
데이터 크롤링(Crawling)이란 자동으로 웹페이지 데이터를 수집하는 행위를 말한다.
❗️ 크롤링을 통해 얻은 정보를 사용할 때 위법을 저지르지 않는지 확인이 필요하다❗️
☑︎ Robots.txt
- 웹 사이트 및 웹 페이지를 수집하는 로봇들의 무단 접근을 방지하기 위해 만들어진 로못 배제 표준/국제 권고안
- 로봇들이 무단으로 웹 사이트 정보를 긁어가거나, 웹 서버에 부하를 줄 수 있기 때문에 로돗들의 무분별한 접근하는 것을 방지하기 위해 마련되었다.
☑︎ User agent
- Robots.txt에 의해 웹 서버에 요청을 보내도 거절 당할 수 있다.
- 우리가 로봇이 아니라는 것을 브라우저에게 알리지 위해 사용되는 사용자 에이전트 정보이다.
크롤링을 진행하기 위해서는 웹페이지의 구성을 알 필요가 있다.
👉🏻 WEB
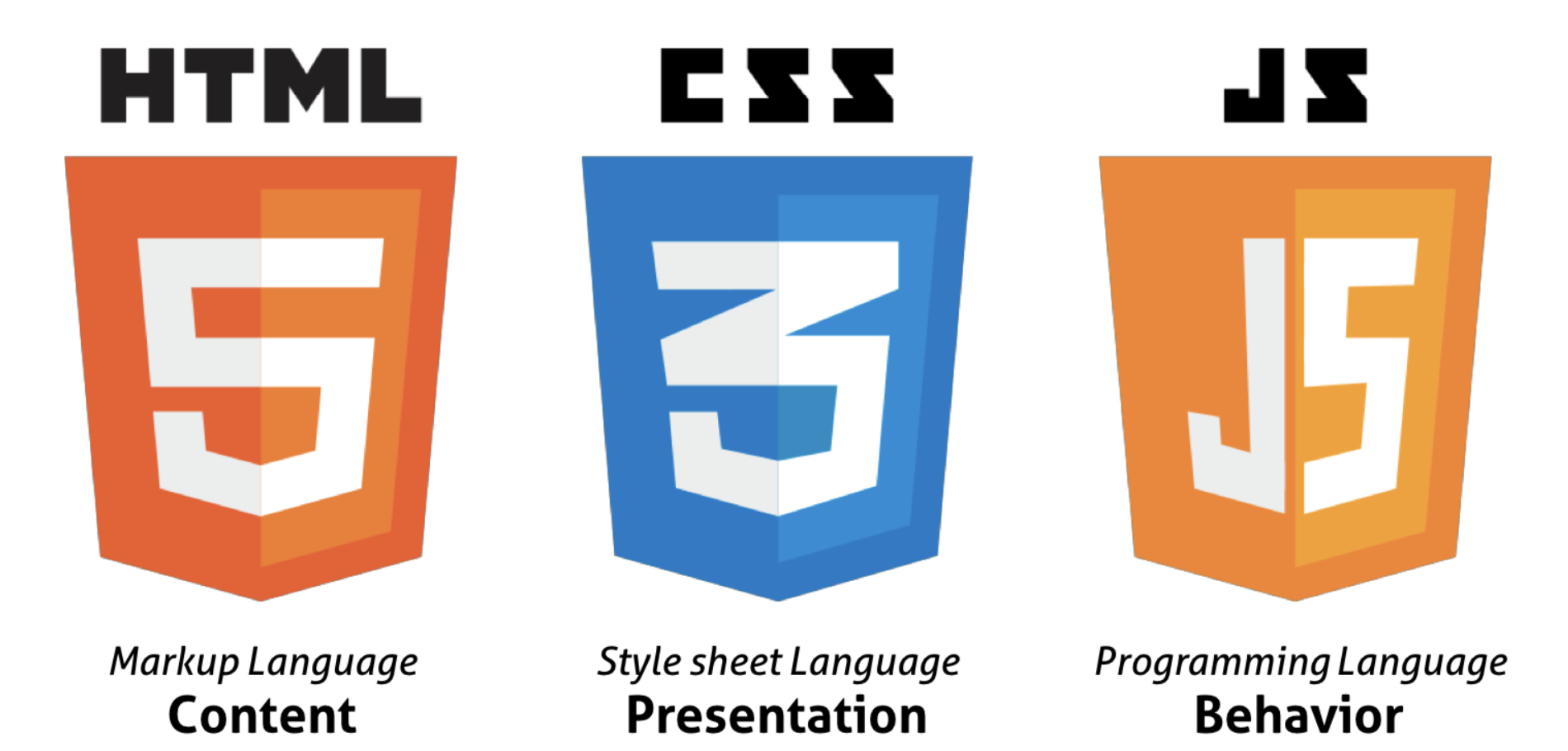
1️⃣ HTML
- 웹 문서의 뼈대
- 웹 브라우저의 여러 내용 중에서 제목과 본문, 이미지, 표와 같은 웹 요소를 알려 주는 역할을 한다.
