데이터분석종합반 4주차
스파르타코딩클럽 데이터분석종합반
강의: 데이터분석종합반
학습일자: 2022/06/23 ~ 2022/06/
============================
4-1. 4주차에 배울 것
머신러닝(회귀) - 2주차에 배운 머신러닝과는 무엇이 다른지?
자전거 수요 예측과정(상관관계분석, 시각화, 예측)
============================
4-2. 선형 회귀 기초
선형 회귀란 무엇인가? 1,2주차에도 공부했다고 한다....언제지
y = wx + b
x = 독립변수. 이게 변하면 다른 변수도 변한다
y = 종속변수. x의 변화에 의해 y가 변한다
b = 편향 (절편, 상수)
w = 가중치 (기울기)
단순 선형 회귀 = 한가지 요인만 결과에 영향을 주는, 직선 하나만 그어지는 예측법
다중 선형 회귀 = 여러가지가 영향을 준다.
============================
4-3. 회귀와 분류의 차이
**회귀**라는건 위에서 본 것처럼, 성적/점수라는 특정한 수치를 추정하는 방식을 뜻합니다.공부시간/학교와의 거리 등으로 성적을 예측하는 것, 집의 평수/방의 개수 등으로 집의 가격을 예측하는 것이 회귀입니다.
**분류**라는건 2주차 때 봤던 것처럼, 장르/감정 같은 특정한 범주/클래스를 추정하는 방식을 뜻합니다.줄거리로 장르를 예측하는 것, 리뷰 내용으로 긍정/부정 여부를 예측하는 것이 분류입니다.
회귀는 기존 데이터에서 없었던 결과값이 예측값으로 나올 수 있다.
(공부 시간과 성적의 상관관계에서 성적이 1점, 2점, 3점 등등 그 예측값이 많이 나올 수 있을 것이다.)
분류는 기존 데이터에 있던 클래스/범주가 예측값으로 나온다.
(2주차 긍정/부정리뷰 예측하는것도 이미 긍정/부정의 범주 안에 있다.)
회귀 방법: 선형회귀, 릿지회귀, 라쏘회귀 방법 사용
분류 방법: 로지스틱회귀, svm, 나이브베이즈분류기 등의 방법 사용
회귀 평가: 예측값과 실제 결과값의 오차를 토대로 정확도를 구함
분류 평가: F1-Score/Precision/Recall 등의 지표
============================
4-4. sckit-learn 패키지를 사용한 선형 회귀분석
#선형회귀 분석 실습데이터
import numpy as np
X = np.array([[70,85,11],[71,89,18],[50,80,20],[99,20,10],[50,10,10]]) # 중간, 기말, 가산점
y = np.array([73,82,72,57,34]) # 최종 성적
from sklearn.linear_model import LinearRegression
lr = LinearRegression()
lr.fit(X, y) #.fit() = 학습시킨다
LinearRegression()으로 모델(클래스 객체)을 선언한 뒤에fit()을 통해서 학습시킵니다. 여기서 머신 러닝 용어로 '학습'이라함은 입력과 출력으로부터 가중치와 편향의 값을 찾아낸다는 의미입니다. 현재 하나의 샘플(sample)당 입력이 중간 고사, 기말 고사, 가산점으로 3개의 입력을 가지고 있습니다. 즉, 가중치가 3개 존재해야 합니다. 선형 회귀 수식으로는 다음과 같습니다.(샘플(sample)은 전체 데이터 중 하나를 콕 집어 말할 때 쓰이는 용어입니다.) - 강의자료 중 -
lr.coef_ : 가중치 값들을 확인할 수 있다.
