U Mamba
Flow matching이 좋은게, 변화율을 학습하는 개념 자체가 좋은 것도 있지만, 미분꼴이 알고있는 항 두 개 사이의 뺄셈으로 나타나서 빠르게 미분값을 얻어낼 수 있어서도 있을 듯.
목표논문:
U-Shape Mamba: State Space Model for faster diffusion
코드제공:
https://github.com/ErgastiAlex/U-Shape-Mamba
저널/컨퍼런스:
CVPR 2025 의 워크숍 중 하나인 Efficient Large Vision Models (eLVM) 워크숍에 채택(Accept)
유사논문?
U-shaped Vision Mamba for Single Image
Dehazing
비교대상의 코드:
https://github.com/CompVis/zigma
효율적 대안으로서 SSM 및 Mamba
- SSM은 시퀀스 길이에 대해 선형적 복잡도를 가지며, 트랜스포머에 비해 메모리 요구량을 크게 줄일 수 있음
- Mamba는 트랜스포머에 필적하는 성능을 훨씬 적은 자원으로 달성하였고 (연산 복잡도 O(N) vs O(N²)) 이미지 분류, 검출 등 다양한 비전 과제에서 효과를 입증
- 2024년 ECCV의 Zigma 연구는 이러한 Mamba를 확산 모델 백본에 도입하여, DiT나 U-ViT과 동일한 이미지 품질을 절반의 GFlops로 생성하는 모델을 제안
이전 연구의 한계
- Zigma에서는 2D 이미지를 1D 시퀀스로 취급하는 지그재그 스캔 기법까지 도입해 공간 연속성을 높였지만, 여전히 단일 해상도 상에서 동작하는 구조적 한계와 높은 품질 유지를 위한 비용이 남아 있었습니다.
Contribution
- Flow Matching을 통한 단계 축소
- Flow Matching 훈련 방법과 Mamba 기반 백본을 결합함으로써, 이전에는 불가능했던 적은 자원의 하드웨어에서도 동작 가능한 효율적 확산 모델을 구현하고자 했습니다.
Flow Matching
