[개발일지 2022.4.6] Cognitive Services
1.학습한 내용
기본적인 Cognitive Services 를 사용하는 process 는
1- 관련 라이브러리 불러오기
2- 키와 서비스 주소 확인
3- 헤더 정보 셋팅
4- 서비스 호출
5- 호출결과로 받은 JSON 처리
의 순서를 가진다.
1)Object Detection 사물감지
1-1)Object Detection
이전 수업의 이미지를 불러내는 수업이 끝났다면 이번에는 그 이미지에서 사물들을 감지하는 Object Detection 사물감지 기술을 사용할것이다.
우선 기존에 사용하였던 라이브러리를 불러오는 것부터 한다.
import requests
import matplotlib.pyplot as plt
from PIL import Image
from io import BytesIO
import json그리고 Object Detection 기술을 사용하기 위해서 만들어진 Azure 서버의 키와 서비스 주소를 불러온다.
subscription_key = '~~~'
vision_base_url = '~~~'
#고유의 번호이기때문에 ~~~로 입력하였다.사물 감지를 하기 위해서 vision_base_url 에 이미지를 감지하는 'detect'를 추가한 값을 만든다.
objectDetection_url = vision_base_url + 'detect'그 후 사물을 감지하기 위한 이미지의 주소 하나를 불러온다.
object_image ='~~~'
#이미지의 주소또한 고유의 값이기 때문에 ~~~로 입력하였다.
img = Image.open(BytesIO(requests.get(object_image).content))이제 헤더 정보를 셋팅한다.
headers = {'Ocp-Apim-Subscription-Key':subscription_key}
data = {'url':object_image} JSON의 형식을 사용한다.
response = requests.post(objectDetection_url,
headers = headers,
json = data)detectionResult = response.json()
# 위의 코드를 짠 후 결과를 확인하는 코드를 사용한다.
detectionResult위와 같이 사물을 감지한 결과값을 확인해보면

사진과 같이 이미지를 감지하여서 데이터를 확인할수있다.
1-2)Object Detection drawing
이제 이 인식한 데이터를 이용해서 감지한 사물에 박스를 그리는 작업을 할것인데.
이를 위한 도구를 라이브러리에서 불러온다.
from PIL import Image, ImageDraw, ImageFont이후 위의 감지한 데이터중에 확인해야할것은
Rectangle : 객체의 크기를 가르쳐 주는 값.
x: 박스의 시작점의 x값
y: 박스의 시작점의 y값
w: 박스의 폭 (가로길이)
h: 박스의 높이(세로길이)
이다.
이를 이용해서 박스를 그리는 코드를 짜게 되면.
draw = ImageDraw.Draw(img)
objects = detectionResult['objects']
for obj in objects:
rect=obj['rectangle']
x=rect['x']
y=rect['y']
w=rect['w']
h=rect['h']
draw.rectangle(((x,y),(x+w,y+h)),outline='red')objects 안의 object들에서 rectangle 부분을 rect 로 하고, x값을 rect 안의 x, y값을 rect 안의 y,w값을 rect 안의 w,h값을 rect 안의 h 값으로 지정을하고.
시작점 (x,y)에서 (x+w,y+h)점까지 빨간색의 줄로 사각형을 그린다.

