
규모조정의 요소
규모조정,확장성
웹서비스에서는 고가의 하드웨어를 사용하는 스케일업보다 저가의 다수의 하드웨어를 나열하는 스케일아웃전략이 주류이다.비용과 유연성에서 장점이 있기 때문이다.하드웨어가 10배가 비싸다고 10배의 성능이 나지 않는다.따라서 동일성능을 내기 위해 저가의 하드웨어 나열이 더 가성비가 좋다.부하가 적을때는 서버수를 줄이고 클때는 늘리면 되기에 유연성이 높아 빠른 상황대처가 가능하다.
규모조정의 요소
스케일아웃은 하드웨어를 횡으로 전개하여 cpu부하의 확장성을 확보하기 쉽다.예를들어 애플리케이션서버가 HTTP요청을 받아 DB로 질의후 받은 데이터를 가공하여 HTML로 반환시 CPU부하만 소요된다.DB서버에서는 I/O부하가 걸린다.
웹 어플리케이션과 부하의 관계
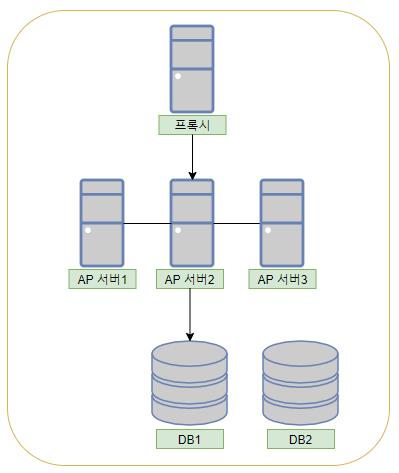
웹어플리케이션 요청에 의해 프록시=>AP서버를 거쳐 DB에서 I/O가 발생하고 I/O후 데이터를 처리하여 클라이언트로 응답한다.AP서버는 데이터를 분산하여 갖고있지 않아 동일한 처리를 다른 AP서버에서 처리하면 되므로 확장이 간단하다.이 분산은 로드밸런서가 처리해준다.
하지만 I/O부하는 분산시 어떻게 동기화할것인지에 대한 문제가 발생한다.DB1의 데이터를 DB2에 어떻게 쓸것인지에 대한 문제가 발생하는 것이다.
DB확장성 확보의 어려움
DB가 디스크I/O를 많이 발생시키면 속도차 문제가 생기고 데이터가 커질수록 메모리에서 처리못하고 디스크에서 처리하게 된다.즉 대규모 환경에서는 I/O부하를 담당하는 서버는 분산이 어렵고 부하가 커지면 느려진다.
멀티태스킹 OS와 부하
OS는 여러 동시에 여러 태스크를 처리할 수 있지만 동시에 CPU,디스크를 공유하며 짧은 시간 동안 태스크를 전환하여 태스크를 처리한다.태스크가 많아지면 다른 태스크는 지연된다.top의 Load Average가 높으면 태스크지연이 발생한다는 표시이므로 지연(부하)가 높은 상태이다.하드웨어는 일정주기도 인터럽트(interrupt)라는 신호를 보낸다.보통4ms이다.이 인터럽트마다 CPU는 실행중인 프로세스가 CPU를 얼마나 사용하는지등을 계산하며 이때 Load Average도 계산된다.커널은 실행대기프로세스와 디스크I/O완료대기 프로세스의 수이다.
대규모 데이터를 다루기 위한 기초지식
대규모 데이터를 다루는 세 가지 핵심
1.어떻게 메모리에서 처리를 마칠것인가?
메모리에서 처리를 끝내야 디스크 seek횟수를 줄여 확장성,성능에 큰 영향을 미친다.
2.데이터량 증가에 강한 알고리즘 사용하기
레코드 1,000만건을 선형탐색으로 구현시 1,000만번 계산해야 하지만 Log Order알고리즘을 적용하면 수십만번만에 마칠 수 있다.