2️⃣ CSS
- HTML로 만든 내용을 사용자가 알아보기 쉽게 꾸미거나 사용하기 편리하도록 배치할 때 사용한다.
3️⃣ JavaScript
- 동적인 효과를 사용하려면 자바스크립트가 필요하다
- 리액트(React),뷰(Vue) 같은 자바스크립트 프레임워크를 사용한다.
👉🏻 정규표현식(Regular Expression)
정규표현식은 문자열에서 특정 내용을 찾거나 대체 또는 발췌하는 데 사용된다.
1️⃣ 정규식 구성

2️⃣ 정규식 메서드
- match : 문자열 처음부터 정규식과 매칭되는 패턴을 찾아서 반환
- search : 문자열 전체를 검색해서 정규식과 매칭되는 패턴을 찾아서 반환
- findall : 정규식과 매칭되는 모든 문자열을 리스트 객채로 반환
- split : 찾은 정규식 패턴 문자열을 기준으로 문자열을 분리
- sub : 찾은 정규식 패턴 문자열을 다른 문자열로 변경
# ex)
("문자열").match(/regexr/flag)
("문자열").split(/regexr/)3️⃣ 정규식 기호
Dot(.) = 문자 하나(숫자, 특수문자 포함)
- ? : 앞 문자가 0번 또는 1번 표시되는 패턴, 즉 존재여부를 표현
- ( * ) : 앞문자가 0번 또는 그 이상 반복되는 패턴 (괄호는 X)
- ( + ) : 앞문자가 1번 또는 그 이상 반복되는 패턴 (괄호는 X)
- {n} : 앞문자가 n번 반복되는 패턴
- {n , m} : 앞문자가 최소 n번 최대 m번 반복되는 패턴
괄호와 하이픈
-
[ ]안에 들어가는 문자가 들어있는 패턴
ex) [abc]는 a,b,c 중 하나가 들어 있는 패턴을 의미 -
하이픈(-)을 이용하면 알파벳 전체를 나타낼 수 있다
ex) [a-c] == [abc] -
( )는 괄호 안에 있는 단어 자체를 반환
ex) (abc)는 abc가 들어 있는 패턴을 의미
정적 웹페이지 vs 동적 웹페이지
1️⃣ 정적 웹페이지
- 웹 서버에 이미 저장된 파일(html, 이미지 등..)을 전송
- 웹 서버의 데이터 자체의 변화가 없으면 항상 고정된 데이터를 전달한다.
- 요청하는 주체의 변화에 상관없이 같은 데이터를 얻는다.
■ BeautifulSoup을 이용
- requests 모듈을 통해 요청을 보내고 그에 대한 결괏값을 html의 형식으로 받는다.
