나도 드디어 웹크롤링 한다!
사실 이전에 프로젝트를 진행하며 크롤링을 시도해보았었다. 그냥 100% 구글링에만 의존해서 따라해보았지만 역시나 무작정 따라만하려니 한계가있었다. 정말 구글링 제일 많이 해본 몇 시간이었을거다ㅎㅎ
이젠 크롤링을 제대로 배워보았다. 물론 정말 기초적인 부분만 배웠지만 그래도 한번 차근차근 기록해보려 한다.
웹크롤링? 웹이뭔데?
그전에 웹에 대한 간단한 이해를 해보자!
Web = 전 세계적인 정보 공간
웹브라우저 = 웹페이지를 사용자에게 보여주기 위한 프로그램 - 익스플로러, 크롬, 사파리, 오페라 등
웹페이지 = HTML, CSS, JS의 웹언어로 이루어 져 있음 - 구글, 네이버, 야후 등
HTML, CSS, JS의 차이점은 여기 사이트에 넘 귀엽게 표현되어있다.
BeautifulSoup을 이용해 아주 간단하게 크롤링을 해보자
- requests를 이용해 원하는 웹페이지의 소스코드를 불러온다.
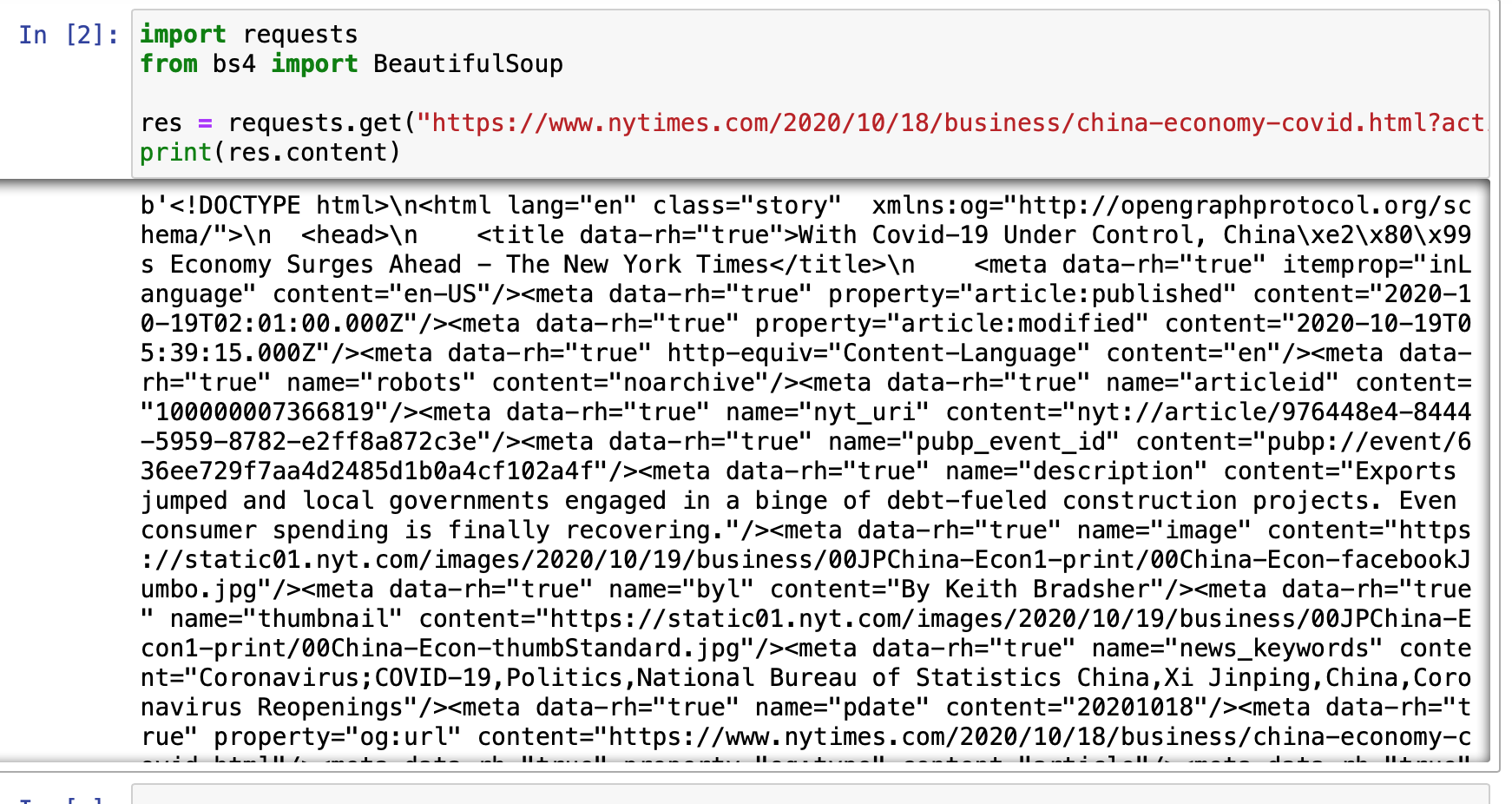
뉴욕타임즈의 기사를 긁어와보았다.