- 확산 과정의 단계 수를 줄이기 위한 새로운 접근으로 Flow Matching 기법도 제안
- 노이즈 분포에서 데이터 분포로의 경로를 직선 형태로 정의하여 복잡한 확산 과정을 수학적으로 단순화하고 결과적으로 필요한 확산 단계 수를 크게 단축시킵니다

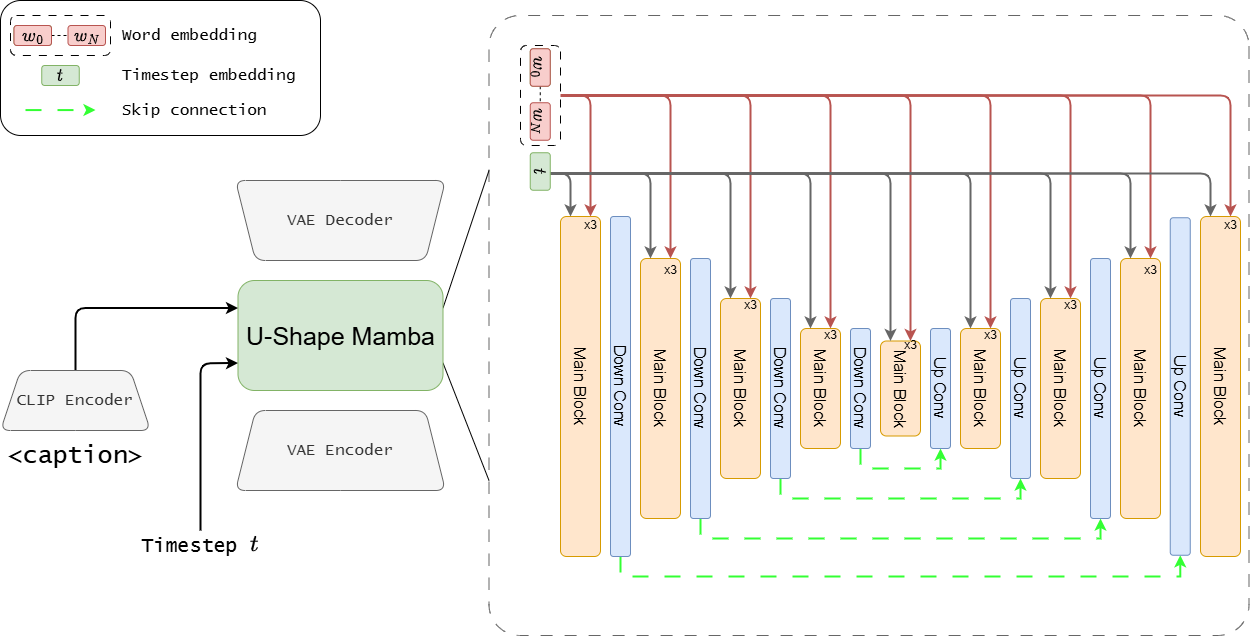
USM: U-자형 Mamba 아키텍처의 제안
- USM은 U-Net과 유사한 다단계 인코더-디코더 구조에 Mamba 기반 블록들을 결합한 새로운 확산 모델 아키텍처
전체 USM 모델은 인코더 12개 블록–병목 1개–디코더 12개 블록의 25개 Mamba 블록으로 구성
인코더 역할
- 입력 이미지를 우선 VAE 인코더를 통해 저해상도 잠재 표현(latent)으로 압축, 이를 일련의 Mamba 블록들로 이루어진 계층적 시퀀스 모델에 투입
- 인코더에서는 매 수 개 블록마다 다운샘플링 = 시퀀스 길이(공간 해상도)를 4배씩 축소하며 진행
디코더 역할
(반대로 / transposed convolutions)
활용
- 주요 블록 내에는 시간 단계 에 따른 Adaptive LayerNorm 조정과 함께
caption의 활용
- Mamba 셀 다음에 Cross-Attention 모듈을 배치하여, 텍스트 조건이 있을 경우 CLIP 텍스트 임베딩을 활용할 수 있게 설계
스킵 커넥션
- 인코더와 디코더의 대칭 위치 블록들은 모두 스킵 연결(skip connection)로 이어져 있어, 다운샘플링 과정에서의 중요한 정보 손실을 방지
이미지의 2D 공간 구조를 1D 시퀀스로 순서화(Scan / Rasterization)하는 전략
- 마지막으로, Zigma 연구에서 도입했던 2차원 지그재그 등 8가지 스캔 패턴을 USM에도 적용하였습니다. 각 Mamba 블록은 순차적으로 서로 다른 스캔 순서를 사용하고, 8번째 패턴 후 반복함으로써, 시퀀스 변환 시 공간적 인접 정보와 장거리 의존성을 고르게 처리합니다.