from bs4 import BeautifulSoup
import requests
import re
res = requests.get("https://www.gmarket.co.kr/n/best")
soup = BeautifulSoup(res.content, 'html.parser')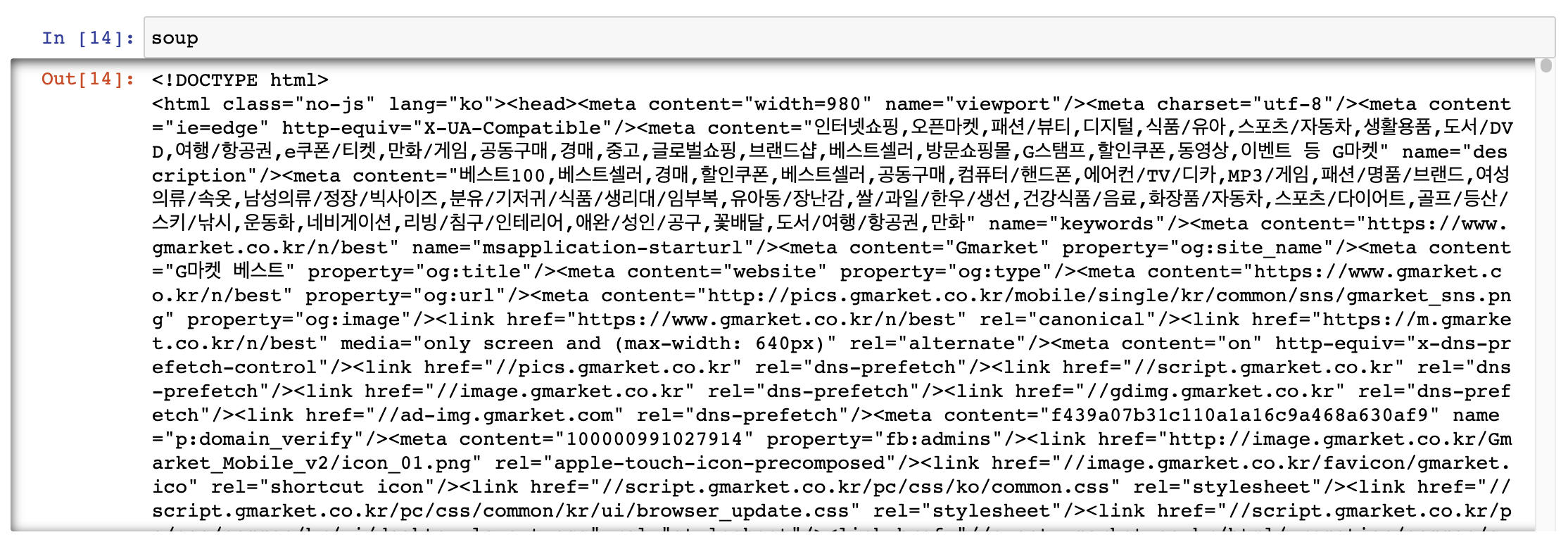
2️⃣ 동적 웹페이지
- 요청한 정보를 처리한 후 제작된 html 페이지를 전송한다.
- 사용자가 요청하는 상황 등에 따라 다른 데이터를 전달한다.
■ Selenium을 이용
- 정적 웹페이지, 동적 웹페이지 모두 크롤링 가능하다.
💻 Selenium
⚙️ 준비과정
■ Chrome의 버전 확인
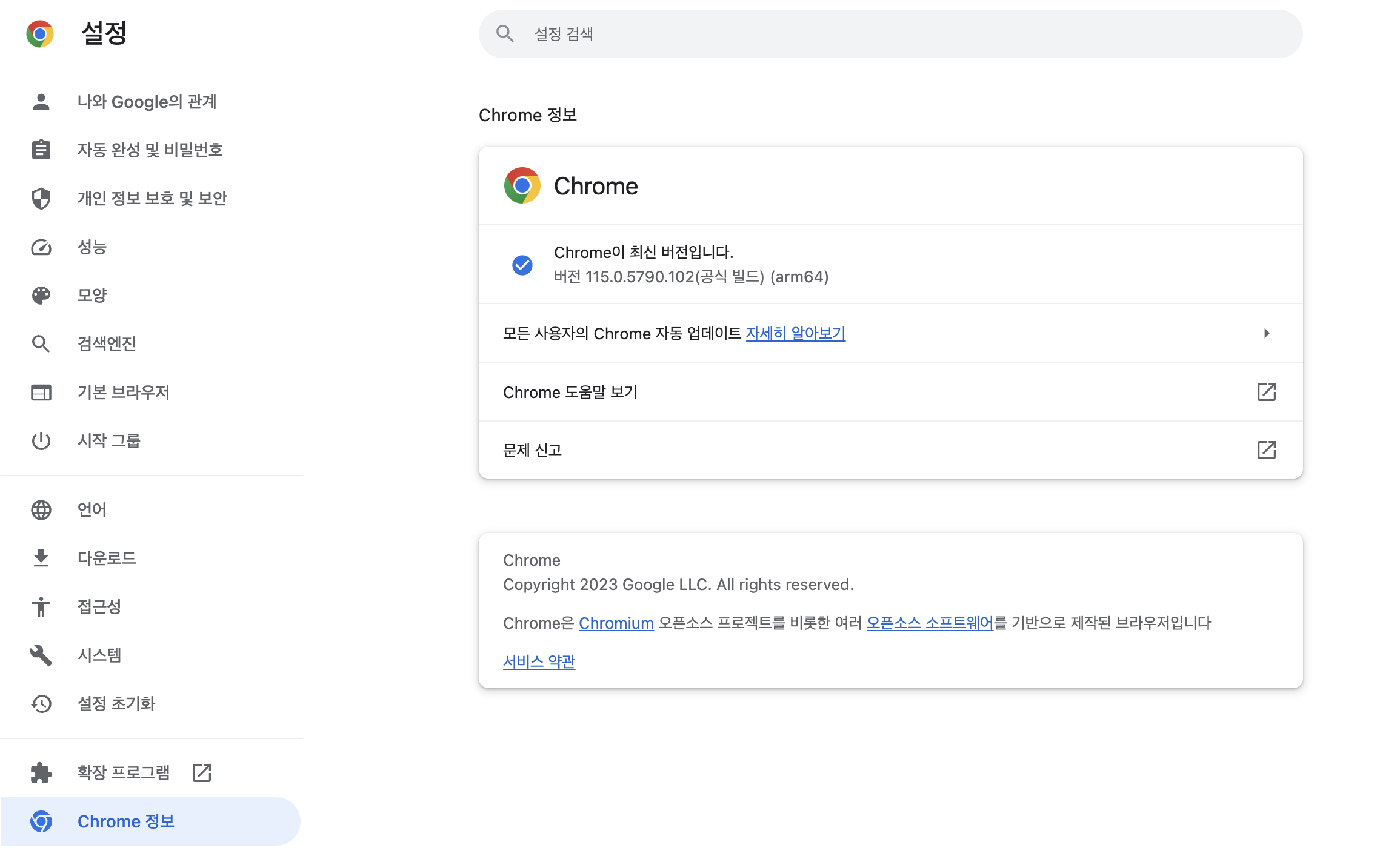
■ https://sites.google.com/chromium.org/driver/downloads?authuser=0 에서 알맞은 버전을 찾아 다운받고 chromedriver.exe파일을 크롤링 파일이 있는 폴더에 복사해서 옮긴다.
💡 Selenium을 이용해 크롤링하기
1️⃣ 라이브러리 설치
> pip install selenium
2️⃣ Robots.txt 확인하기
크롤링 하고자 하는 사이트의 robots.txt를 확인해 접근이 허용되는지 확인!
ex) https://www.gmarket.co.kr/robots.txt

3️⃣ 크롤링하기

💡 목표 : Gmarket에서 손풍기를 검색한 후 상품명, 가격, 만족도 가져오기
👉🏻 WebDriver 객체 생성 및 Gmarket 사이트 열기

👉🏻 검색창에 '손풍기' 입력하기
검색창에 손풍기를 입력하기 위해서는 검색창의 html구조를 파악할 필요가 있다!
