작년 이맘때 쯤 GraphQL, Prisma, Express를 사용해서 웹 백엔드 개발을 진행했습니다. 그런데 왜 이제와서 다시 이 개념을 정리하려 하냐, 하시면 현재 회사에서 nest js와 TypeORM, RESTful api를 이용해 개발을 하고있기 때문에 그 차이와 장단점을 명확하게 짚고 넘어가고 싶어 글을 써보려고 합니다.
# GrapQL
GraphQL은 메타(전 facebook)에서 만든 API(Application Programming Interface)를 위한 쿼리 언어로 클라이언트로부터 쿼리를 전달받아 요청받은 데이터만을 반환해줍니다.
메타에서는 GraphQL을 개발 한 이유를 다음과 같이 설명했습니다.
- RESTful API로는 다양한 기종에서 필요한 정보들을 일일히 구현하는 것이 힘들었습니다. 예를 들어 iOS와 Android에서 필요한 데이터가 조금씩 달랐고, 다른 부분마다 새로운 API를 개발하는 것이 힘들었습니다.
GraphQL의 등장으로 백엔드에서 처리해줘야 하는 많은 양의 코드를 프론트엔드와 나누어 작업할 수 있게 되었습니다.
# REST
REST는 REpresentational State Transfer의 약자로 로이 필딩(Roy Fielding)이 2000년도에 웹의 장점을 최대한 활용할 수 있는 아키텍처로써 발표한 개념입니다.
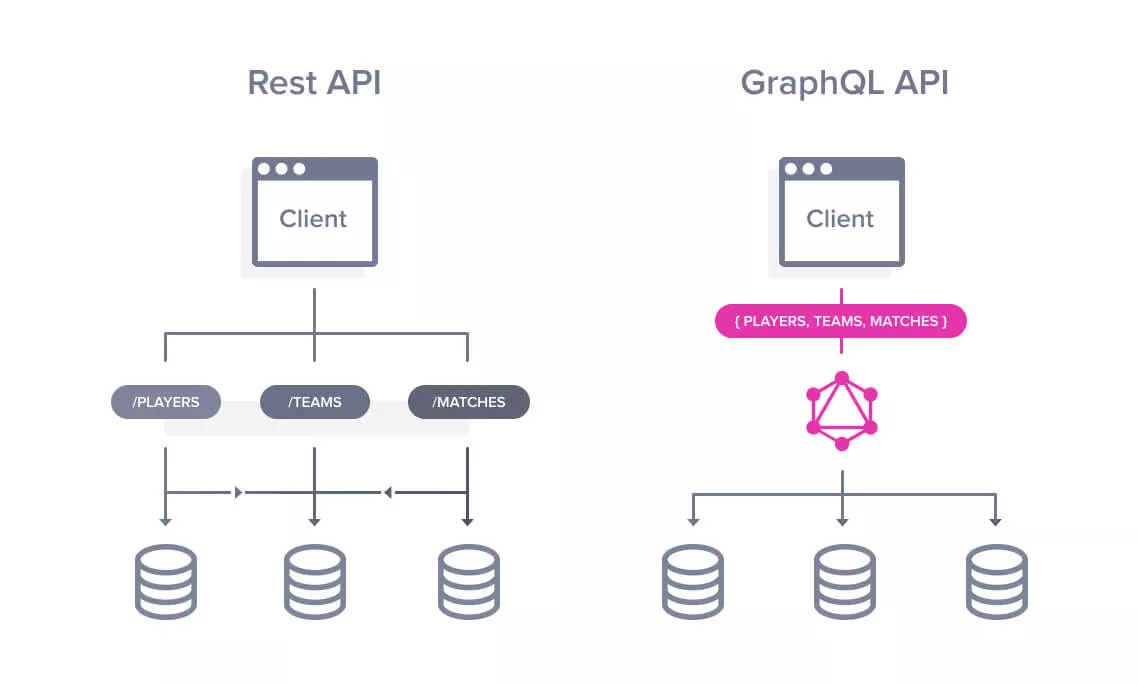
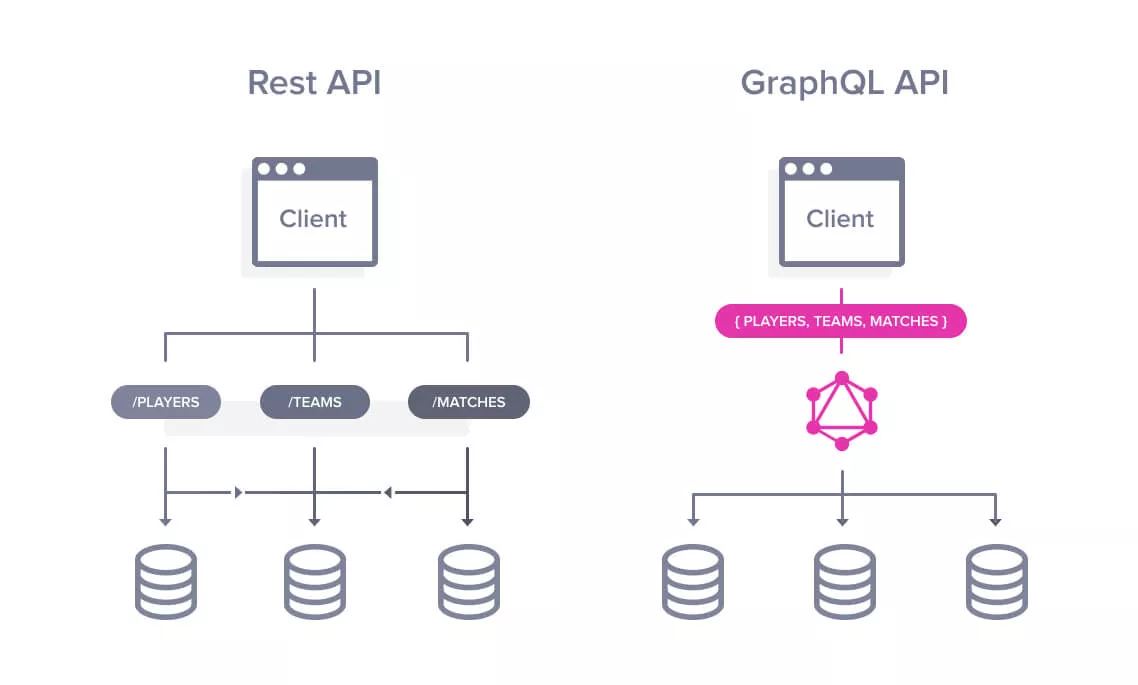
REST는 모든 자료(Resources)들을 하나의 EndPoint에 연결해두고, EndPoint는 해당 Resource와 관련된 내용만 정리하자는 방법론입니다.
예를 들어 한 User에 대한 정보를 생성, 조회, 편집, 삭제(CRUD)하는 API를 구성한다고 하면 EndPoint는 다음과 같을 것입니다.
- 생성 : (POST) /user
- 조회 : (GET) /user
- 편집 : (PUT) /user/{user_id}
- 삭제 : (DELETE) / user/{user_id}