U-Net 구조의 의미
- 고수준 의미 정보와 저수준 세부 정보를 모두 효과적으로 포착
- (비교) Zigma는 DiT 스타일의 트랜스포머 기반 단일 해상도 시퀀스 모델로, 입력 이미지를 패치로 펼쳐 동일 해상도에서 모든 블록을 처리
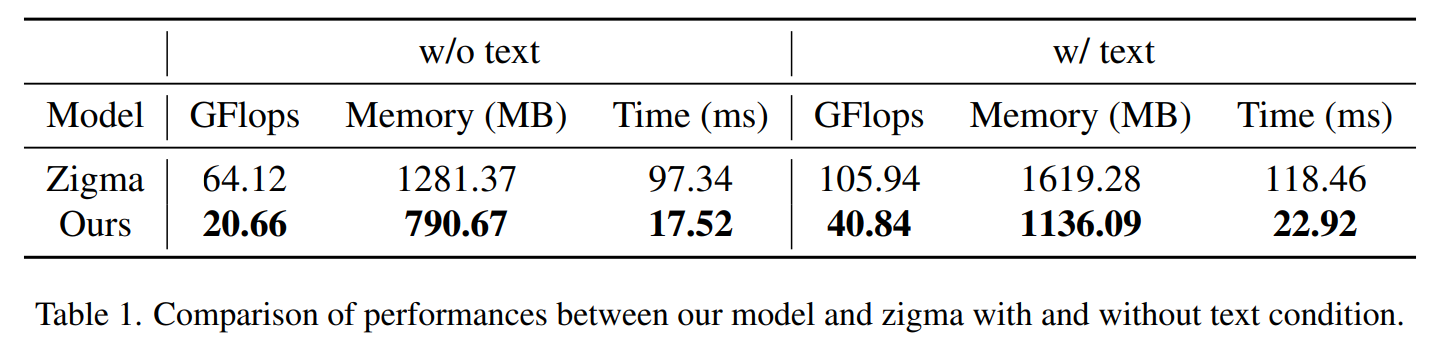
Zigma 와 비교 / 텍스트 abalation
- w/o text: 추론비용 1/3 수준, 메모리 39% 감소
- w/ text: 추론비용 40% 수준, 메모리 30% 감소
- 추론 속도 4-5배 (80% 단축)
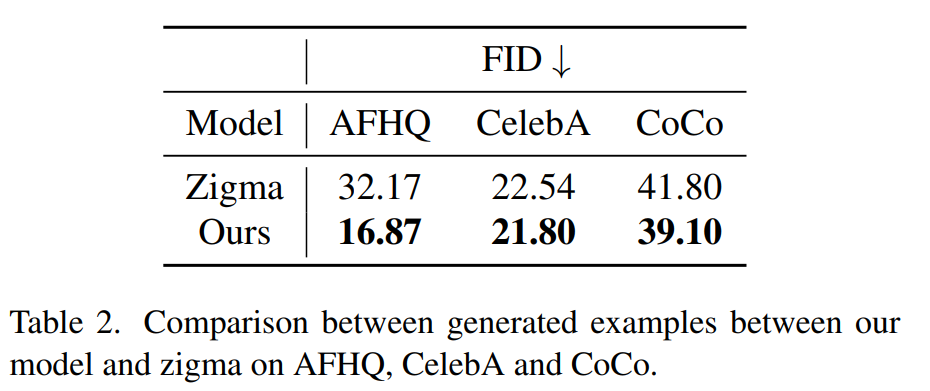
Zigma 와 비교
- 우수한 이미지 품질
스킵 커넥션 abalation
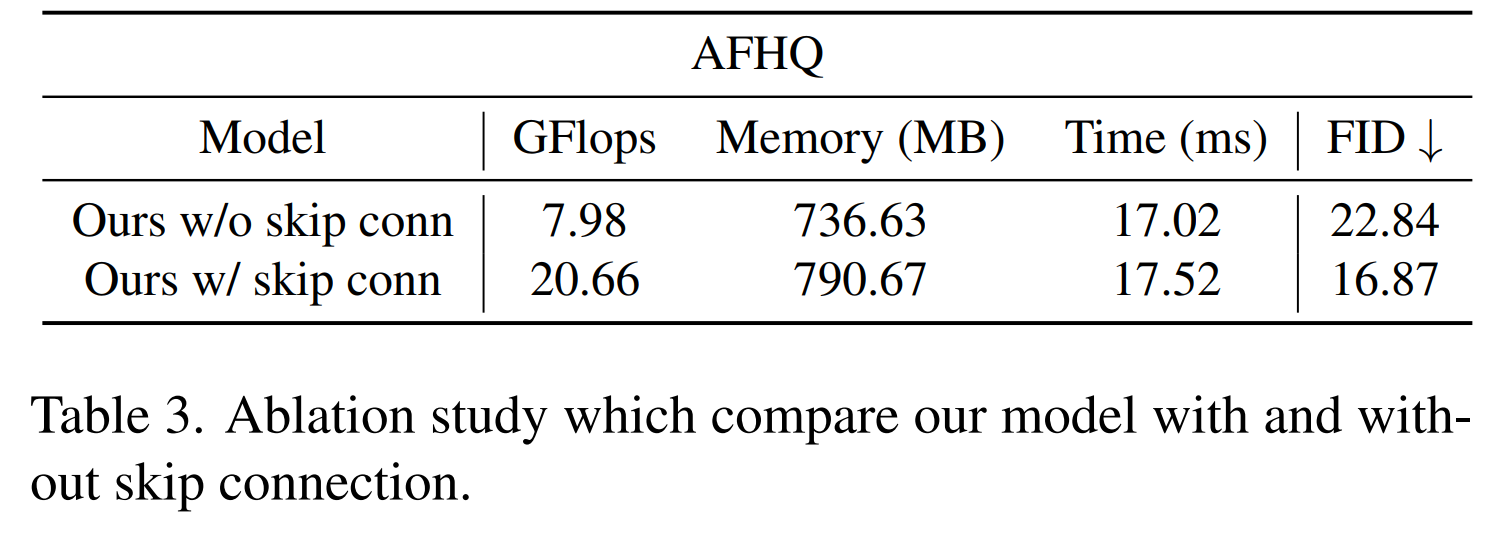
*FID(Frechet Inception Distance)
Flow Matching 기법
- 확산 모델의 정방향(noising) 과정을 선형 보간 형태로 정의하여, 노이즈 에서 데이터 까지 직선 경로를 학습하는 방식
*정방향: 이미지에서 노이즈로 가는 방향 - 즉 시간 에 따라 로 두 분포를 연결하고, 모델은 그 변화율 (이론적으로 에 해당)를 예측하도록 훈련