(fn+F12을 통해 html구조를 파악할 수 있다)
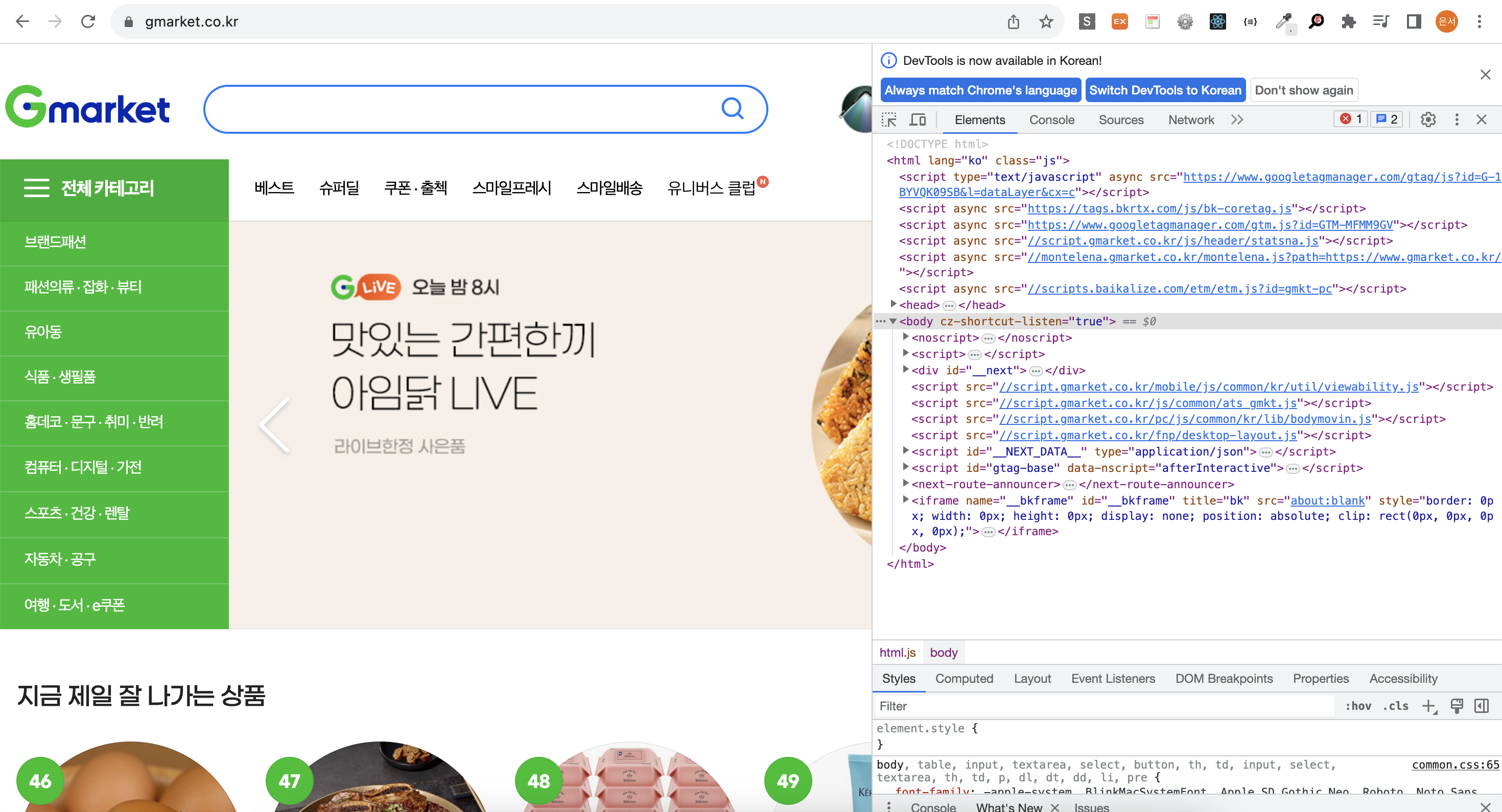
검색창은 input 요소로 구성되어 있으며 keyword라는 name을 가지고 있음을 확인 할 수 있다. 때문에 By.NAME을 통해 input요소를 가져온다.