lr.intercept_: 편향 값 확인
선형회귀분석 기초 코드
# 선형회귀분석 기초 코드
import numpy as np
from sklearn.linear_model import LinearRegression
lr = LinearRegression()
lr.fit(x, y)
lr.coef_
lr.intercept_lr = LinearRegression() < lr에 함수를 넣어서 내부함수를 사용
lr.fit(x, y) < lr(=LinearRegression())에 들어있는 내부함수 중 fit을 사용해 분석 시작
lr.coef < 가중치 값(위 설명의 w)들을 확인
lr.intercept < 편향 값(위 설명의 b) 확인
============================
4-5. 자전거 수요 예측하기 - 데이터 준비
데이터가 어떻게 이뤄져있는지
결측치는 없는지
정보는 어떻게 되는지 확인해야함
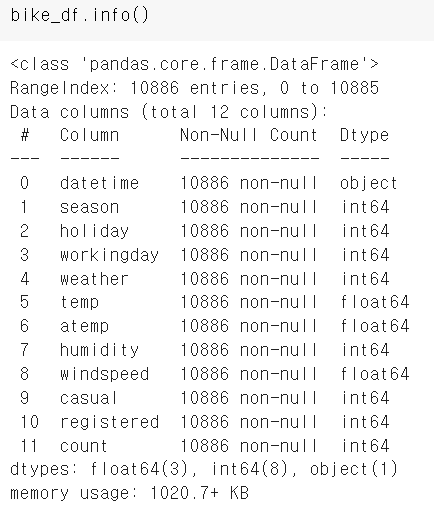
자료형을 변경하는 방법(문자열->날짜형)
pd.to_datetime
예) bike_df['datetime'] = bike_df.datetime.apply(pd.to_datetime)
.apply() = 괄호 안에 들어있는 어떤 함수를 각 행마다 적용시킴
# 적용해보기
bike_df['datetime'] = bike_df['datetime'].apply(pd.to_datetime)