- 수학적으로 단순한 확산 경로를 제공하여 모델이 더 쉽게 학습하고, 결과적으로 필요한 샘플링 단계 수를 크게 감소
- USM은 이 방법으로 훈련되어 25회 확산 스텝만으로 고품질 이미지를 생성 (기존 확산 모델들이 수십~수백 스텝을 필요로 하던 것에 비해 월등히 효율적)


본 논문의 한계
-
본 논문에서는 USM을 256×256 해상도의 비교적 제한된 데이터셋(AFHQ, CelebAHQ 얼굴, COCO 등)에서 검증
-
아직 초고해상도 이미지 생성(예: 1024×1024 이상)이나 대규모 범용 데이터에 대한 실험 x
-
Zigma는 May. 24th, 2024: 🚀🚀🚀 New checkpoints for FacesHQ1024, landscape1024, Churches256 datasets
참고
CLIP의 핵심 아이디어 (Contrastive Language-Image Pretraining)
CLIP(OpenAI, 2021)은
이미지 + 텍스트(캡션)를 동시에 입력받아
같은 의미를 가진 것끼리는 embedding space에서 가까워지도록
다른 의미는 멀어지도록 학습
🖼️ 이미지 Encoder → 이미지 벡터
📄 텍스트(캡션) Encoder → 텍스트 벡터
두 벡터를 ‘같은 공간’에서 비교할 수 있게 만든다.