search_box = driver.find_element(By.NAME, 'keyword')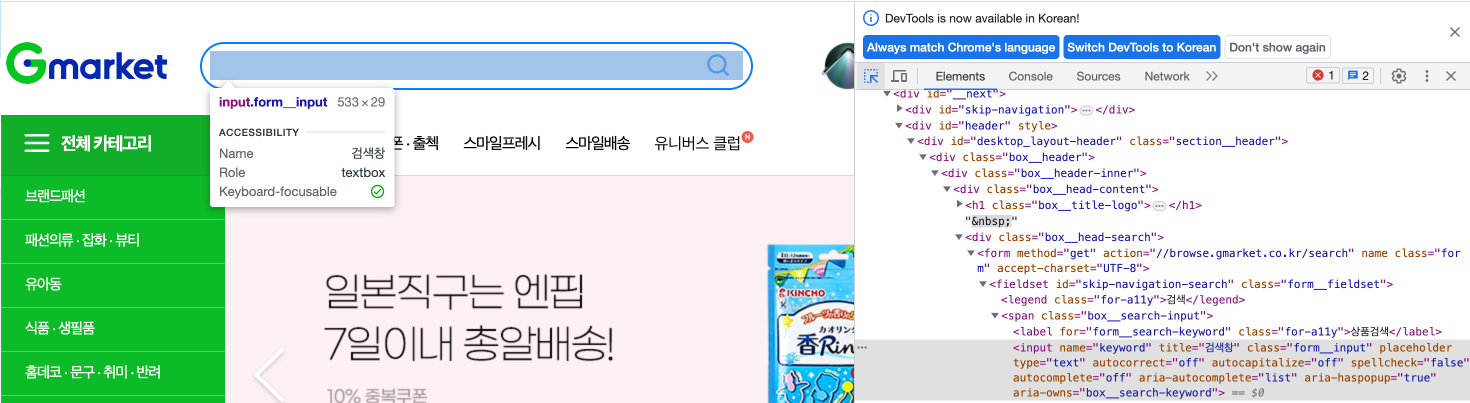
검색어를 입력한 후 Enter키를 눌러 검색을 실행한다.
search_box.send_keys('손풍기')
search_box.send_keys(Keys.RETURN)
# Enter키를 누름과 같음(검색버튼을 불러와 .click()을 통해 같은 기능을 구현할 수 있다.)👉🏻 상품정보 가져오기
By.CSS_SELECTOR를 이용하여 상품정보가 들어있는 박스를 선택한다.
이때 <div class=box__information>인 요소들이 모두 선택되기 때문에 여러개의 상품 정보가 search_results 리스트 안에 들어있다.
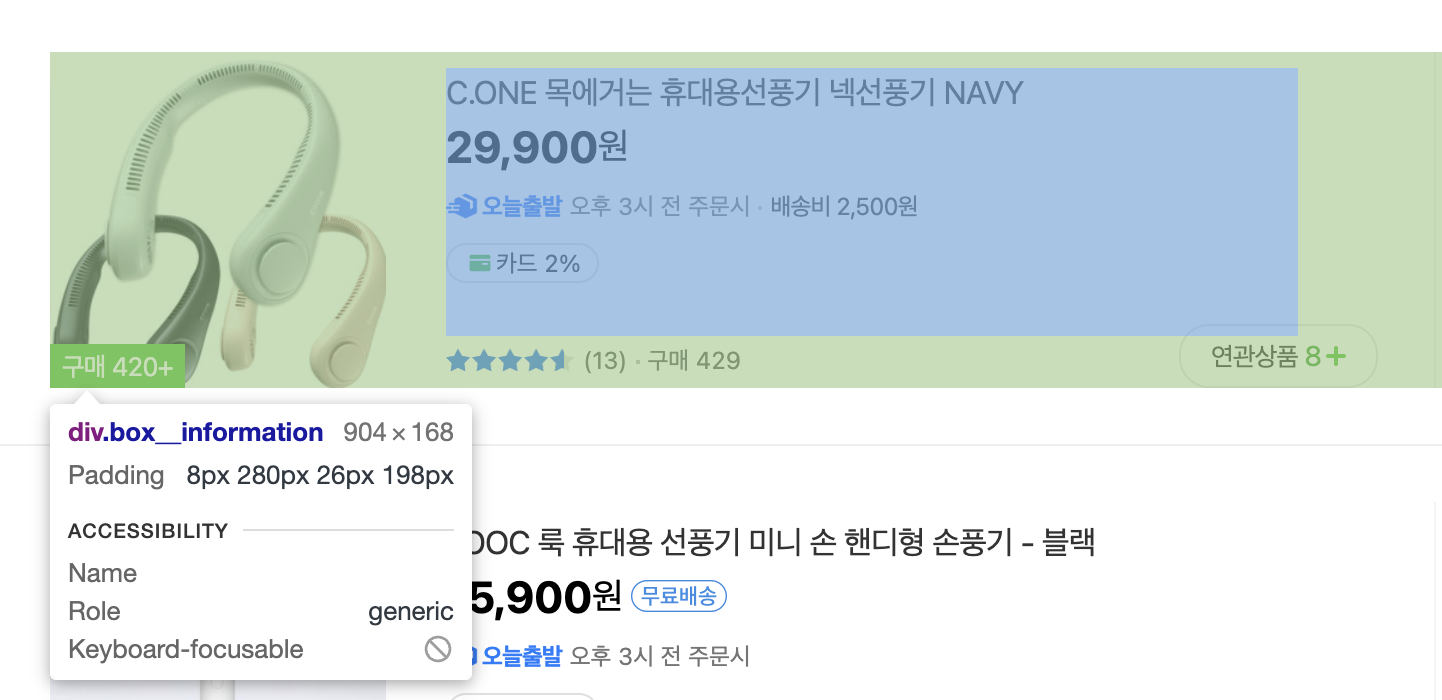
search_results = driver.find_elements(By.CSS_SELECTOR, 'div.box__information')▶︎ 상품명,가격,만족도 가져오기
ex) 원하는 요소의 selector를 확인할 수 있다.