bike_df.info()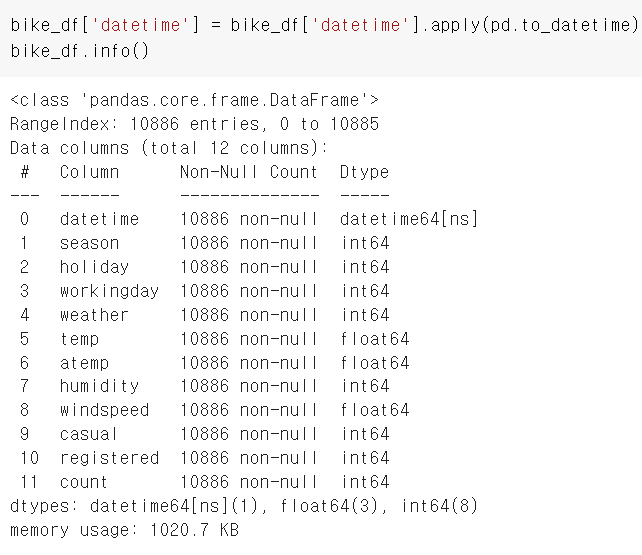
날짜형으로 변경 후 연,월,일,시,분,초 단위로 데이터 추출 후 새로운 열에 저장하기
bike_df["year"] = bike_df["datetime"].dt.year # 연만 추출
bike_df["month"] = bike_df["datetime"].dt.month # 월만 추출
bike_df["day"] = bike_df["datetime"].dt.day # 일만 추출
bike_df["hour"] = bike_df["datetime"].dt.hour # 시간만 추출
bike_df.shape

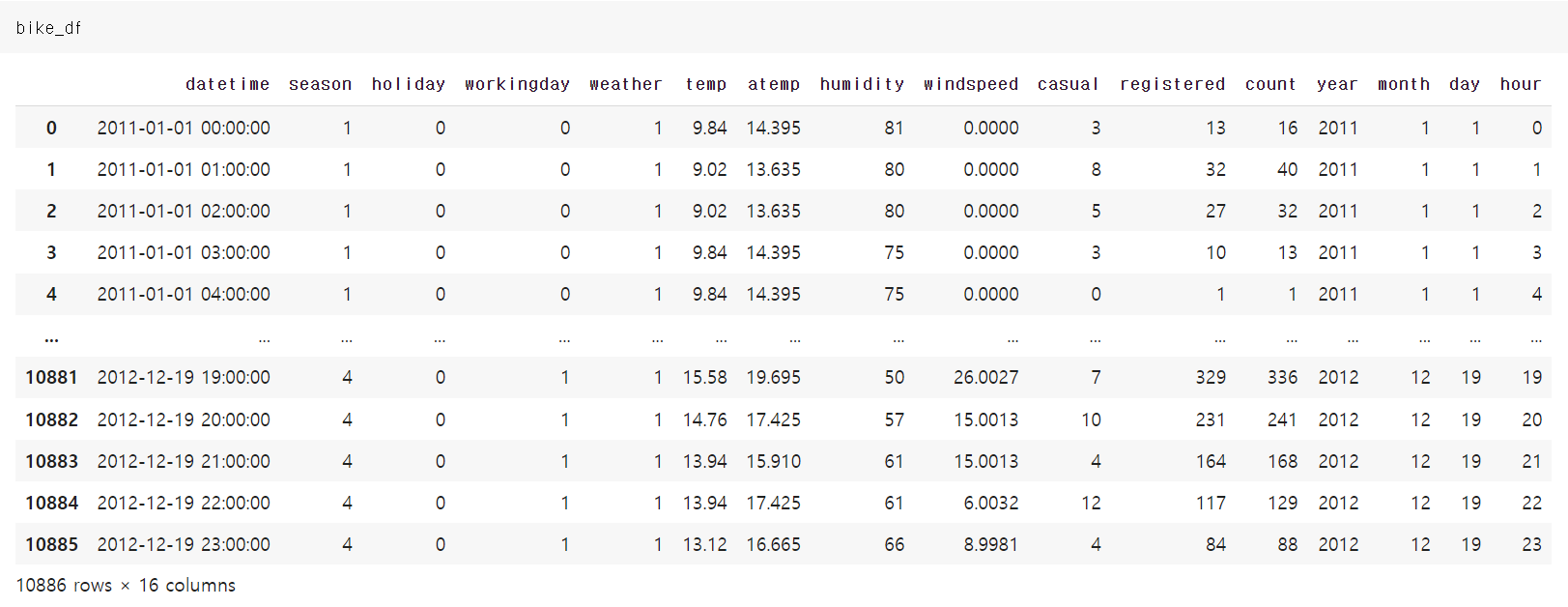
count 뒤로 연,월,일,시가 추가됐음을 확인
============================
4-6. 자전거 수요 예측하기 - 시각화
서브플롯 = matplotlib 안에 있는 기능
plt.subplot(행의 수, 열의 수)
figure, (ax1, ax2, ax3, ax4) = plt.subplots(nrows=1, ncols=4)
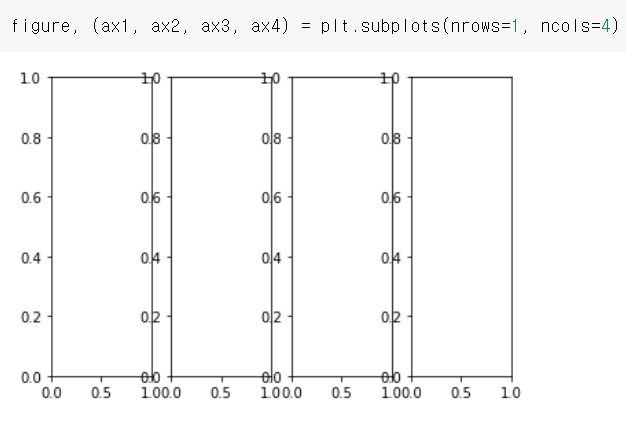
4개의 공간이 형성됨. 각각의 공간에 차트가 한개씩 들어감.