Vision Encoder : ResNet-50/101 계열 또는 Vision Transformer(ViT-B/32 등)
Text Encoder : Transformer 기반 (GPT-like)
참고
디퓨전 생긴거
참고
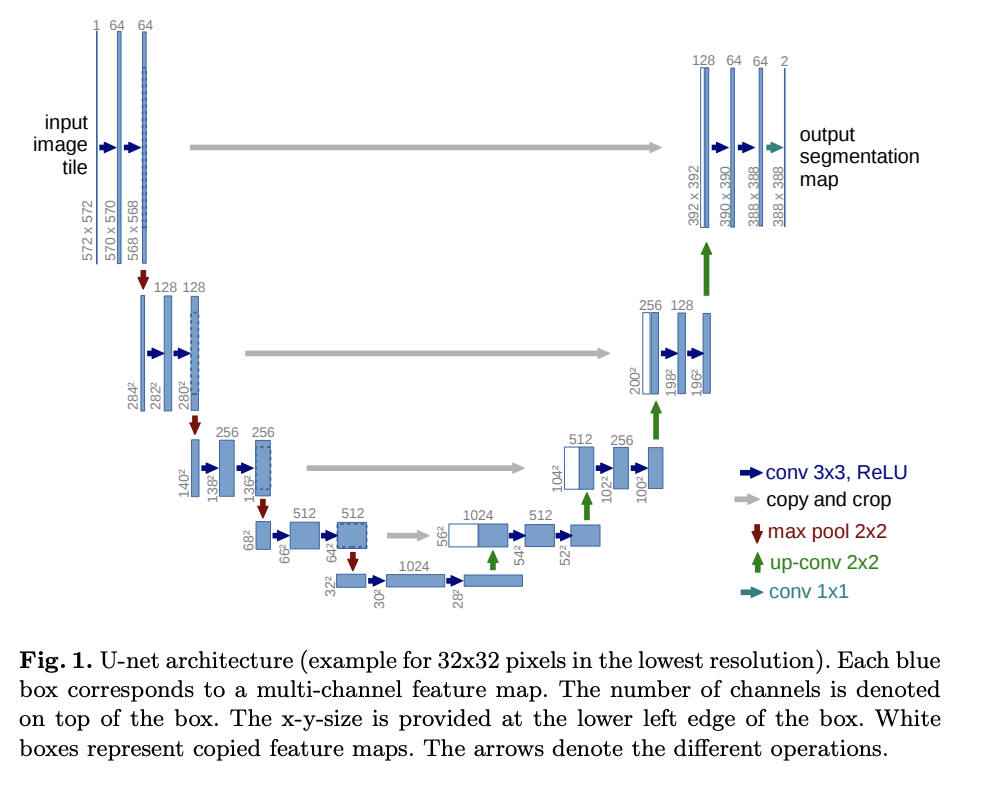
스테이블 디퓨전
핵심 아이디어:
이미지를 바로 디퓨전으로 처리하면 연산이 비쌈
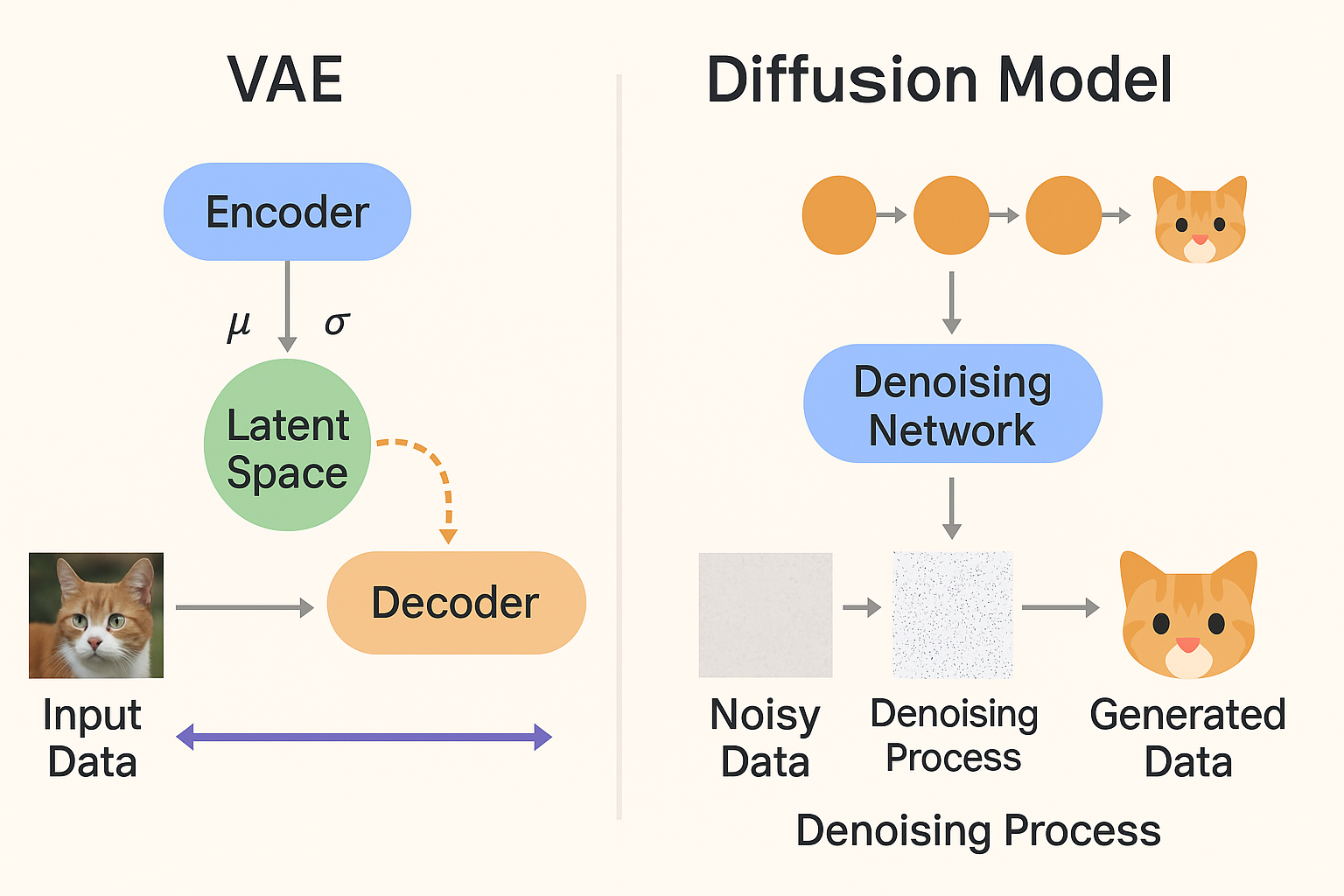
대신 VAE Encoder가 이미지를 latent 공간(z)으로 압축
Diffusion은 latent 공간에서 노이즈 제거
결과 latent를 VAE Decoder가 다시 이미지로 복원
-
VAE Encoder
이미지 → latent z (대략 1/4~1/8 spatial size) -
Diffusion U-Net
latent 공간에서 iterative denoising
cross-attention으로 text conditioning(CLIP text encoder) -
VAE Decoder
latent → 최종 이미지
고해상도, 계산량 축소
참고
귀여운 사진
알고리즘

1: 모델 파라미터 랜덤 초기화
2: 전체 iteration N 동안 반복