여기서 beautiful soup으로 파싱?해주면 기사 코드를 깔끔하게 가져와줄수있다.
예:
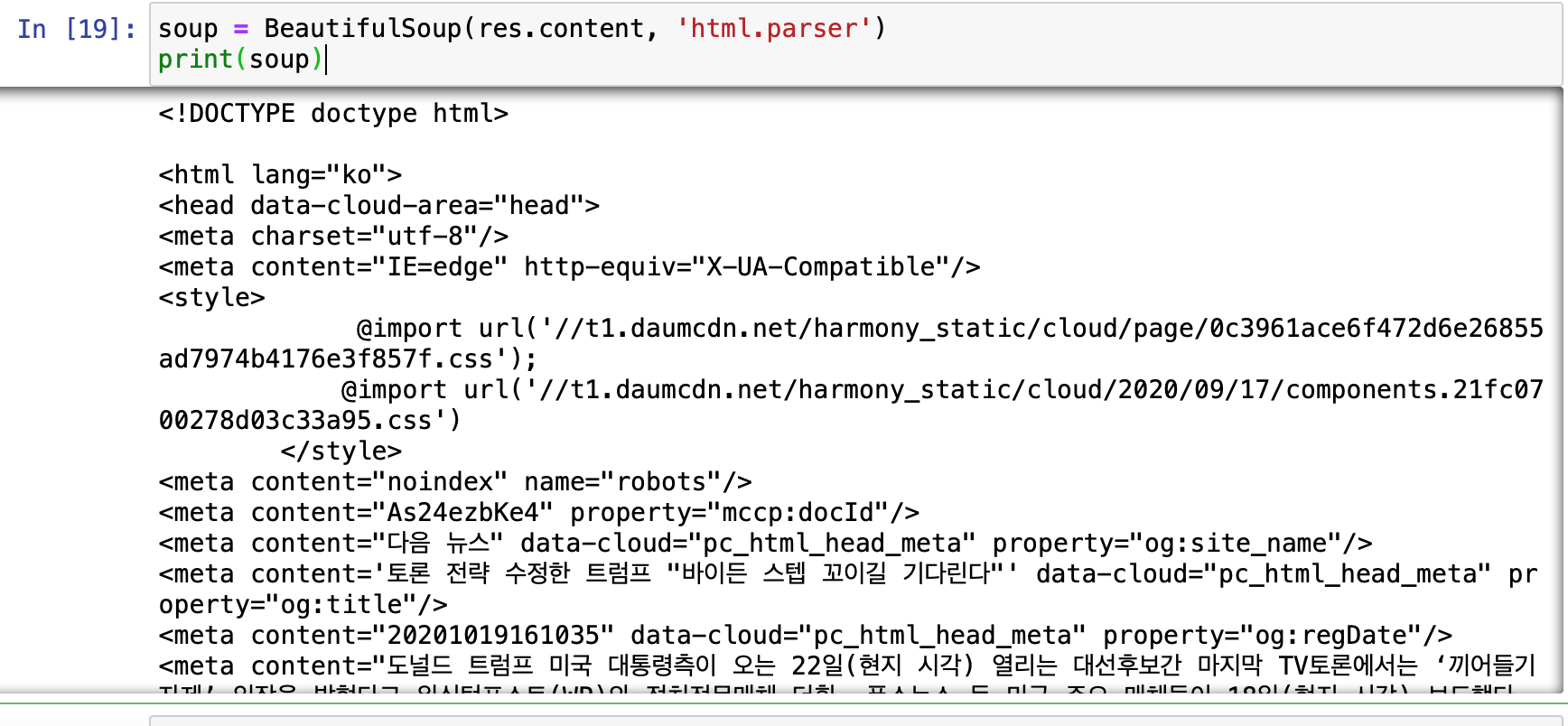
위는 다음뉴스를 크롤링해보았는데, 뉴욕타임즈의 기사를 똑같이 크롤링했을때와 다르게 나오네.. 이유가뭘까🤔