저 4개로 이뤄진 서브플롯 안에 이것저것 넣어주면 된다.
seaborn으로 서브플롯과 안의 내용물 채우기
# 연,월,일,시에 따른 대여량 확인
# 서브플롯 뼈대 생성
figure, (ax1, ax2, ax3, ax4) = plt.subplots(nrows=1, ncols=4)
# 형태 세부 조정
figure.set_size_inches(14, 4)
# seaborn으로 바차트 생성
sns.barplot(data=bike_df, x='year', y='count', ax=ax1)
sns.barplot(data=bike_df, x='month', y='count', ax=ax2)
sns.barplot(data=bike_df, x='day', y='count', ax=ax3)
sns.barplot(data=bike_df, x='hour', y='count', ax=ax4)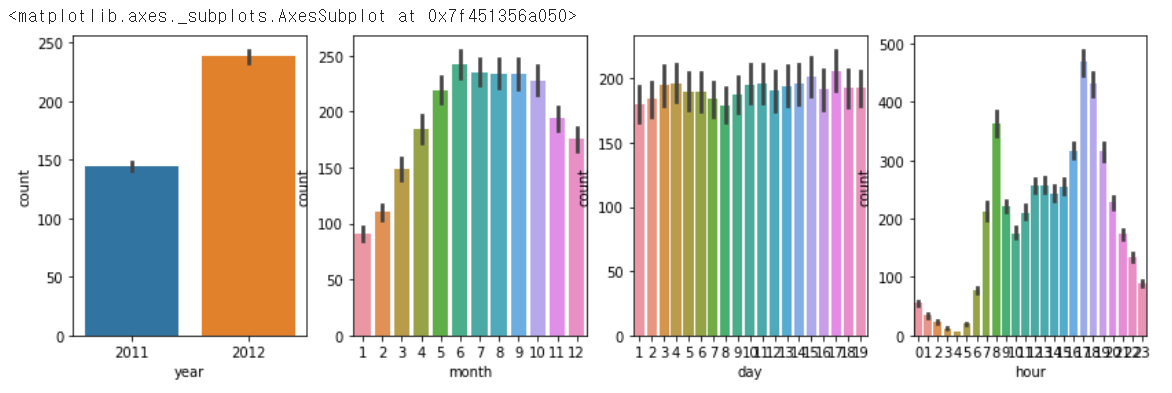
seaborn 사용코드
# 연,월,일,시에 따른 대여량 확인
# 서브플롯 뼈대 생성
figure, (ax1, ax2, ax3, ax4) = plt.subplots(nrows=1, ncols=4)
# 형태 세부 조정
figure.set_size_inches(14, 4)seaborn으로 바차트 생성
예제코드: sns.barplot(data=bike_df, x='year', y='count', ax=ax1)
sns.barplot -> 바 차트를 생성
(data = bike_df -> 로우데이터의 변수를 입력
