
📢 본 포스트는 김영한님의 모든 개발자를 위한 HTTP 웹 기본 지식이라는 강의를 기반으로, 저의 생각이 잔뜩 첨가된 글임을 알립니다.
HTTP, 왜 중요할까?
요즘 거의 모든 것은 HTTP 프로토콜 기반에서 동작한다. 게다가 대부분의 문서들은 모두 독자가 HTTP를 이미 잘 알고 있다는 것을 가정하고 설명한다. HTTP를 잘 모른다면 이런 문서를 잘 읽어낼리가 만무하다. 또 현업에서도 HTTP와 관련된 고민이 여전히 이뤄지고 있다. API URL 설계는 어떻게 할 지, HTTP method는 어떤 것을 사용해야 할 지, HTTP 상태코드는 어떤 것을 사용하는 것이 좋을 지 갑론을박이 이뤄지는 주제들이다. 이런 고민거리들의 자신만의 확고한 기준을 세우려면 HTTP를 잘 알아야 한다. 결론은 우리가 평생 HTTP 기반 위에서 사고해야 한다는 것이다. 그러니 언젠가 한번은 HTTP를 정리해야 하고 필자가 지금 본 포스트를 작성하고 있는 이유이기도 하다.
이 글에서 다루는 것
- 인터넷 네트워크 기초 - IP, TCP
- URI와 브라우저 요청 흐름
이 글에서 다루지 않는 것
- 라우팅
- TCP Error control, Flow control, Congestion Control
- 그 외 네트워크 개념
인터넷 네트워크
클라이언트와 서버가 서로 통신을 하기 위해 인터넷을 경유한다. A에서 보낸 데이터가 B에 도착했을 때 우리는 그 데이터가 정말 A로부터 온 것인지 확신할 수 있을까? 이 파트에서는 HTTP를 설명하기 위해서 기본적으로 알아야 될 지식들에 대해서 소개한다.
네트워크 모델

먼저 네트워크는 계층 구조로 이뤄져 있다는 것을 알아야 한다. 네트워크를 계층 구조로 만든 것은 회사가 부서를 나누는 것과 일맥상통한다. 부서를 나누면 각 부서가 전문성이 생기고 하나의 부서에서 도맡아 처리하는 작업이 생긴다. 다른 부서에서는 타 부서가 어떻게 일을 처리하는지 알 필요없이 그저 자신의 부서의 일만 잘 처리하면 된다.
이와 같이 네트워크 모델도 각 계층에서는 위에서 내려온 데이터에 Header를 씌우는 작업을 거쳐 목적지에 데이터를 전송하게 된다. 목적지에서는 데이터를 전달받아 밑에서부터 위로 Header를 벗겨내며 넘겨준다. 또 각 계층에서는 각각의 프로토콜을 사용한다. 우리들은 Internet Layer, Transport Layer, Application Layer 의 프로토콜에 대해 알아볼 것이다.
네트워크 모델에는 OSI 7계층 모델, TCP/IP 모델이 있다. TCP/IP가 더 많이 사용되어 더 최근에 나온 것으로 오해하기 쉽지만 사실 TCP/IP 는 OSI 7계층이 나오기 전부터 사용하던 모델이다. OSI 7계층 구조가 더 많은 계층을 가지고 있기 때문에 TCP/IP 모델보다 더 우아한(?) 모델로 알려져 있다.
프로토콜
컴퓨터 네트워크 학문에서 사용되는 용어이다. 데이터를 교환하거나 전송하기 위한 방법 혹은 약속이다.
IP
IP는 이름에서 추측할 수 있듯 Internet Layer(Network Layer) 에서 사용되는 프로토콜이다. IP 주소로 데이터를 전달하는 프로토콜이고 패킷이라는 통신 단위의 데이터를 전달한다. 패킷은 출발지 주소(Source IP Address), 목적지 주소(Destination IP Address) 등이 포함된 헤더를 씌운 데이터를 말한다.
