
데이터분석종합반 4일차
스파르타코딩클럽 데이터분석종합반
학습일자: 2022/06/07
강의: 데이터분석종합반
진도: 2-7 ~ 2-15
============================
2-7. 네이버 영화 줄거리로 워드 클라우드 만들기 (1)
import requests # requests라는 패키지를 임포트
import pandas as pd # pandas라는 패키지를 임포트하는데 앞으로 pd로 부르겠음
from bs4 import BeautifulSoup # bs4라는 패키지로부터 BeautifulSoup라는 모듈을 임포트
# 네이버의 크롤링 방지 장치를 우회하기 위함
headers = {'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/89.0.4389.114 Safari/537.36'}
movie_code = 191559 # 211097까지 존재, 191559는 앞서 봤던 영화 '듄'의 코드
movies = requests.get('https://movie.naver.com/movie/bi/mi/basic.naver?code='+str(movie_code), headers=headers)
# html 분석
soup = BeautifulSoup(movies.content, 'html.parser')movie_title = soup.select('#content > div.article > div.mv_info_area > div.mv_info > h3 > a')
movie_genre = soup.select('#content > div.article > div.mv_info_area > div.mv_info > dl > dd:nth-of-type(1) > p > span:nth-of-type(1) > a')
movie_content = soup.select('#content > div.article > div.section_group.section_group_frst > div:nth-of-type(1) > div > div > p')
print(movie_title, movie_genre, movie_content)
위 코드를 실행하면

이렇게 나오는데, 여기서 텍스트만 뽑아내야한다.
제목 코드
movie_title = movie_title[0].text
print(movie_title)[0]은 왜 적는가?
soup.select()는 ()안에 있는 모든 선택자들을 다 불러온다.
print(soup.select())를 통해 보이는 요소는 첫번째 인덱스만 대표적으로 보여주는 것 뿐
그러므로 변수에 데이터를 담을 땐 [0]을 쓰고 그 뒤에 .text를 넣어줘야함
장르 코드
movie_genre_list = []
for genre in movie_genre:
movie_genre_list.append(genre.text)
print(movie_genre_list)위 코드를 실행하면

장르는 왜 빈 리스트를 선언하고 그 안에 넣는가?
예시로 든 듄을 봐도 장르가 여러개임.
movie_genre라는 변수에 soup.select('...')를 통해 데이터를 전부 담았고, 그중에 text를 뽑아서 리스트에 넣고, 그걸 최종데이터로 결정
줄거리 코드
movie_content = movie_content[0].text
print(movie_content)줄거리는 제목과 흡사하므로 그대로 진행