이번엔 네이버 뉴스를 시도해봤더니 이건 아예 server error?! o_O
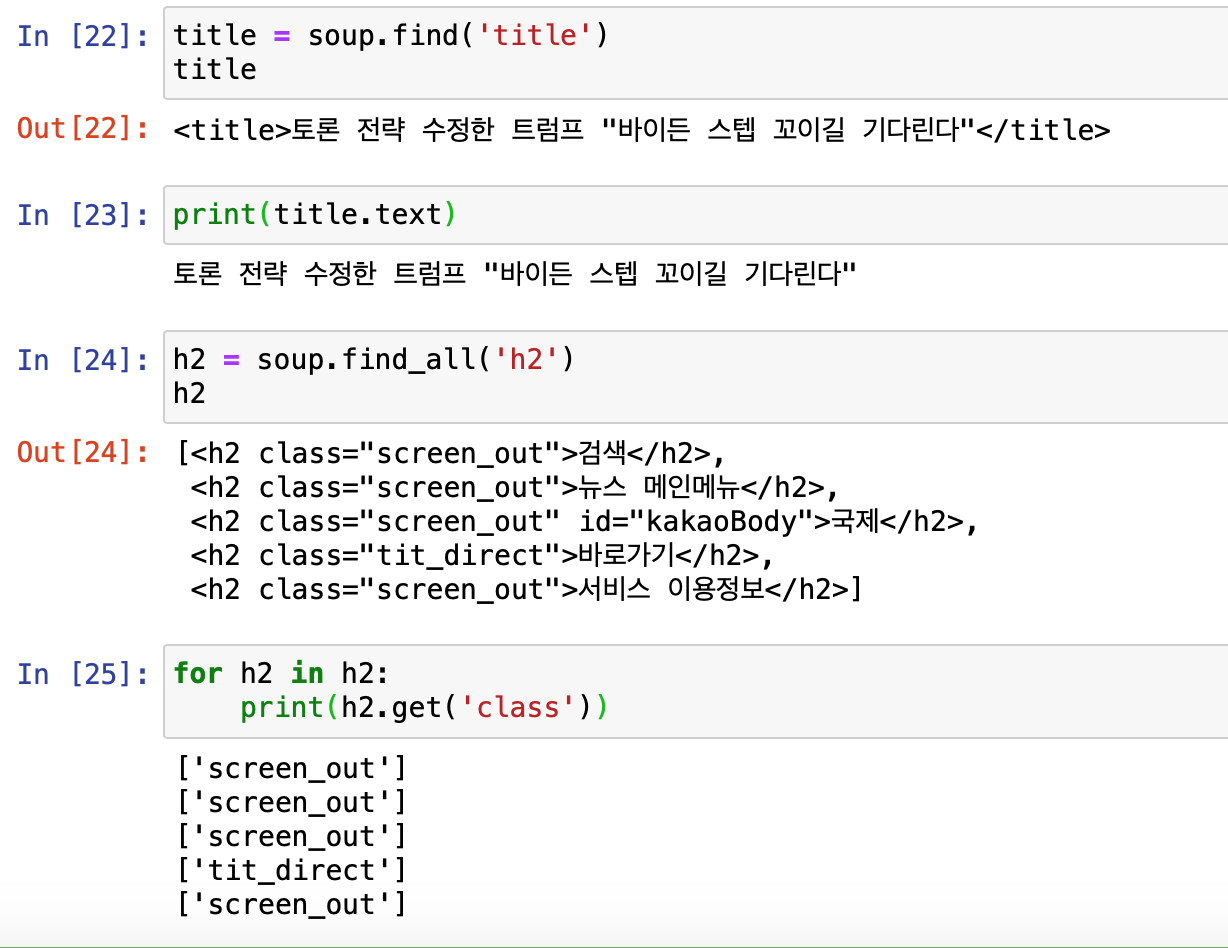
- 필요한 데이터를 뽑아보자 나는 'title'제목 선택
그리고 또 title에서도 필요한 값만(text) 추출!- 전체 코드에서 h2라는 태그를 모두 검색하여 리스트 형태로 저장해준다.