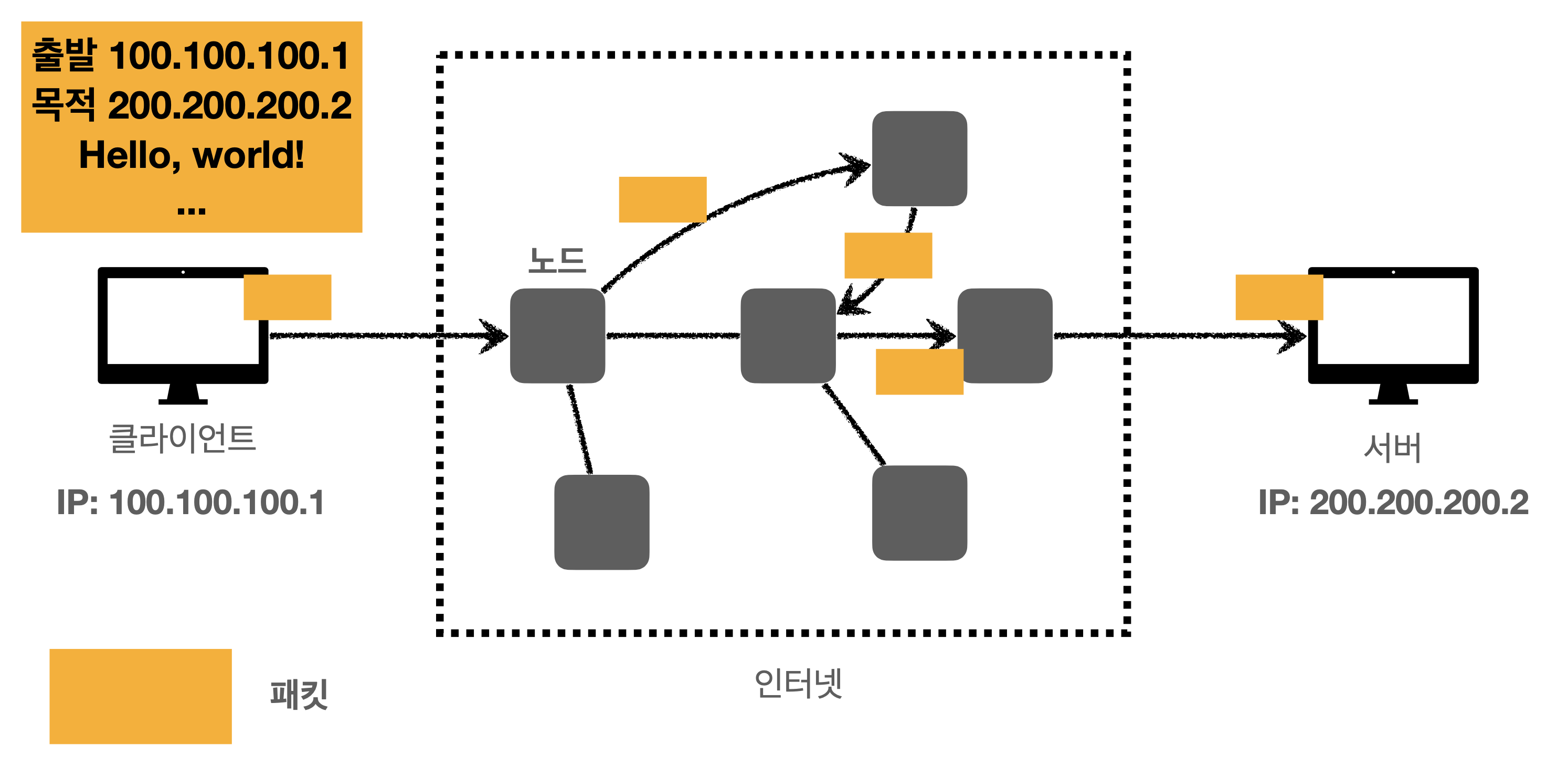
데이터가 전송되는 과정을 Natwork Layer 관점에서 아주 단순하게 설명하면 100.100.100.1 주소를 가진 호스트가 200.200.200.2를 가진 주소로 인터넷을 통해 패킷을 전달할 때 각 노드는 서브넷 마스크, 포트 넘버를 이용하여 목적지 주소 200.200.200.2 로 가야할 방향을 제시한다. 몇 번의 라우팅 과정을 거치면 목적지에 패킷이 도착한다.
IP 프로토콜만으로는 몇가지 문제가 있다.
- 비연결성 : 패킷을 받을 대상이 없거나 서비스 불능 상태여도 패킷은 전송된다.
- 비신뢰성 : 패킷의 순서를 보장하지 못하고 패킷이 소실되어도 알 수 없다.
- 프로세스 구분 : 같은 IP를 사용하는 서버에서 통신하는 프로세스가 둘 이상이면 이를 구분할 수 없다.