사실 글만 보고 이해하기 너무 어려워요... 직접 써보면서 알아가는게 베스트...
REST의 내용을 자세히 다루기엔 내용이 너무 많아 다른 포스트에서 추가로 정리하겠습니다.
# GraphQL과 REST의 차이점
* Resource
대부분의 REST api는 결과를 JSON 형태로 반환합니다.
아래의 EndPoint로 접근하여 id가 1인 유저의 정보를 가져온다면 다음과 같은 결과를 받을 수 있을 것입니다.
- (GET)
/employee/1
{
"name": "jhon",
"age": 31,
"company": {
"name": "A_Company",
"ceo": "AAA"
}
}
// 보통 user와 company를 서로 다른 리소스로 분리합니다.
위와 같이 REST api는 리소스를 가져오는 방식과 반환하는 리소스의 타입 혹은 형태가 서로 연결되어있습니다. /employee라는 리소스를 요청하면 위와 같은 형태의 JSON 데이터가 반환됩니다.
위의 방식을 GraphQL로 옮긴다면 다음과 같습니다.
type Employee {
id: ID
name: String
age: Int
company: Company
}
type Company {
id: ID
name: String
ceo: String
emps: [Employee]
}REST와의 큰 차이점은 리소스의 유형과 리소스를 가져오는 방식이 완전히 분리되어있다는 것입니다.
type Query {
employee(id: ID!): Employee
company(id: ID!): Company
}GraphQL은 Employee와 Company의 형태를 정의하고, 이를 가져다 쓸 수 있는 Query를 작성하여 사용합니다. 각 Resource마다 endpoint를 정의하지 않고 하나의 엔드포인트만이 존재하며, 원하는 리소스와 해당 리소스에서 원하는 필드만을 요청할 수 있습니다.
graphql/query={employee(id:"1") { name, company { name }}} 로 요청하면 아래와 같은 결과를 받을 수 있습니다.