뉴욕타임즈 기사 예시
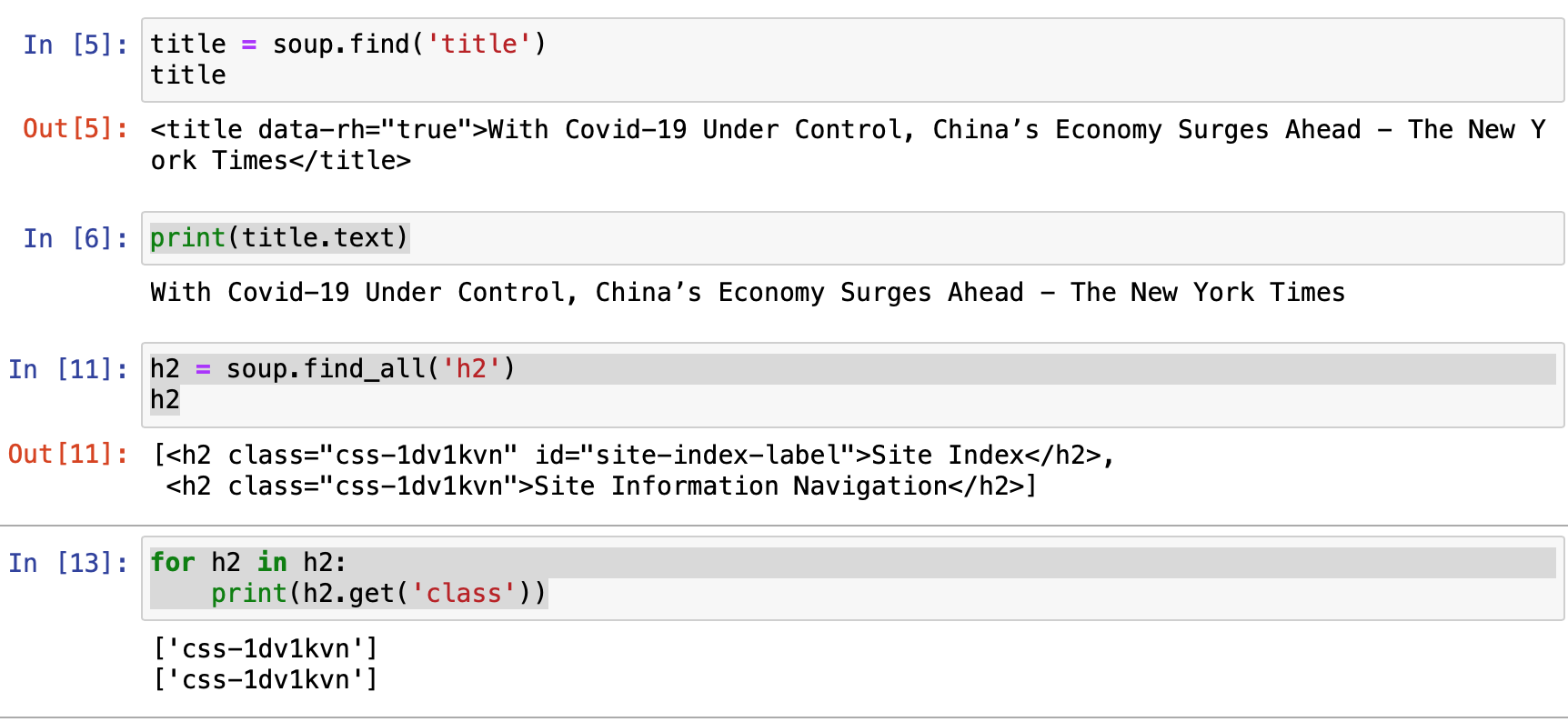
다음 기사 예시
아니.. 다음이 훨씬 깔끔하잖아?! 수업때 예시를 다음뉴스로 사용하여서 그런건지 다음뉴스에 최적화된 크롤링 방법일까?흠🤔
제목을 가져오는 또 다른 방법이있다.
