이를 로봇에 활용한 예시 : 보스턴 다이내믹스 로봇
3)Data
입력한 데이터에 따라서 나오는 결과값이 있는 것
ex)
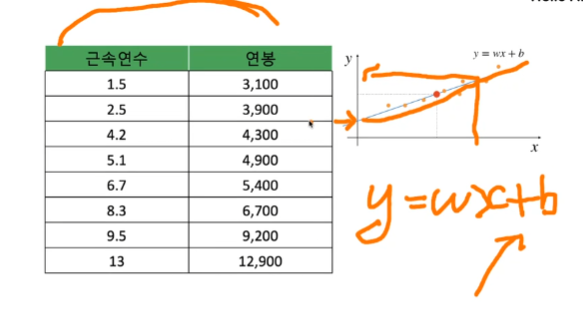
근속연수와 연봉이라는 데이터가 있을때.
y=wx+b
x는 근속연수이고 y는 연봉이라면 b는 시작시 받게되는 돈, 초봉이 된다.
그리고 w는 근속연수가 바뀜에 따라서 늘어나는 기울기값으로 볼수있다.
3-1)data step
First- Understand the Business Domain
해당되는 영역을 이해하는것
Second - Understand the Business Problem
해당되는 문제는 이해하는것
Third - What is the right Data, Rgith Column and Right Algorithm
정확한 데이터와 정확한 칼럼, 정확한 알고리즘을 선택해야한다.
Last- Combine Knowledge With Machine Learning
끝으로 머신러닝과 결합을 한다.
3-2)Open data
공개된 데이터로써
국가 통계 포털 KOSIS
에서 금융데이터 등 여러가지 오픈 데이터들을 확인할수있다.
4) Orange data mining 오렌지.
오렌지orange 라는 프로그램 을 받게 되면, 직접 코드를 짜지 않고 이미 짜여져 있는 도구들을 이용하여서 데이터처리 및 시각화, 그리고 머신러닝이 가능해진다.
실행을 하면 아래와 같은 목록이 나온다.
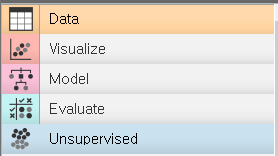
4-1)orange-Data

사진에서 보이는
File 에서 데이터를 불러오거나, CSV (comma-separated values, 쉼표(,)로 구분한 values)
datasets 등으로 데이터를 불러오는 도구들이다.
4-2)orange-visualize
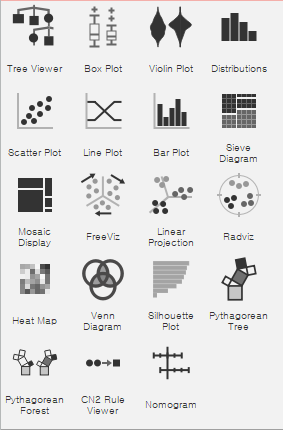
가져온 데이터를 통하여서 시각화 하는 도구들이다.
4-3)orange-model