x= 'year' -> year컬럼을 x축으로
y= 'count' -> count컬럼을 y축으로
ax=ax1) 위에서 만든 서브플롯 중 1번 서브플롯에 차트 생성시키기
박스플롯 생성해서 차트 그리기
대여량 / 계절별 대여량 / 시간별 대여량 / 주중,주말별 대여량 시각화
figure, ((ax1, ax2), (ax3, ax4)) = plt.subplots(nrows=2, ncols=2) figure.set_size_inches(12, 10)
기본코드
# 대여량 / 계절별 대여량 / 시간별 대여량 / 주중,주말별 대여량 시각화
figure, ((ax1, ax2), (ax3, ax4)) = plt.subplots(nrows=2, ncols=2)
figure.set_size_inches(12, 10)
대여량 / 계절별 대여량 / 시간별 대여량 / 주중,주말별 대여량 시각화
figure, ((ax1, ax2), (ax3, ax4)) = plt.subplots(nrows=2, ncols=2)
figure.set_size_inches(12, 10)
sns.boxplot(data=bike_df, y='count', ax=ax1)
sns.boxplot(data=bike_df, x='season', y='count', ax=ax2)
sns.boxplot(data=bike_df, x='hour', y='count', ax=ax3)
sns.boxplot(data=bike_df, x='workingday',y='count', ax=ax4)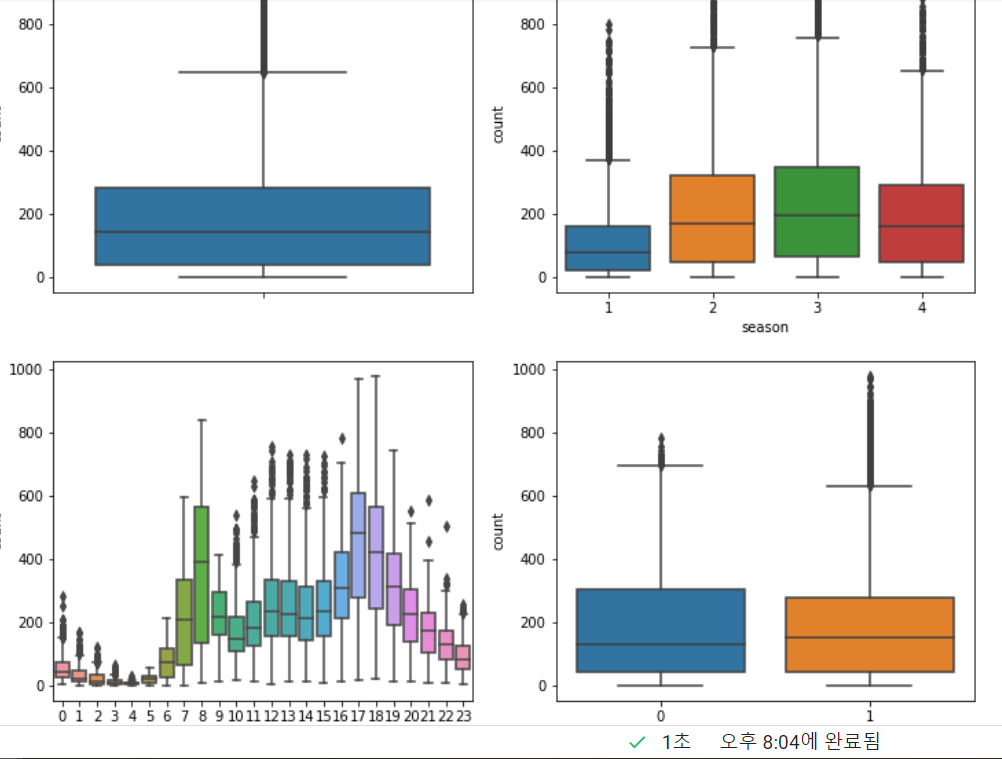