TCP
TCP 데이터 단위는 세그먼트이다. 세그먼트는 출발지 포트(Source Port Address), 목적지 포트(Destination Port Address), 전송 제어, 순서, 검증 정보 등이 포함된 헤더를 씌운 데이터이다. TCP는 IP의 한계를 보완해주는 프로토콜이기 때문에 다음과 같은 특징을 가진다.
TCP 3 way handshake
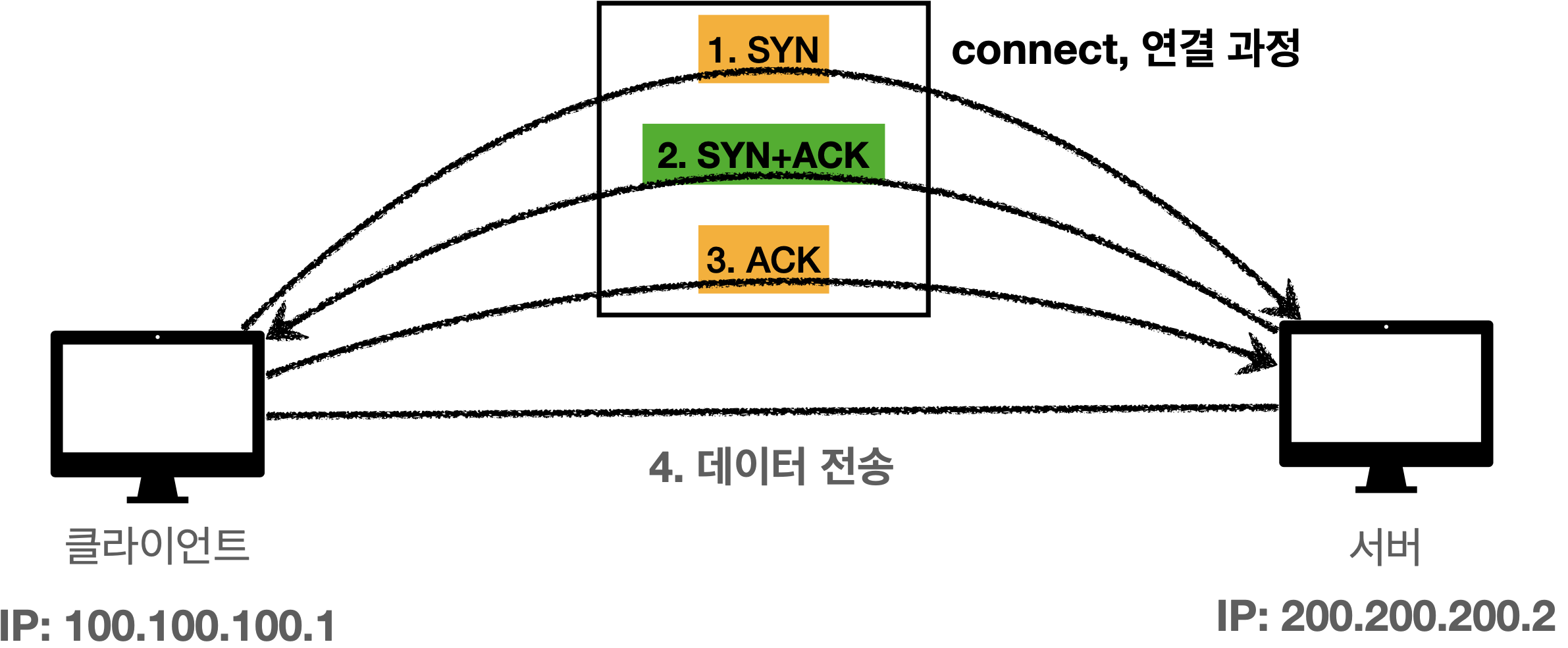
실제 데이터를 전달하기 전에 수신 측과 연결을 시도한다. 순서는 다음과 같다.
- 클라이언트 측에서 '나 연결해줘' 라는 의미의
SYN메시지를 보낸다. SYN을 받은 서버 측이 'ㅇㅋ, 나도 연결해줘' 라는 의미의SYN+ACK메시지를 클라이언트로 전달한다.- 이를 받은 클라이언트가 'ㅇㅋ' 라는 의미의
ACK을 보내며 연결이 성사된다.
핵심은 클라이언트와 서버 둘 다 SYN 과 ACK 을 한번씩 보내어 서로에 대한 신뢰성을 보장한다는 점이다.