영화 한개를 코드를 통해 크롤링하는 함수 구현
# 영화 한개 크롤링 함수
def crawl(code):
headers = {'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/89.0.4389.114 Safari/537.36'}
movie_code = code # 211097까지 존재
movies = requests.get('https://movie.naver.com/movie/bi/mi/basic.naver?code='+str(movie_code), headers=headers)
soup = BeautifulSoup(movies.content, 'html.parser')
movie_title = soup.select('#content > div.article > div.mv_info_area > div.mv_info > h3 > a:nth-of-type(1)')
movie_genre = soup.select('#content > div.article > div.mv_info_area > div.mv_info > dl > dd:nth-of-type(1) > p > span:nth-of-type(1) > a')
movie_content = soup.select('#content > div.article > div.section_group.section_group_frst > div:nth-of-type(1) > div > div > p')
movie_title = movie_title[0].text
movie_genre_list = []
for genre in movie_genre:
movie_genre_list.append(genre.text)
movie_content = movie_content[0].text
movie_list = [movie_title, movie_genre_list, movie_content]
return movie_list # 크롤링한 내용을 다른 변수에 저장할 수 있도록 리턴!
\xa0는 뭐지? 슬랙에 문의한 상태.
============================
2-8. 네이버 영화 줄거리로 워드 클라우드 만들기 (2)
네이버 영화 만개를 크롤링 할 것이다!
크롤링 코드
def crawl_all():
movie_list_all = [] # 전체 영화 내용을 저장하기 위한 리스트
for i in range(10000, 20001): # 영화 코드 10000 부터 영화 코드 20000 까지 크롤링!
try: # 혹시나 크롤링이 안되더라도 다음 영화 코드로 계속 진행하라는 의미의 try ~ except
movie_list = crawl(i)
movie_list_all.append(movie_list) # 크롤링해온 내용을 리스트에 저장
except:
continue
return movie_list_all # 전체 영화 내용이 담긴 리스트를 리턴그 후 csv파일로 만들 것이다!
movie_list_all = crawl_all()
df = pd.DataFrame(movie_list_all, columns=['Title', 'Genre', 'Content'])
print(df)
df.to_csv('naver_movies.csv')
크롤링 돌리는데만 2시간 30분 걸림
============================
2-9. 네이버 영화 줄거리로 워드 클라우드 만들기 (3)
어제 크롤링 통해서 만든 csv파일을 토대로 수업 진행
import pandas as pd
movies = pd.read_table('naver_movies.csv', sep=',')
movies.dropna(inplace=True)
content_list = movies['Content'].values
print(content_list)
joined_data = ' '.join(content_list)프린트를 제외한 아래 3줄
movies.dropna(inplace=True)
movies.dropna: movies라는 데이터프레임에서 결측치(값이 없는것)를 제외한 값만 가져온다.
inplace: 전에 나왔지만 원본데이터에 영향을 미칠것인가 하는 물음. T면 영향을 주고, F면 안줌(다른 변수에 담을수 있게 해줄 뿐)
movies['Content'].values
1. movies라는 이름을 가진 데이터프레임 변수에서
2. Content라는 컬럼을 가진 행에서
3. value값만 쫙 뽑아서 리스트화한다.
joined_data = ' '.join(content_list)
1. content_list라는 변수 안에 있는 요소들을
2. ' '로 연결하면서 join한다. 리스트 안의 수많은 요소들을 문자열로 만드는것.
3. 왜? 워드클라우드를 만들려면 리스트 형태를 하나의 문자열로 만들어야 하기 때문.

joind_data는 엄청나게 긴 문자열이기 때문에 0번째부터 10번째까지만 시험 삼아 출력해봄. 잘 되네요.
하나의 문자열로 합쳐졌다! 이게 중요한거.
워드 클라우드 코드
from wordcloud import WordCloud
import matplotlib.pyplot as plt # 한글폰트 세팅할 때 불러왔었던 패키지!
# 영화 줄거리의 워드클라우드
fontpath = '/usr/share/fonts/truetype/nanum/NanumBarunGothic.ttf'
plt.figure(figsize = (15,15))
wc = WordCloud(max_words = 10000 , width = 1600 , height = 800, font_path = fontpath).generate(joined_data)
plt.imshow(wc, interpolation = 'bilinear')기억이 잘 안나니까 지난 강의 복습 해야겠다.
워드클라우드 만들때 반드시 필요한 기본 코드(한글폰트 등등)
import matplotlib as mpl
import matplotlib.pyplot as plt
%config InlineBackend.figure_format = 'retina'
!apt -qq -y install fonts-nanum
import matplotlib.font_manager as fm
fontpath = '/usr/share/fonts/truetype/nanum/NanumBarunGothic.ttf'
font = fm.FontProperties(fname=fontpath, size=9)
plt.rc('font', family='NanumBarunGothic')
mpl.font_manager._rebuild()from wordcloud import WordCloud
import matplotlib.pyplot as plt # 한글폰트 세팅할 때 불러왔었던 패키지!
# 영화 줄거리의 워드클라우드
fontpath = '/usr/share/fonts/truetype/nanum/NanumBarunGothic.ttf'
plt.figure(figsize = (15,15))
wc = WordCloud(max_words = 10000 , width = 1600 , height = 800, font_path = fontpath).generate(joined_data)
plt.imshow(wc, interpolation = 'bilinear')
짜잔. 워드클라우드가 나왔다.
텍스트 마이닝(명사단위만 남기거나, 불용어를 제거하는) 작업이 없어서 별 의미없는게 제일 많이 나온다.
명사만 뽑아오는 텍스트 마이닝 코드
!pip install konlpy # konlpy 패키지 설치
from konlpy.tag import Okt # Okt 모듈 불러오기
tokenizer = Okt() # tokenizer 라는 이름으로 Okt 모듈 사용!불용어 제거, 토큰화 작업
stop_words = ['자신의', '그는', '그러나', '결국', '한편', '그들은', '그들의', '함께', '자신', '그', '그리고', '그들', '그녀', '다시', '위해', '아버지', '사람', '때문'] # 나만의 불용어 정의
movies['Content'] = movies['Content'].apply(tokenizer.nouns) # 토큰화 진행 (명사 단위로 나누어 놓아야 불용어인지 아닌지 판별이 가능)
movies['Content'] = movies['Content'].apply(lambda x: [item for item in x if item not in stop_words and len(item) > 1]) # 불용어 제거apply함수는 인자로 들어있는 함수를 각각의 행마다 실행하는 것이다.