파일을 분석할때 사용되는 알고리즘의 도구들을 모아놓은 항목이다.
4-4)orange-evaluate

파일을 분석하여서 머신러닝을 하여 사용되는 도구들이다.
4-5) Regression(회귀분석) 실습
주제: 보스턴 집 값 예측.
data : 보스턴 집값 데이터(housing)
1.데이터세트에서 housing 을 가져온다.
2.데이터 테이블을 통해서 housing 데이터가 맞는지 확인한다.
3.Scatter Plot 을 통해서 데이터의 분포를 확인한다.
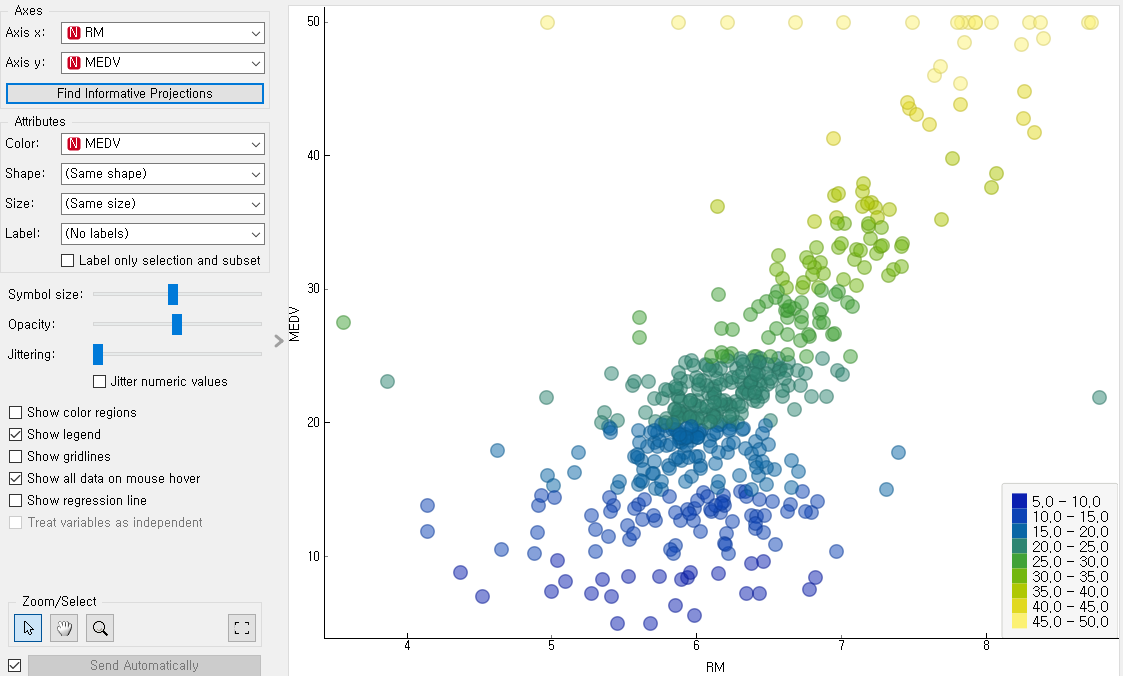
x축이 RM(1가구당 평균 방 갯수)
y축이 MEDV(집값)
일때 분포.
4.Linear Regression 의 기능을 확인한다.
5.test and score 를 통하여 테스트 후 평점을 준다.
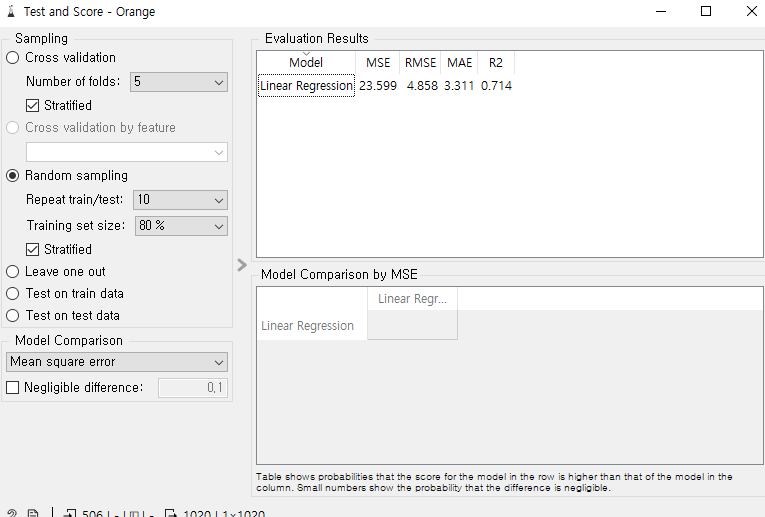
이때 나타나는
MSE 는 mean square error , 에러의 총합의 제곱
RMSE 는 root mean square error , 에러의 총합의 제곱의 제곱근
MAE 는 Mean Absolute Error, 평균 절대에러, 전체 에러의 합계의 평균값.
R2 는 R square , 결정계수로, 정확도이다.
끝이 E인 것들은 에러로써, 적을수록 좋고.
R2의 경우에는 정확도이기때문에 1에 가까울수록 정확하다.
위의 사진에서는 R2가 0.714 이므로 71.4%만큼 정확하다는 뜻이다.
이때. 알맞은 알고리즘을 알아내는 방법으로
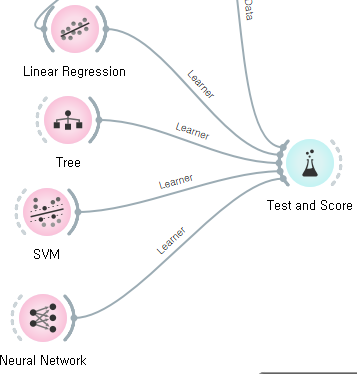
그림과 같이 여러가지 알고리즘을 사용하게 되면
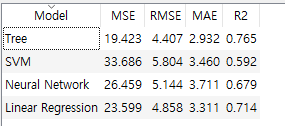
각각의 알고리즘을 사용한 값에 따른 정확도와 오차의 결과가 나타나게 되는것을 보는것으로
데이터마다 올바른 알고리즘이 다르기때문에, 올바른 알고리즘을 사용하는것이 중요하다는것을 알수있다.
2.학습내용 중 어려웠던 점
새로운 강사님의 수업을 듣게되면서, 기존에 코드만을 짜던 수업과 다르게 실제로 사용되는 프로그램을 통하고, 도구를 이용하는것으로써 과정은 이미 만들어져있고 결과를 볼수있는 도구를 사용하게 되었다. 이때, 강사님의 화면과 다르게 나오는 값들을 확인하게 되었을때, 오류가 난것이 아닌가 의심하게 되었다.
3.해결방법
이는 데이터 값에 따라서 오차가 생기는것으로써 랜덤샘플링의 항목을 버튼할때마다 샘플이 달라짐으로써 결과가 다르게 나오는것을 볼수있었다.
4.학습소감
기존의 배웠던 방식과는 다른 탓에 수업방식이 어색하기도 하며, 진행이 과정을 이해하는것이 아니라 만들어진 도구를 통해서 결과만을 확인하는것이기 때문에, 과정을 배울때는 이해를 필요로 하는것과 달리 도구를 사용하여 결과를 확인할때는 바로바로 사용하고 넘어가는 방식으로 인하여서 이해보다 진도가 빠른것이 힘든것 같기는 하다.
이 또한 많이 사용하는것으로 익숙해지기 위해서 노력을 해보아야할것같다.