3.데이터 압축이나 검색기술 테크닉 활용하기
데이터를 압축하면 디스크읽기횟수를 줄일 수 있으며 메모리캐싱이 쉬워진다.검색은 확장성 면에서 DB에서만 처리하기 힘들때 검색엔진을 활용하여 속도를 확보할 수 있다.
OS 캐시와 분산
OS의 캐시 구조
OS의 캐시 구조 상세
OS는 메모리를 이용하여 디스크 엑세스를 줄인다.그 원리가 OS캐시이다.Linux의 경우 페이지캐시,파일캐시,버퍼캐시라는 캐시구조를 가지고 있다.OS는 가상메모리구조를 가지고 있는데 선형어드레스=>페이지구조=>물리 어드레스순으로 논리적인 선형 어드레스를 물리적인 물리 어드레스로 변환시킨다.
가상 메모리 구조
메모리에는 32비트의 주소값이 있다.어드레스르 직접 프로세스에서 사용할 경우 문제가 발생한다.메모리가 필요할 경우 OS가 비어있는 메모리를 찾고 OS는 메모리로부터 반환된 값이 아닌 다른 메모리주소값을 프로세스에 전달한다.그 이유는 프로세스는 어느 메모리를 사용하는지 관여하지 않고 반드시 특정 번지부터 시작하는것으로 정해져 있으며 다루기 쉽기 때문이다.메모리를 확보할때도 1바이트씩 엑세스하지 않고 4kb씩 블록으로 확보하여 프로세스에 넘기고 각 블록을 페이지라 한다.OS는 프로세스에서 메모리를 요청받으면 페이지를 확보하여 프로세스에 넘기는 작업을 수행한다.
Linux 페이지 캐시 원리
OS는 확보한 페이지를 메모리상에 계속 확보하는 기능이있다.프로세스가 디스크로 부터 데이터를 읽을때 디스크로부터 4kb의 블록을 읽어 메모리상에 쓰기작업을 한다.프로세스는 디스크에 직접 엑세스 할 수 없기에 메모리를 통해 읽어야 한다.OS는 디스크블록이 쓰인 메모리 주소(가상 주소)를 프로세스에 알려주어 엑세스한다.프로세스가 데이터 처리를 끝내도 다른 프로세스가 해당 메모리를 사용할 경우 디스크를 읽으러 갈 필요가 없으므로 할당된 메모리를 해제하지 않는다.이것이 페이지 캐시이다.
리눅스에서 디스크데이터를 읽는다면 반드시 메모리를 거쳐 가므로 두번째 엑세스부터 빨라진다.OS가 가동하는동안 계속 메모리한도내에서 계속 캐싱하므로 빨라진다.부팅직후에는 캐시가 없으므로 다소 버벅이는것 처럼 보이기도 한다.
VFS(Virtual File System)

디스크 캐시는 페이지 캐시에 의해 제공되지만 실제 디스크조작하는 디바이스 드라이버와 OS 사이에 파일시스템이 있다.리눅스에는 ext2,xfs등 파일시스템이 있고 하위에 디바이스 드라이버가 있다.파일시스템위에 VFS라는 추상화 레이어가 있다.파일시스템의 다양한 함수를 통일시켜준다.VFS가 페이시 캐시구조를 가지고 있어 어떤 디스크를 읽어도 동일 구조로 캐시된다.
Linux의 디스크 캐시 단위
디스크에 4GB의 파일이 있고 여유 메모리가 1.5GB밖에 없다면 어떻게 캐싱을 처리할까?OS는 4kb블록(페이지)만 캐싱하므로 특정 파일의 일부분만 캐싱한다.4GB파일을 전부 읽는다면 LRU(Least Recently Used)즉 오래된것을 지우고 새로운것을 남긴다.따라서 DB도 계속 구동하면 캐시가 최적화되어 I/O부하가 내려간다.
메모리증가로 I/O부하 줄이기
메모리를 늘리면 캐시용량이 늘어나 디스크 읽기가 줄어든다.sysstat패캐지를 설치하여 sar -f 명령어로 프로세스의 시간대별 I/O대기를 확인할 수 있다.