에러가 뜬다....뭐지....

이 부분부터 재실행하니까 잘 된다.

데이터 마이닝 한 자료.
데이터마이닝한 자료를 hstack을 통해 하나로 합친다.
import numpy as np
print(movies['Content'].values)
content_list = np.hstack(movies['Content'].values)
합치기 전과 합친 후의 데이터 비교. 각각의 리스트들이 합쳐졌다.
이제 리스트의 각 요소들을 하나로 합쳐서 문자열 한개로 만든다.
joined_data = ' '.join(content_list)워드클라우드를 다시 생성해준다.
from wordcloud import WordCloud
import matplotlib.pyplot as plt # 한글폰트 세팅할 때 불러왔었던 패키지!
# 영화 줄거리의 워드클라우드
fontpath = '/usr/share/fonts/truetype/nanum/NanumBarunGothic.ttf'
plt.figure(figsize = (15,15))
wc = WordCloud(max_words = 10000 , width = 1600 , height = 800, font_path = fontpath).generate(joined_data)
plt.imshow(wc, interpolation = 'bilinear')
출력된 워드클라우드
============================
2-10. 영화 줄거리를 이용해서 장르 분류해보기 (1) - 기초 개념
기초 개념 설명인데...솔직히 뭐라는지 모르겠다. 패스!
============================
2-11. 영화 줄거리를 이용해서 장르 분류해보기 (2) - 데이터
데이터가 어떻게 이뤄져있는지 탐색하는 시간
캐글IMDb장르분류데이터 (test)
캐글IMDb장르분류데이터 (train)
두개를 다운받아 코랩에 업로드 후, 코드 작성
import pandas as pd
train = pd.read_table('train_data.text', sep=":::", names=['Index', 'Title', 'Genre', 'Content'])
test = pd.read_table('test_data_solution.text', sep=":::", names=['Index', 'Title', 'Genre', 'Content'])
train.head(3) # train의 상위 3개만 출력
잘 처리된걸 볼 수 있다.
각각의 데이터가 몇개의 행으로 이뤄졌는지 확인
train.info()
test.info()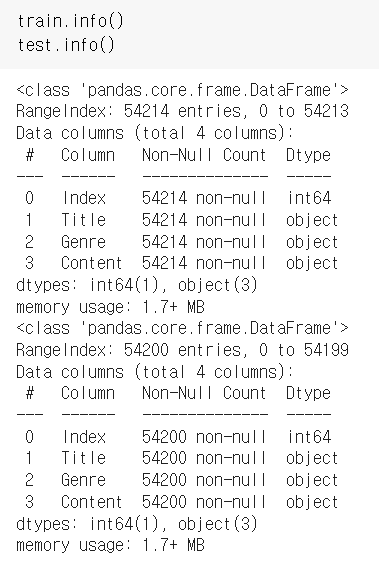
train은 54214, test는 54200개의 행으로 이뤄져있음
장르가 총 몇개 있나?
train['Genre'].unique()
꽤 다양하군..총 27개
줄거리가 뭐냐에 따라서 장르가 변경된다
-> 줄거리 = 독립변수, 장르 = 종속변수
#훈련데이터의 독립 변수 x는 줄거리
#훈련데이터의 종속 변수 y는 장르
y_train = train['Genre']
x_train = train['Content']
#테스트데이터의 독립 변수 x는 줄거리
#테스트데이터의 종속 변수 y는 장르
#테스트데이터의 장르는 안정해졌음
x_test = test['Content']장르는 숫자화, 줄거리는 벡터화가 필요
mapping = {' drama ':1, ' thriller ':2, ' adult ':3, ' documentary ':4, ' comedy ':5,
' crime ':6, ' reality-tv ':7, ' horror ':8, ' sport ':9, ' animation ':10,
' action ':11, ' fantasy ':12, ' short ':13, ' sci-fi ':14, ' music ':15,
' adventure ':16, ' talk-show ':17, ' western ':18, ' family ':19, ' mystery ':20,
' history ':21, ' news ':22, ' biography ':23, ' romance ':24, ' game-show ':25,
' musical ':26, ' war ':27}
y_train = y_train.replace(mapping)
y_test = y_test.replace(mapping)y_train.head(3)을 입력하면