날짜의 요일을 탐색해서 분류해보기
.dt.dayofweek
bike_df['dayofweek'] = bike_df["datetime"].dt.dayofweek
0부터 월요일, 6이 일요일
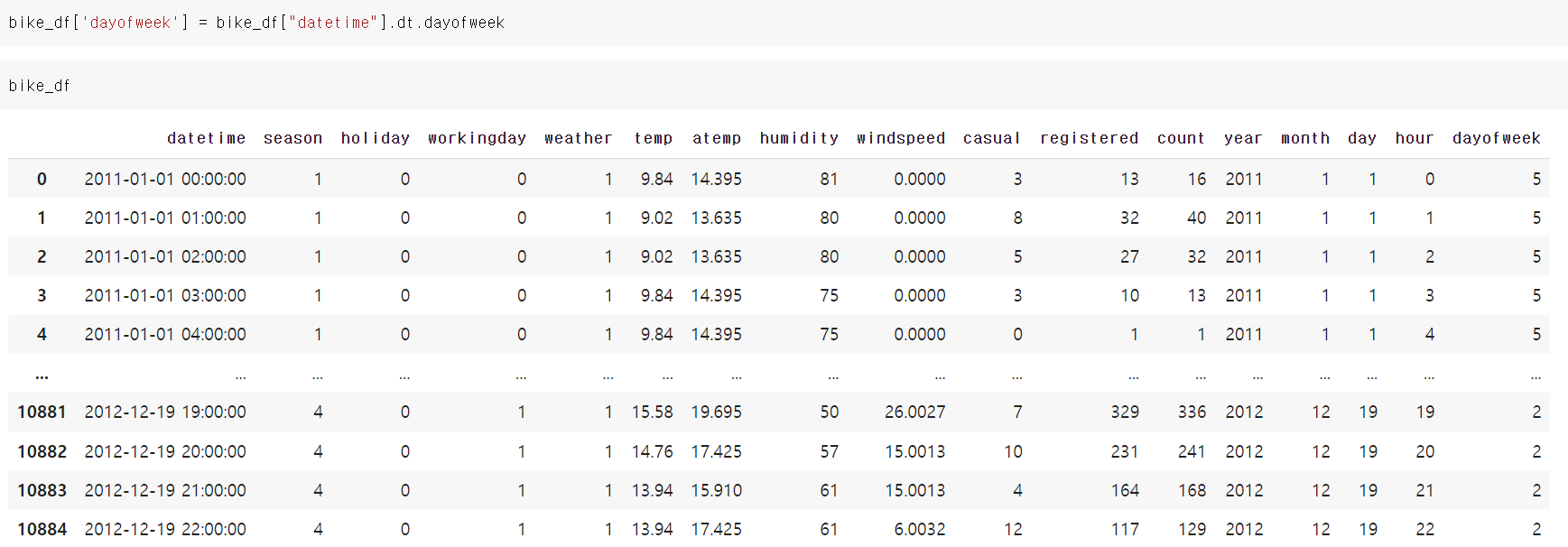
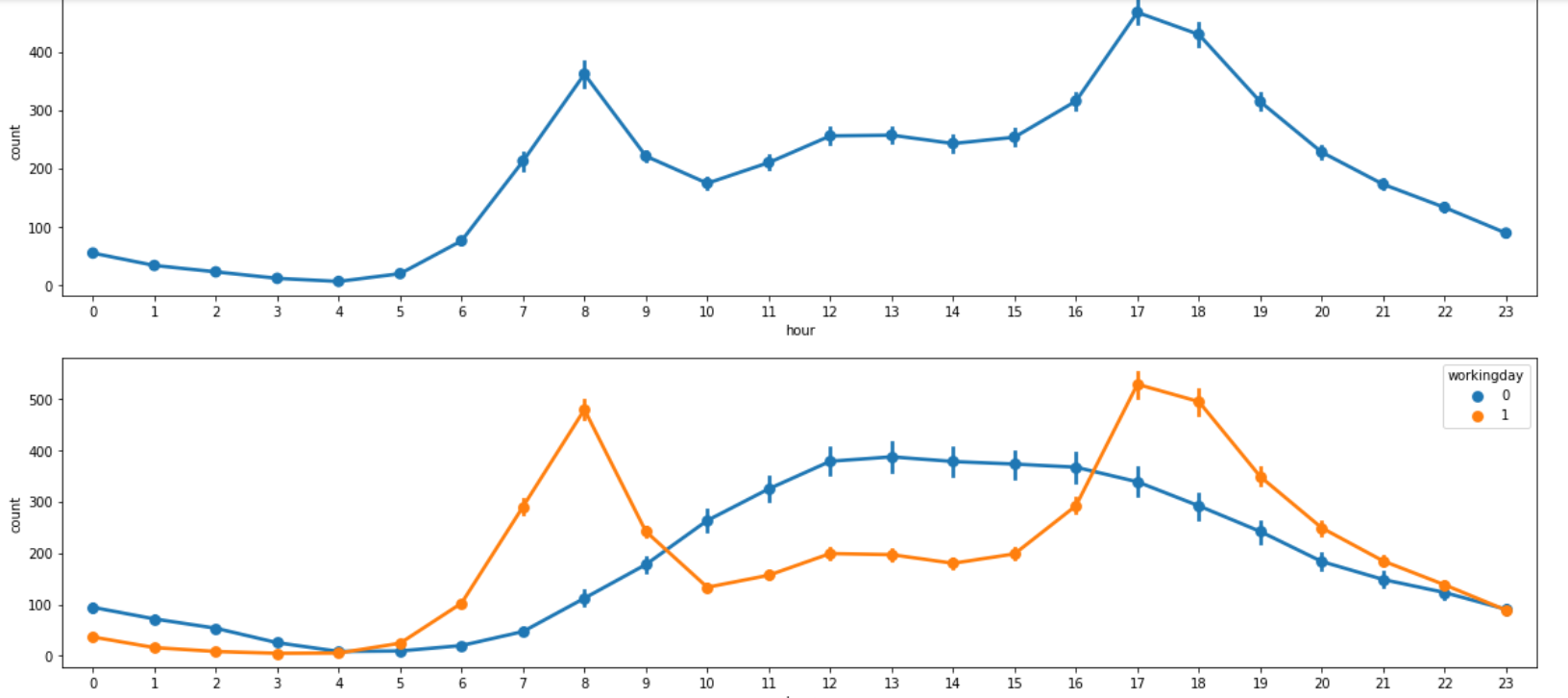
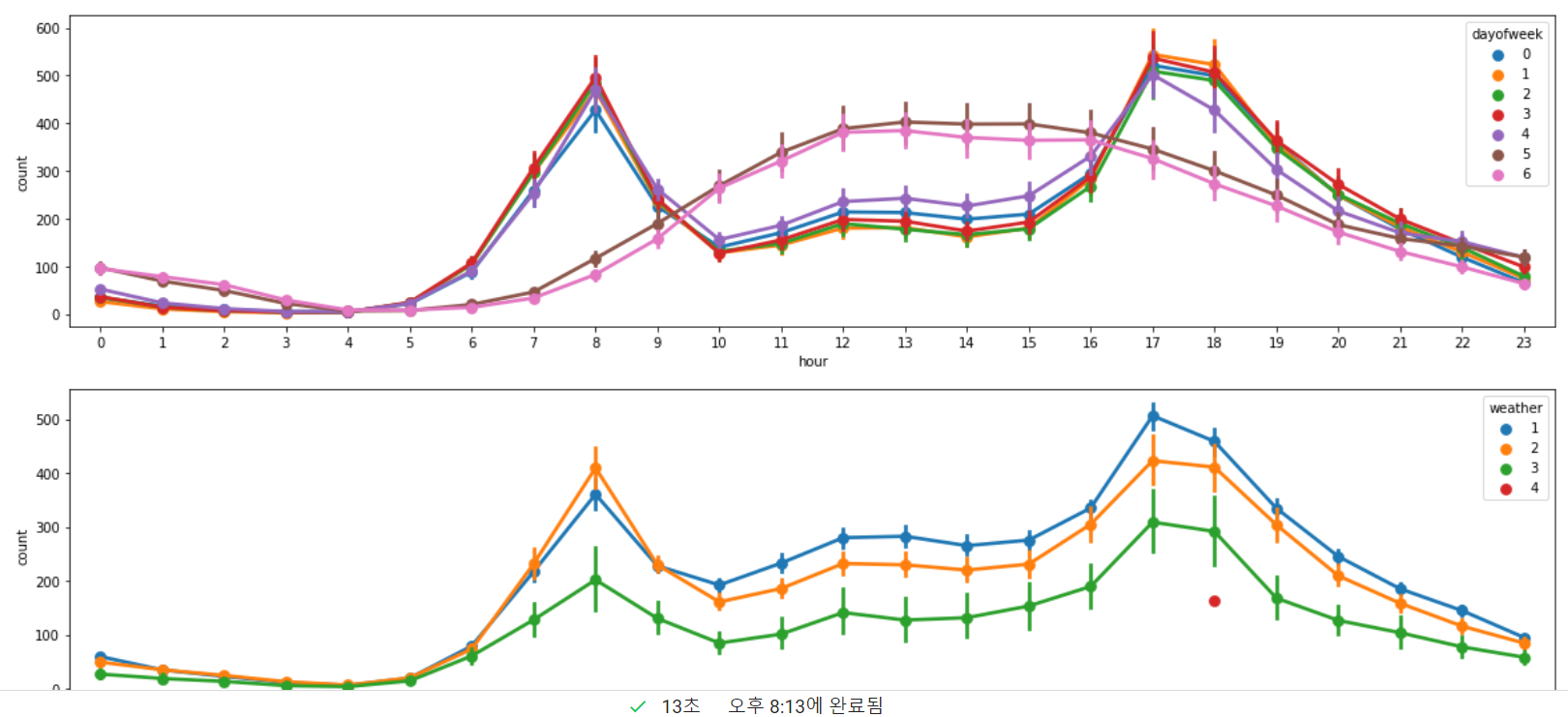
시간대별 대여량 시각화해보기(포인트플롯)
포인트플롯 = 데이터가 점 형태로 출력되는 선 그래프
hue
seaborn 패키지에서 사용 가능
hue="컬럼"
그룹화해서 시각화하는 것. 아래 예시 사진 참고
============================
4-7. 자전거 수요 예측하기 - 상관분석 & 정규화
특별한 내용은 없었던 듯...정규분포표를 만드는 정도
============================
4-8. 자전거 수요 예측 프로젝트 (1)
정확도를 계산하는 수단을 공부한다.
회귀 = 실제값과 예측값의 오차를 토대로 평가한다.
RMSLE, RMSE 함수
오차를 계산하기 위한 수식
RMSLE, RMSE, RMSLE와 RMSE 모두 사용하는 방식
# RMSLE 함수
def rmsle(y, pred):
# y : 전체 데이터의 실제값의 리스트 ex) [1, 2, 3, 4]
# pred : 전체 데이터의 예측값의 리스트 ex) [0.97, 1.85, 2.99, 3.87]
# np.log1p : 입력값에 +1을 한 후 log를 씌운다.
log_y = np.log1p(y)