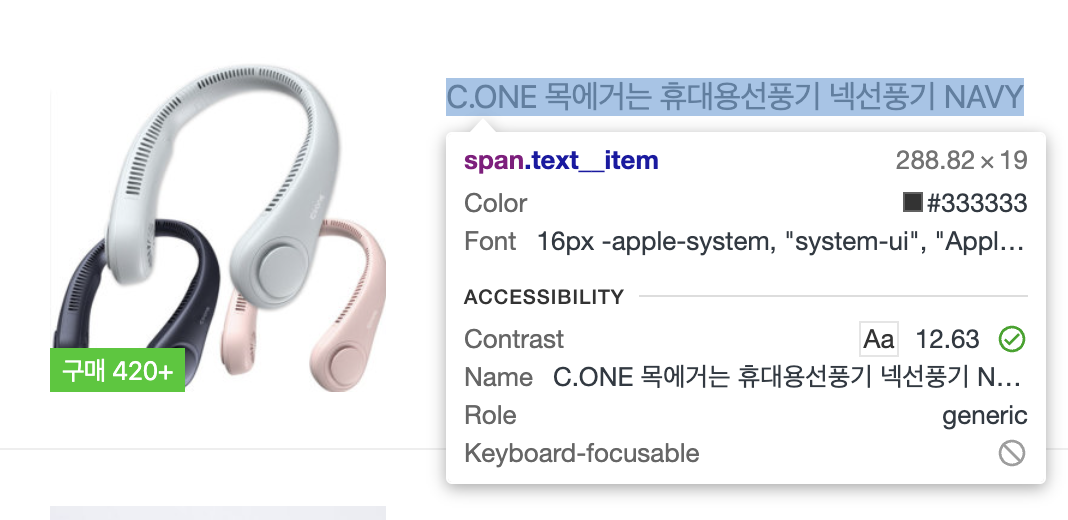
하나의 상품에 접근하기 위해서는 반복문을 통해 search_results 리스트에 있는 상품을 불러와야한다.
for result in search_results:
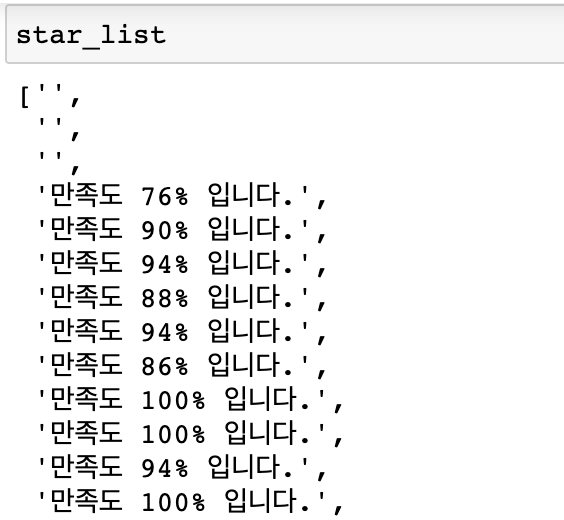
#만족도가 없을 수도 있기 때문에 try except문을 활용 만족도가 없다면 ''로 저장됨
try:
title_element = result.find_element(By.CSS_SELECTOR, 'span.text__item')
price_element = result.find_element(By.CSS_SELECTOR, 'div.box__price-seller > strong')
star_element = result.find_element(By.CSS_SELECTOR, 'span.image__awards-points > span')