이렇게 나온다.
============================
2-12. 영화 줄거리를 이용해서 장르 분류해보기 (3) - 벡터화
행렬 = 벡터와 유사한 의미로 사용
# DTM, TFIDF 생성 코드
from sklearn.feature_extraction.text import CountVectorizer
from sklearn.feature_extraction.text import TfidfTransformer
corpus = [
'you know I want your love',
'I like you',
'what should I do ',
]
vector = CountVectorizer() # DTM 벡터화를 위한 객체 생성
x_train_dtm = vector.fit_transform(corpus) # 해당 단어들을 벡터화 진행
print(x_train_dtm.toarray()) # 벡터가 어떻게 생겼는지 확인
tfidf_transformer = TfidfTransformer() # tfidf 벡터화를 위한 객체 생성
tfidfv = tfidf_transformer.fit_transform(x_train_dtm) # x_train_dtm에 대해서 벡터화 진행
print(tfidfv.toarray()) # 벡터가 어떻게 생겼는지 확인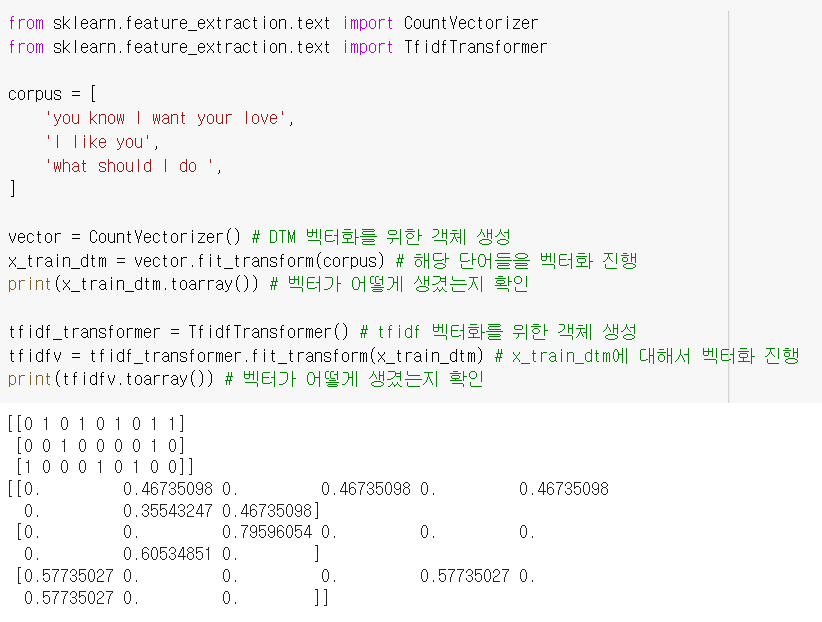
여기서 잠깐
transform() 함수란?
벡터값을 저장하지 않음. 학습하지 않는다. (테스트데이터에 사용)
fit_transfom() 함수란?
데이터를 계속 저장하면서 벡터화 진행 (훈련데이터에 사용)
============================
2-13. 영화 줄거리를 이용해서 장르 분류해보기 (4) - 머신러닝
40분짜리 영상.... 나 죽어
# 예측모델에 필요한 모듈 임포트
from sklearn.naive_bayes import MultinomialNB #다항분포 나이브 베이즈 모델
from sklearn.linear_model import LogisticRegression
from sklearn.svm import LinearSVC
from sklearn.metrics import accuracy_score #정확도 계산
from sklearn.feature_extraction.text import CountVectorizer
from sklearn.feature_extraction.text import TfidfTransformer============================
2-13. 영화 줄거리를 이용해서 장르 분류해보기 (5) - 번외
# 테스트용 내가 만든 줄거리 입력해보기
x_test_dtm = dtmvector.transform(['(내가 만든 줄거리)']) #테스트 데이터를 DTM으로 변환
tfidfv_test = tfidf_transformer.transform(x_test_dtm) #DTM을 TF-IDF 행렬로 변환
predicted = lr.predict(tfidfv_test) #테스트 데이터에 대한 예측
print(predicted)# 불용어 제거한 후 예측 진행하기
from sklearn.feature_extraction.text import CountVectorizer
from sklearn.feature_extraction.text import TfidfTransformer
# dtm, tfidf 벡터 생성을 위한 객체 생성
dtmvector = CountVectorizer(stop_words="english") # 영어 스탑워드를 제거해달라는 뜻!
tfidf_transformer = TfidfTransformer()
# x_train에 대해서 dtm, tfidf 벡터 생성
x_train_dtm = dtmvector.fit_transform(x_train)
tfidfv = tfidf_transformer.fit_transform(x_train_dtm)
# 나이브 베이즈 분류기로 학습 진행
mod = MultinomialNB()
mod.fit(tfidfv, y_train)
# x_test에 대해서 dtm, tfidf 벡터 생성
x_test_dtm = dtmvector.transform(x_test) #테스트 데이터를 DTM으로 변환