log_pred = np.log1p(pred)
# 실제값과 예측값의의 차이의 제곱
squared_error = (log_y - log_pred) ** 2
# 모든 데이터에 대해 평균을 구한 후(np.mean())
# 루트를 씌워준다(np.sqrt())
rmsle = np.sqrt(np.mean(squared_error))
return rmsle# RMSE 함수
from sklearn.metrics import mean_squared_error
def rmse(y, pred):
# 평균 제곱 오차, MSE에 루트를 씌운다.
return np.sqrt(mean_squared_error(y, pred))# RMSLE, RMSE 함수를 동시에 쓰는 함수
# RMSLE, RMSE 계산
def calculate_model_score(y, pred):
rmsle_value = rmsle(y, pred)
rmse_value = rmse(y, pred)
print(f'RMSLE: {rmsle_value:.3f}, RMSE: {rmse_value:.3f}')============================
4-9. 자전거 수요 예측 프로젝트 (2)
기본 구성 코드
# 패키지 임포트
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
# 데이터 불러오기
bike_df = pd.read_csv('https://raw.githubusercontent.com/jesford/bike-sharing/master/train.csv')
print(bike_df.shape)
bike_df.head(3)
# 결측값 확인
bike_df.isnull().sum()
# 각 열의 타입 확인
bike_df.info()
# object 타입의 데이터를 날짜형으로 변환
# 문자열을 datetime 타입으로 변경.
bike_df['datetime'] = bike_df.datetime.apply(pd.to_datetime)
bike_df['datetime']
# 시간단위별로 열 구성
bike_df["year"] = bike_df["datetime"].dt.year # 연만 추출
bike_df["month"] = bike_df["datetime"].dt.month # 월만 추출
bike_df["day"] = bike_df["datetime"].dt.day # 일만 추출
bike_df["hour"] = bike_df["datetime"].dt.hour # 시간만 추출
bike_df.shape
# 필요없는 열 삭제
drop_columns = ['datetime', 'casual', 'registered']
train.drop(drop_columns, axis=1, inplace=True============================
============================
============================
============================
============================
============================