이를 통해 박스가 그려진것을 확인할수 있다.
또한 박스마다 이름을 붙이고 싶다면 위와 비슷하게
objectName = obj['object']
draw.text((x,y),objectName,fill='blue')objects 안에서 object의 정보를 objectName 으로 정하여서 (x,y) 지점에 obejectname 을 파란색으로 입력한다.
의 코드를 추가하게되면
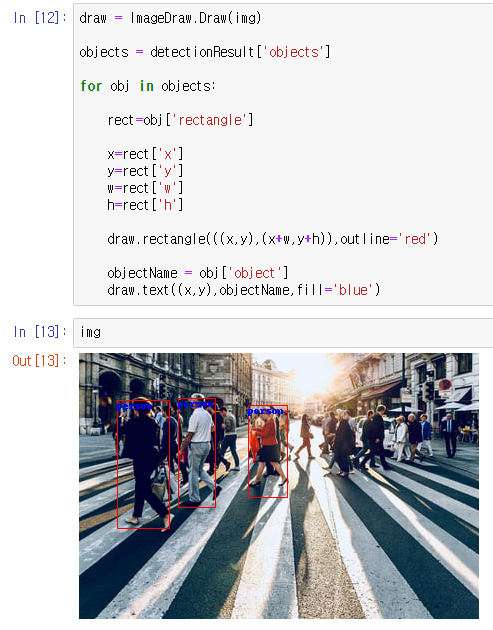
이름이 추가된것을 확인할수 있게된다.
2)Face Recognition 얼굴인식
이번에는 Cognitive Services 중 얼굴인식 기술을 이용해볼 것인데,
object detection 과 다르게 face 인식은 얼굴위치에 눈동자, 코, 눈썹등의 27가지의 중요지점(랜드마크)를 인식하는 것으로 성별,감정,나이 등 더 많은 정보를 얻을수있다.
Cognitive Services 에서
Face Recognition 을 사용하기 위해서 우선적으로 라이브러리 불러오기,
키와 서비스 주소 입력 까지를 한번에 한다.
import requests
from io import BytesIO
from PIL import Image, ImageDraw, ImageFont
subscription_key='~~~'
faceDetection_url = '~~~'그 후 분석에 사용할 이미지를 가져온다.
image_url='~~~'
img = Image.open(BytesIO(requests.get(image_url).content))헤더를 설정한다.
headers = {'Ocp-Apim-Subscription-key': subscription_key}
params = {
'returnFaceID': 'true',
'returnFaceAttributes': 'age,gender,emotion'
}
data = {'url':image_url}서비스를 호출해서 결과를 확인한다.
response = requests.post(faceDetection_url,
headers=headers,
params=params,
json=data)
faces = response.json()
faces이를 통해서 Detection 과 비슷하게 정보들이 나온다.

이 후에 인식한 사람들의 얼굴에 박스를 그린다.
draw = ImageDraw.Draw(img)
for face in faces:
rect = face['faceRectangle']
left = rect['left']
top = rect['top']
width = rect['width']
height = rect['height']
draw.rectangle(((left,top),(left+width,top+height)),outline='red')이후 objectname 을 붙였던 Detection 과 다르게 성별과 감정을 입력한다고 한다면
face_info = face['faceAttributes']
emotion = face_info['emotion']
happiness = emotion['happiness']
gender = face_info['gender']
result = 'Gender:' +gender + 'happiness:' + str(happiness * 100)
draw.text((left,top),result, fill='blue')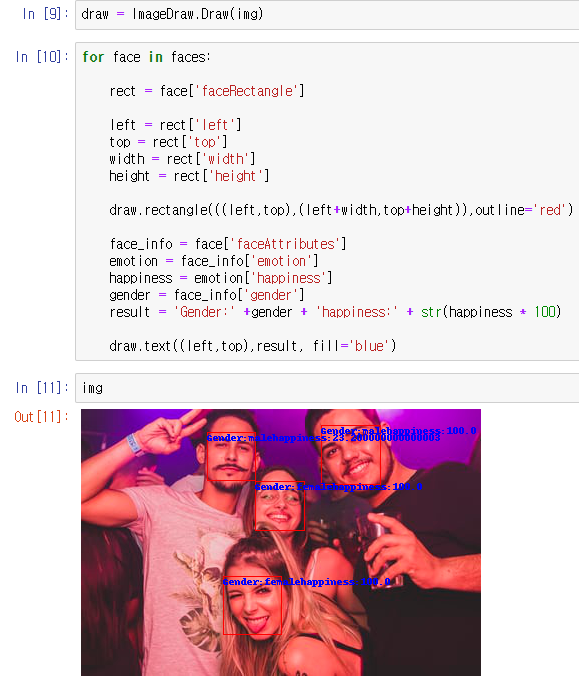
사진과 같이 사람의 얼굴에 빨간박스, 성별과 행복지수가 파랑색 글씨로 적힌다
(소수점을 없애기 위하여 *100을 설정하였는데 소수점 아래 17번째 자리의 감정이 측정되는것은 예상하지 못했다)
3)OCR 광학문자인식
이번에는 Cognitive Services 중 문자를 인식하는 OCR 기능을 사용해볼것이다.
우선 관련 라이브러리와 키와 서비스 주소를 불러오는 코드를 짠다.
이때 ocr을 사용한다는 의미에서 +'ocr' 을 사용한다.
import requests
from PIL import Image
from io import BytesIO
import matplotlib.pyplot as plt
subscription_key = '~~~'
vision_base_url = '~~~'
ocr_url = vision_base_url + 'ocr'이후 인식을 진행할 이미지를 불러온다
image_url = '~~~'
img = Image.open(BytesIO(requests.get(image_url).content))헤더를 설정한다.
headers = {'Ocp-Apim-Subscription-Key': subscription_key}
params = {'language': 'unk', 'detectOrientation': 'true'}
data = {'url': image_url}서비스를 호출해서 결과를 확인한다.
response = requests.post(ocr_url,
headers=headers,
params=params,
json=data)
analysis = response.json()
analysis
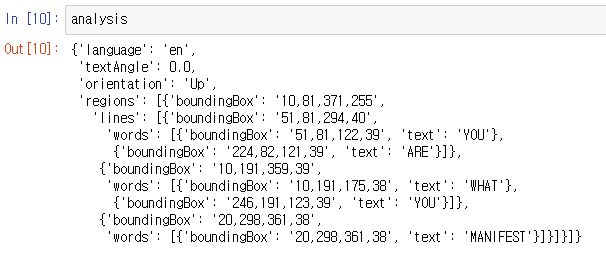
사진과 같이 words 에 묶인 text 들이 나타난다.
이제 이곳에서 text 만을 인식하여 출력하는 코드를 짜게 되는데,
line_infos = [region["lines"] for region in analysis["regions"]]
word_infos = []
for line in line_infos:
for word_metadata in line:
for word_info in word_metadata["words"]:
word_infos.append(word_info)
word_infosanalysis에서 region 만을 가져오고 , region에서 line 만을, line 안에서 word만을, word 안에서 metadata(어떤 목적을 가지고 만들어진 데이터) 가 word 인것 만을 가져와서 입력을 하게되고.
그렇게 나온것을 출력하는 코드이고 이를 출력하면