tfidfv_test = tfidf_transformer.transform(x_test_dtm) #DTM을 TF-IDF 행렬로 변환
predicted = mod.predict(tfidfv_test) #테스트 데이터에 대한 예측
print("정확도:", accuracy_score(y_test, predicted)) #예측값과 실제값 비교지금까지는 맛보기였다! 다음주부터 복습도 하고 판다스 함수도 배운다
============================
2-15. 2주차 끝 & 숙제 설명
# 숙제 코드
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
df = pd.read_table('https://raw.githubusercontent.com/bab2min/corpus/master/sentiment/naver_shopping.txt', names=['ratings', 'reviews'])
print(df['reviews'].nunique())
# 중복 샘플 제거
df.drop_duplicates(subset=['reviews'], inplace=True)
df['ratings'].value_counts().plot(kind = 'bar')
print(df.groupby('ratings').size().reset_index(name = 'count'))
###########################
!pip install konlpy
from konlpy.tag import Okt
tokenizer = Okt()
df['tokenized'] = df['reviews'].apply(tokenizer.nouns)
# 리뷰 점수가 4~5점이면 1, 리뷰 점수가 1~2면 0의 값을 줍니다.
df['label'] = np.select([df.ratings > 3], [1], default=0)
df.head()
positive_reviews = np.hstack(df[df['label']==1]['tokenized'].values) #개수 셀 때, 워드클라우드 만들 때 사용
negative_reviews = np.hstack(df[df['label']==0]['tokenized'].values)
############################
#숙제코드 이어서
from collections import Counter
positive_reviews_word_count = Counter(positive_reviews)
print(positive_reviews_word_count.most_common(20))
negative_reviews_word_count = Counter(negative_reviews)
print(negative_reviews_word_count.most_common(20))
from wordcloud import WordCloud
#긍정 리뷰의 워드 클라우드
plt.figure(figsize = (15,15))
fontpath = '/usr/share/fonts/truetype/nanum/NanumBarunGothic.ttf'
temp_data = ' '.join(positive_reviews)
wc = WordCloud(max_words = 2000, width = 1600, height = 800, font_path = fontpath).generate(temp_data)
plt.imshow(wc, interpolation = 'bilinear')
#부정 리뷰의 워드 클라우드
plt.figure(figsize = (15,15))
fontpath = '/usr/share/fonts/truetype/nanum/NanumBarunGothic.ttf'
temp_data = ' '.join(negative_reviews)
wc = WordCloud(max_words = 2000, width = 1600, height = 800, font_path = fontpath).generate(temp_data)
plt.imshow(wc, interpolation = 'bilinear')
긍정리뷰 워드클라우드

부정리뷰 워드클라우드