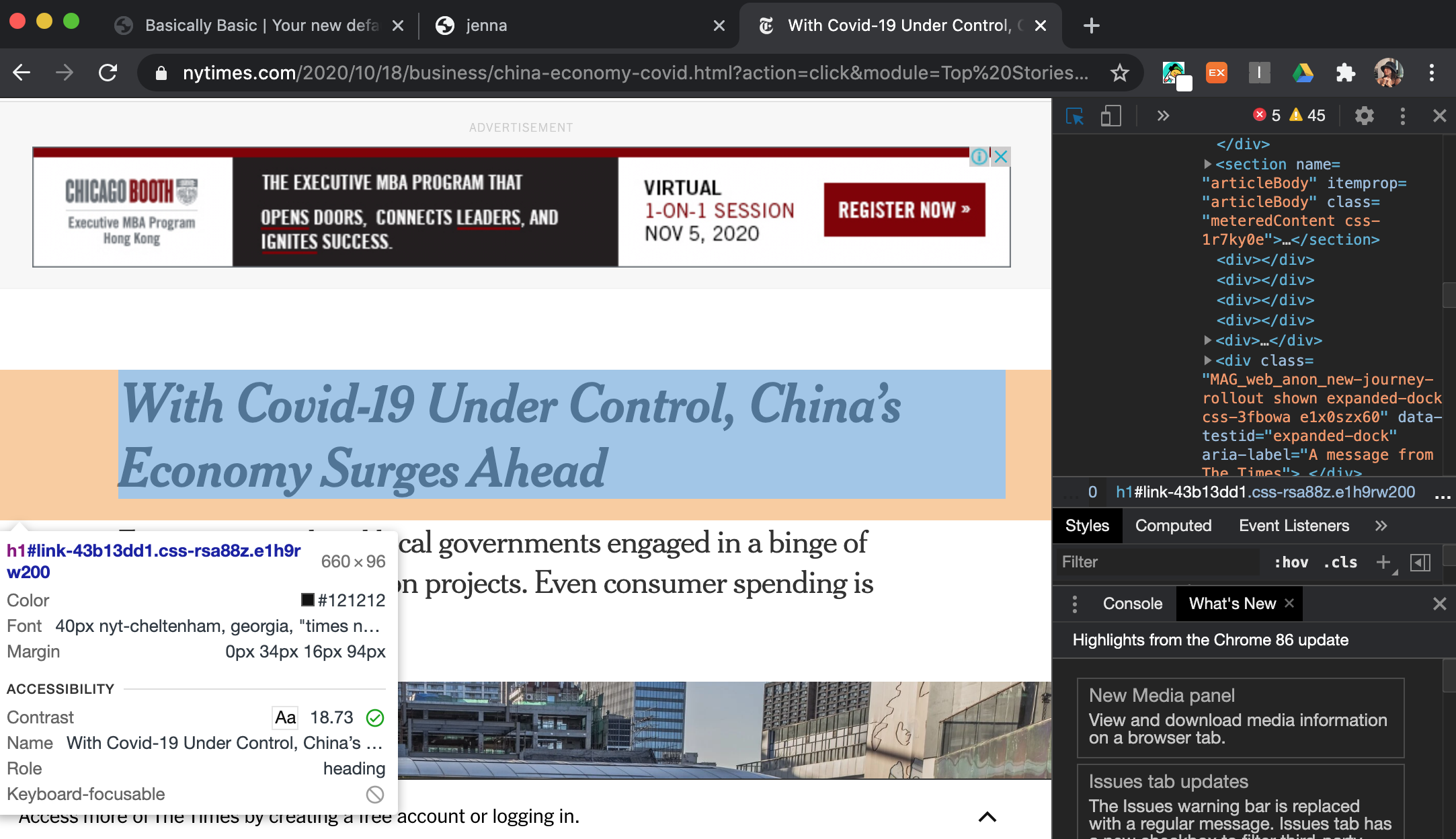
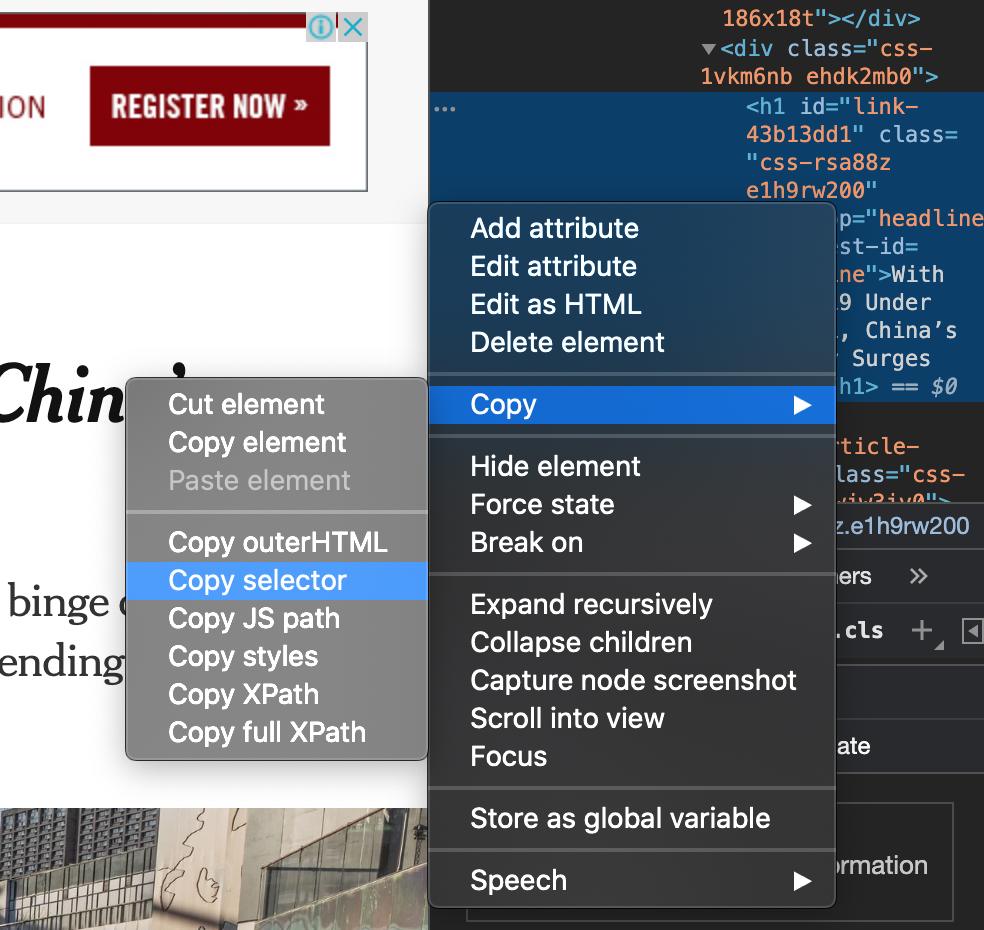
제목부분의 소스코드를 선택 후 copy - copy selector후 
selector를 통해 리스트 형태로 가져와지기때문에 여기서 '제목'만 추출하기위해선 위와 같이 리스트의 0번째 인덱스 = [0] 그 중에서도 text만 추출해주세요! 라고 주문해야한다.
뭐야 웹크롤링 너무 간단하잖아?!?!??!!!!
더 열심히 실습해보며 실전에서도 유용하게 사용해보고싶다.
+이전에 내가 어려움을 겪었던 부분은 뉴스사이트의 1월부터 10월까지의 기사를, 즉 날짜를 지정해서 전부 크롤링해오고 싶었는데 그게 뭔데 이렇게 어려운것이냐..😭 어떻게어떻게 for문짜고해서 시도하려했으나 실패했었다. 조금 더 공부해보면 조만간 쉽게 해볼 수 있을거 같다(그..그렇겠지..?😂)