데이터 전달 보증
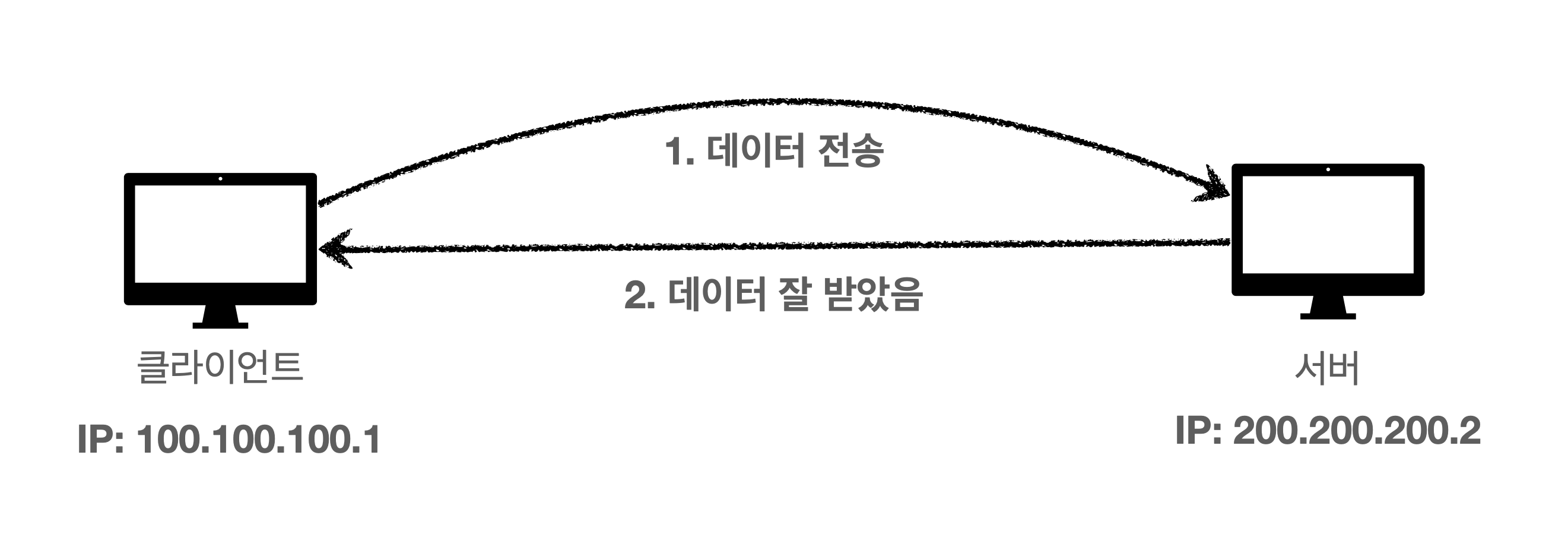
클라이언트에서 서버로 데이터를 전달했을 때 중간에 데이터가 소실되었다면 서버로부터 ACK 가 오지 않기 때문에 클라이언트는 '아, 통신 중에 데이터의 어느 부분이 소실되었구나. 그 부분을 다시 보내야겠네' 라며 재전송을 통해 데이터가 전달되는 것을 보증을 할 수 있다.
순서 보장
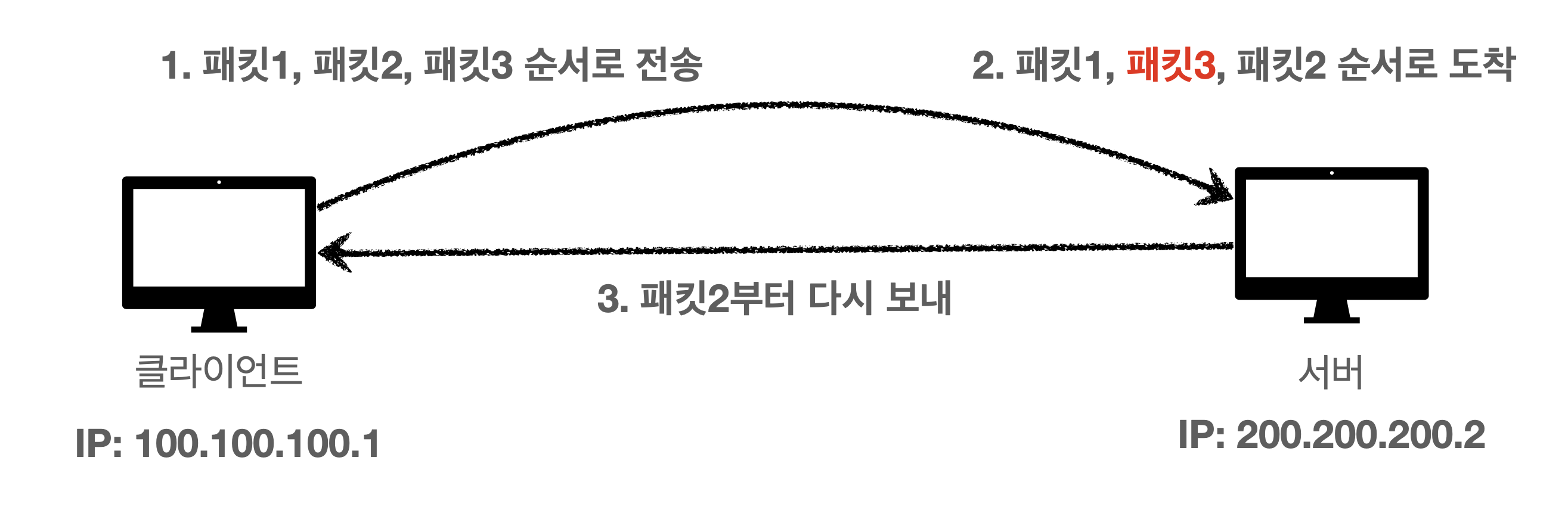
클라이언트에서 서버로 패킷을 쪼개 보낼 때 순서도 보장한다. 이것이 가능한 것은 세그먼트 Header에 있는 Sequence Number 등과 같은 정보들 덕분이다.
UDP
Trasport Layer 의 process-to-process 특성을 가지기 위해 Port, checksum 정도만 추가되었을 뿐 하얀 도화지와 같은 프로토콜이다.
Port
Transport 계층의 핵심은 process-to-process 통신을 보장하는 것이다. 같은 IP에서도 서로 다른 프로세스가 인터넷과 연결된 수많은 컴퓨터와 통신을 해야하는데 IP만으로는 이것이 불가능하다. 그래서 Transport 계층에서 Port 주소가 추가되고 이를 통해 어떤 프로세스로 향하는 데이터인지 알 수 있게 한 것이다. Port는 0 ~ 65535 까지 할당할 수 있지만 0 ~ 1023 까지는 일명
well-known-port라고 불리는 Port number 로서 사용하지 않는 것이 좋다.
URL와 웹 브라우저 요청 흐름
네트워크의 기본적인 지식들을 굉장히 축소하여 알아보았다. HTTP를 알아보기 전에 마지막으로 URI, URL, 웹 브라우저의 요청이 어떤 과정을 통해 이뤄지는지 살펴보자.
URI