{
"name": "Jhon",
"company": {
"name": "A_Company"
}
}* URL Routes, GraphQL Scheme
REST 방식은 특정 작업에 대한 endpoint가 지정되어 있고 endpoint는 해당 리소스를 가리킵니다. 또한, HTTP Method에 따라 어떤 작업을 진행할지도 구분합니다.
하지만 GraphQL에서는 URL이 아닌 Scheme가 특정 리소스를 특정짓고, Mutation, Query를 통해 작업을 구분합니다.
GraphQL은 한 번의 요청에 여러 리소스에 접근할 수 있지만, REST 방식은 여러 리소스에 접근하기 위해선 요청을 여러 번 보내야합니다.
* Route Handler, Resolver
현재 사용하고 있는 node js를 기준으로 한 백엔드를 예시로 들겠습니다.
- REST API
// '/employee'
@Get(':id')
find(@Param('id')id: number, @Res()res: Response) {
// DB.
const result = {
"name": "Jhon",
"company": {
"ceo": "AAA"
}
}
res.send(result);
}
위 엔드포인트는 GET 요청에만 반응합니다. 따라서 클라이언트에서 /employee/1로 요청을 보내면 다음과 같은 JSON 데이터 응답을 받을 수 있습니다.
{
"name": "Jhon",
"company": {
"ceo": "AAA"
}
}- GraphQL
const resolver = {
Query: {
employee:(parent, args) => {
// DB.
cosnt result = { name: "James" };
return result;
},
company:(parent, args) => {
// DB
const result = {
name: "B_Company",
ceo: "BBB",
}
return result;
}
}
}REST와 다르게 특정 엔드포인트에 대한 함수를 제공하는 대신, 특정 필드에 대한 Query 타입의 함수를 제공합니다. 이러한 함수를 Resolver라고 부릅니다.
query {
employee(id: 1) {
name
company {
name
ceo
} } }위 쿼리를 이용해 아래 데이터를 반환받을 수 있습니다.
서버로 요청이 들어오면 서버는 해당 쿼리를 찾고, 쿼리에 존재하는 필드들의 resolver를 찾아 호출합니다. 그리고 resolver들의 반환 값을 모아 쿼리의 형태와 일치하는 JSON을 만들어 반환합니다.
따라서 아래와 같은 결과가 반환됩니다.
{
"employee": {
"name": "James",
"company": {
"name": "B_Company",
"ceo": "BBB"
}
}
}REST API는 Client가 각 리소스에 대한 endpoint를 호출하여 원하는 데이터를 얻어옵니다. 하지만 GraphQL은 원하는 리소스를 쿼리로 호출하면 백엔드에서 각 resolver를 호출하여 값을 반환받은 후, 클라이언트에서 요청한 쿼리의 형태에 맞게 값을 반환합니다.
[이미지 출처: https://devopedia.org/graphql]
# 정리
- REST API는 각 리소스에 대한 endpoint가 지정되어있고, GraphQL은 리소스와 리소스를 가져오는 방식이 완전히 분리되어있습니다.
- GraphQL은 클라이언트가 원하는 데이터만을 가져올 수 있어 편리하고, 여러 리소스에 대해서 하나의 쿼리로 호출할 수 있어 편리합니다.
- 하지만 고정된 요청과 응답을 처리해야 하는 경우, REST api보다 쿼리의 길이가 훨씬 길어질 수 있습니다.
따라서 GraphQL을 사용하는 경우는
- 서로 다른 모양의 다양한 요청에 대응해야할 때
- 작업이 주로 CRUD에 해당할 때
사용하기 적합하고,
REST를 사용하는 경우는
- 요청의 구조가 정해져있을 때
- File 전송 등, 전송이 단순 Text형태가 아닌 경우
에 적합한 것 같습니다.
회사에서 프로젝트를 진행하면서 REST api를 더 많이 사용해봐야겠지만,,, 제가 사용해본 결과 GraphQL이 백엔드 개발을 진행할 때는 백엔드가 할 일을 줄여줘서 편리했던 기억이 납니다.
하지만 그 쿼리를 모두 프론트에 정의해줘야해서 그만큼 프론트 단의 작업이 많아졌다는거...
아직 웹 개발을 많이 해본 것이 아니라 개념이 많이 부족하다고 느꼈고, 개발할 때 적합한 방법을 찾기 위해서는 사용해본 기능들에 대한 정리가 필요하다고 느꼈습니다.

좋은 글 감사합니다~☺️