3: 데이터세트에서 샘플 x를 선택. x=이미지
4: 가우시안 노이즈 샘플링
5: 임의의 t 시점에서 학습. 샘플마다 다른 t를 가짐.
6: 시간 변수 에 대해 데이터 샘플 와 가우시안 잡음 사이를 선형 보간
7: v = x − ε: z(t)의 시간 변화량(t에 대해 미분한 값) = 네트워크가 학습해야 할 velocity
8: 네트워크는 = “현재 z(t)에서 목표 데이터 방향 속도” 를 예측
9:
10: : 네트워크가 올바른 속도(gradient of path)를 예측하도록 학습
11: 일반적인 gradient descent
12, 13: 학습 완료된 모델 반환




- USM에서는 역방향 과정(backward process), 즉 생성 모델은 위 경로를 따라 확률적 흐름을 역추적하는 것을 확률적 미분방정식(ODE)의 형태로 푼다.
- 신경망은 해당 경로의 속도 벡터장 를 학습
Continuous Normalizing Flows
뉴럴 넷가 변환 자체인 flow를 학습하는 것이 아니라, flow의 vector field를 학습하도록 정의
학습 과정 중에 적분을 수행해야 하기 때문에 ODE Solver를 통해서 여러번의 forward가 필요하기 때문