URI는 Uniform Resource Identifier 의 약자로 리소스를 식별하기 위한 정보를 뜻하며 URL, URN을 포함하는 개념이다. 여기서 URL은 리소스의 위치, URN은 리소스의 이름이다. URN 이름만으로 실제 리소스를 찾을 수 있는 방법이 보편화되어 있지 않기 때문에 URI와 URL을 같은 의미로써 말하기도 한다.
URL
http://www.example.com:80/path/to/myfile.html?key1=value1&key2=value2#SomewhereInTheDocumentURL은 웹에 게시된 어떤 자원을 찾기 위해서 브라우저에 의해 사용되는 메커니즘이다. 이론적으로 각각의 유일한 URL은 유일한 자원을 가리킨다. 그런 자원은 HTML, CSS, 이미지 등이 될 수 있다.
Scheme
URL의 첫 번째 부분인 Scheme 은 브라우저가 리소스를 요청하는 데 사용해야 하는 프로토콜을 나타낸다. Application Layer의 프로토콜 -- http, https, ftp -- 이 사용된다. Scheme 이후에 뒤따라 오는 :// 는 뒤따라 오는 string과 Scheme를 구분 짓기 위해서 사용한다.
Authority
도메인 이름과 포트 번호로 구성된다. 도메인 이름은 요청 중인 웹 서버를 나타내는데 당연히 IP 주소로도 사용될 수 있다. Scheme에서 http, https를 사용하게 되면 이들은 well-known-port 이기 때문에 -- http(80), https(443) -- Port 번호는 생략할 수 있다.
Path
웹 서버의 리소스에 대한 경로이다. 웹 초기에는 이와 같은 경로가 웹 서버의 실제 파일 위치를 나타냈지만 요즘에는 논리적인 계층 단위로 사용된다.