title_list.append(title_element.text)
price_list.append(price_element.text)
star_list.append(star_element.text)
except:
pass▶︎ 결과물

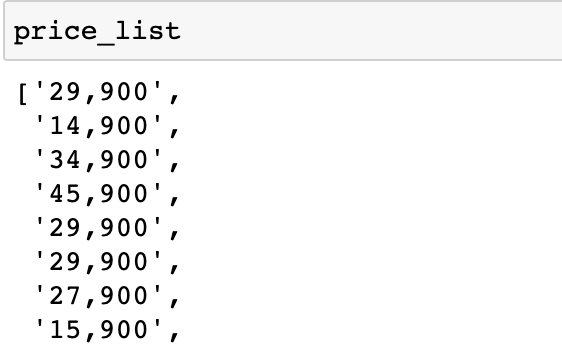
👉🏻 DataFrame으로 만들기
shampoo_df = pd.DataFrame([title_list,price_list,star_list],index=['상품명','판매가','만족도']).T
shampoo_df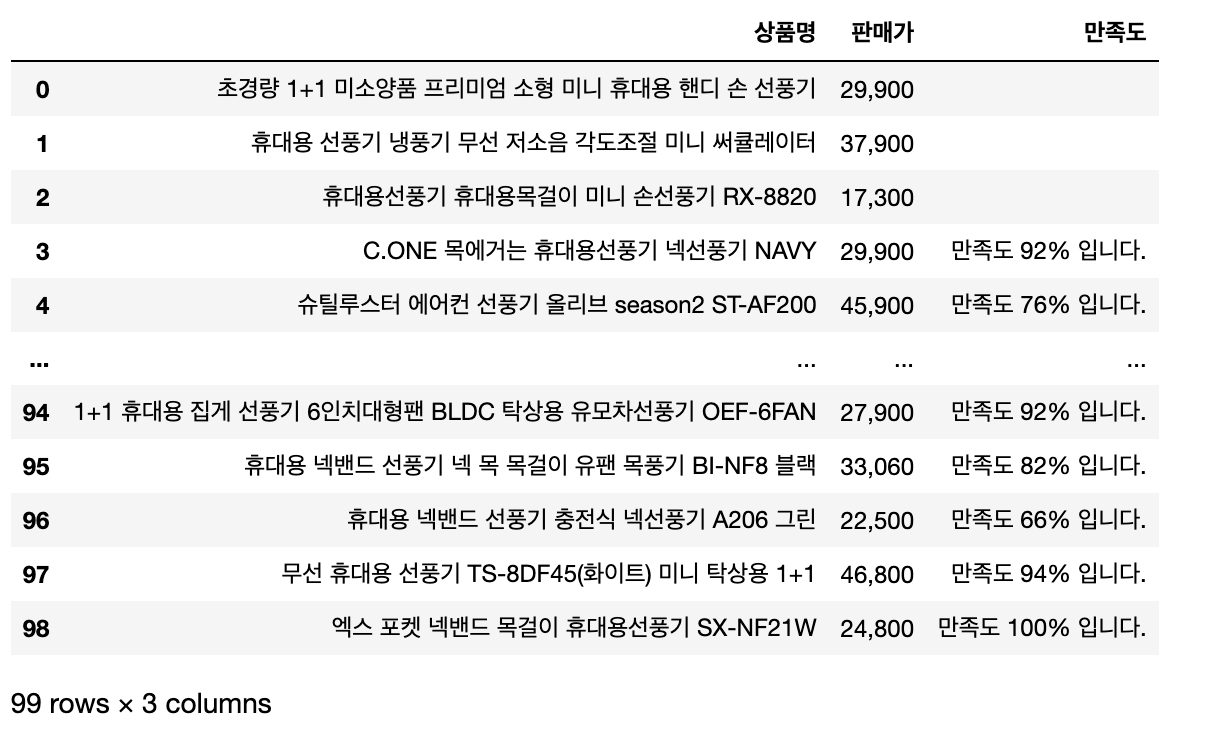
👉🏻 WebDriver 종료하기
✍🏻 Selenium을 이용하여 Melon 크롤링하기(개인 실습)
참고 사이트