이때 사용한 이미지는

이 이미지이다.
2.학습내용 중 어려웠던 점
기초적인 코드를 배웠을때는 배운 코드의 작동하는 방식을 알고 사용한다는 느낌이었는데, 다른 곳에서 만들어진 서비스를 사용할때는 , 정해진 형식에 맞춰서 코드를 사용하는것으로 서비스를 이용하는것이 어색했다.
또한 OCR 서비스를 사용할때, 여러가지 이미지를 사용해 보았는데 인식에서 다른 줄로 인식되어서 데이터의 문자가 뒤죽박죽으로 인식되는것을 확인할수있었다.
3.해결방법
정해진 형식에 맞춰진 코드를 사용하는것은 사용하다보니 조금씩 익숙해지게 되었고, 이해안가는 코드들도 코드들을 복습하면서 이 줄의 코드는 이런 효과를 내는구나 하는식으로 비교하면서 배우게 되었다.
또한 OCR 서비스를 이용할때 이전의 Object Detection 이나 Face Recognition 기술을 사용할때는 인터넷에서 돌아다니는 이미지를 사용하는 반면, OCR서비스를 할때는 강사님이 한가지의 사진을 지정해서 알려주신후 수업을 진행하게되었었는데, 복습하는 과정에서 뒤죽박죽 인식되는것으로 인해서 여러가지 이미지들을 사용해보고 비교해보는것으로 그 이유를 알수있었다.
4.학습소감
일반적인 파이썬코드를 사용하면 몇십 몇백줄이 될 코드들이 현재 라이브러리에서 만들어진코드들을 간단하게 사용하는것으로 이용할수있다는 점이 신기하며, 이런만큼 라이브러리에 대해서 더 다양하게 아는만큼 나중의 쓸데없는 시간낭비를 줄일수있다는것을 체감할수 있는 수업이었다.
지금은 강사님이 지정해서 알려주는것으로 바로바로 사용하는것을 이해할수있었지만, 훗날 혼자서 배울때는 시간이 많이 걸릴것이기 때문에, 이런 수업으로 더 많은 정보를 배워갈수 있으면 좋겠다.
※해당 글에서 사용한 모든 이미지는 unsplash.com 에서 가져온 이미지입니다.