Parameters
query parameter, query string 등으로 불리기도 한다. key=value 형태를 가지고 있고 ? 로 시작 하며 & 로 파라미터를 추가할 수 있다. 리소스를 반환하기 전에 이러한 파라미터를 사용하여 추가 작업을 수행할 수 있다.
Anchor
프래그먼트라고 불리기도 한다. 앵커는 리소스 내부의 일종의 책갈피를 나타내고 브라우저에 해당 책갈피 지점에 있는 콘텐츠를 표시하도록 지시한다.
웹 브라우저 요청 흐름
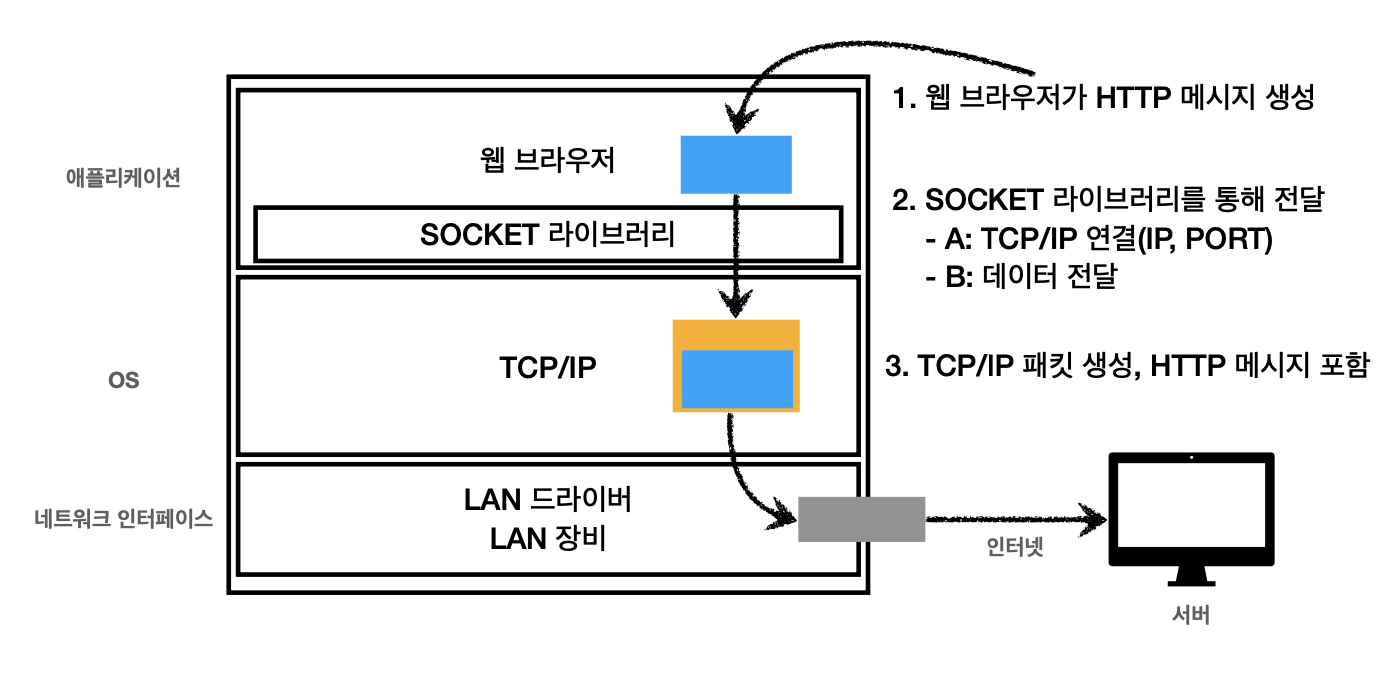
사용자가 웹 브라우저를 사용하는 상황을 가정하여 순서대로 발생하는 일들을 목록화 해보자.
- 사용자가 브라우저 주소창에 URL을 입력한다.
- 도메인 이름을 통해 DNS 서버에서 매핑된 IP 주소를 알아낸다.
- 그럼 브라우저는 IP 주소와 포트 번호를 통해 HTTP 요청 메시지를 생성한다.
- HTTP 요청 메시지는 Socket 라이브러리를 통해 TCP/IP 계층으로 전달된다.
- TCP/IP 계층에서 세그먼트 헤더, 패킷 헤더를 붙인다.
- 3 way handshake를 통해 서버와 연결을 시도한다.
- 요청 메시지가 인터넷을 통해 서버로 전송된다.
- 서버에서 요청 메시지를 받아 같은 방식으로 응답 메시지를 클라이언트로 전달한다.
참조
