해당 글은 소프트웨어 마에스트로 15기 과정에서 진행 중인 "설문이용"을 개발하며 겪은 경험을 정리한 것입니다.
0️⃣ 배경 - 부하 테스트로 서비스가 요구사항을 충족하는지 확인해보자!
진행 중인 프로젝트 "설문이용"의 AI 설문 제작 기능까지 완료되고 곧 배포를 앞두고 있었다.
우리 팀은 배포에 앞서 우리가 예상한 시나리오에 대하여 서비스가 잘 동작할 수 있는지 파악하고자 했다.
그래서 가장 많이 발생할 것으로 예상한 "설문 참여 시나리오"의 기능적 요구사항과 비기능적 요구사항을 정리하고, 이를 바탕으로 부하 테스트를 진행한 과정과 결과를 정리해보았다.
목차
1️⃣ 시나리오 작성
2️⃣ 부하 테스트 준비
3️⃣ 부하 테스트 진행 및 결과 분석
4️⃣ 개선 결과 및 비교
1️⃣ 시나리오 작성
우선, 정말 우리 서비스가 닥칠 수 있는 현실적인 미래를 바탕으로 아래와 같이 시나리오를 작성했다.
어떤 상황에서?
- 하루 평균 50건의 설문이 생성된다.
- 하나의 설문에 평균 50명의 참가자와 10개의 질문이 존재한다.
- 3개월간 운영 중인 상태이다.
어떤 기능을? (기능적 요구사항)
- 설문 참여 과정을 수행할 수 있다. (설문 조회 → 응답 제출 → 통계 확인)
어떤 성능으로? (비기능적 요구사항)
- 2시간 동안 설문 참여 과정을 1250번 수행할 수 있다.
하루 동안 발생하는 설문 참여 건 수=하루 동안 생성되는 설문 수 * 평균 참여자 수=2500- 이 중 피크 시간대 2시간 동안 전체 요청의 50%가 발생 →
1250
- 각 API 요청의 평균 응답 시간은 200ms 미만이여야 한다.
- 단, 설문 응답 API는 외부 서비스를 호출하므로 400ms 미만으로 조정한다.
2️⃣ 부하 테스트 준비
더미 데이터 삽입
부하 테스트에 앞서 요구사항에 맞게 더미 데이터를 삽입하는 API를 구현하였다. PR 링크
더미 데이터의 구성은 아래와 같다.
| 컬렉션 | 개수 | 이유 |
|---|---|---|
| 설문 | 4500 | 3개월 동안 매일 50건 생성 → 90 * 50 = 4500 |
| 유저 | 450 | 유저 1명 당 설문 10건 생성 → 4500 / 10 = 450 |
| 참가자 | 225000 | 한 설문에 50명 참가 → 4500 * 50 = 225000 |
| 응답 | 2574000 | 한 설문에 10개의 질문, 필수 답변 질문과 다중 선택 질문으로 인한 변수 → 225000 * 10 * 0.88 * 1.3 = 2574000 |
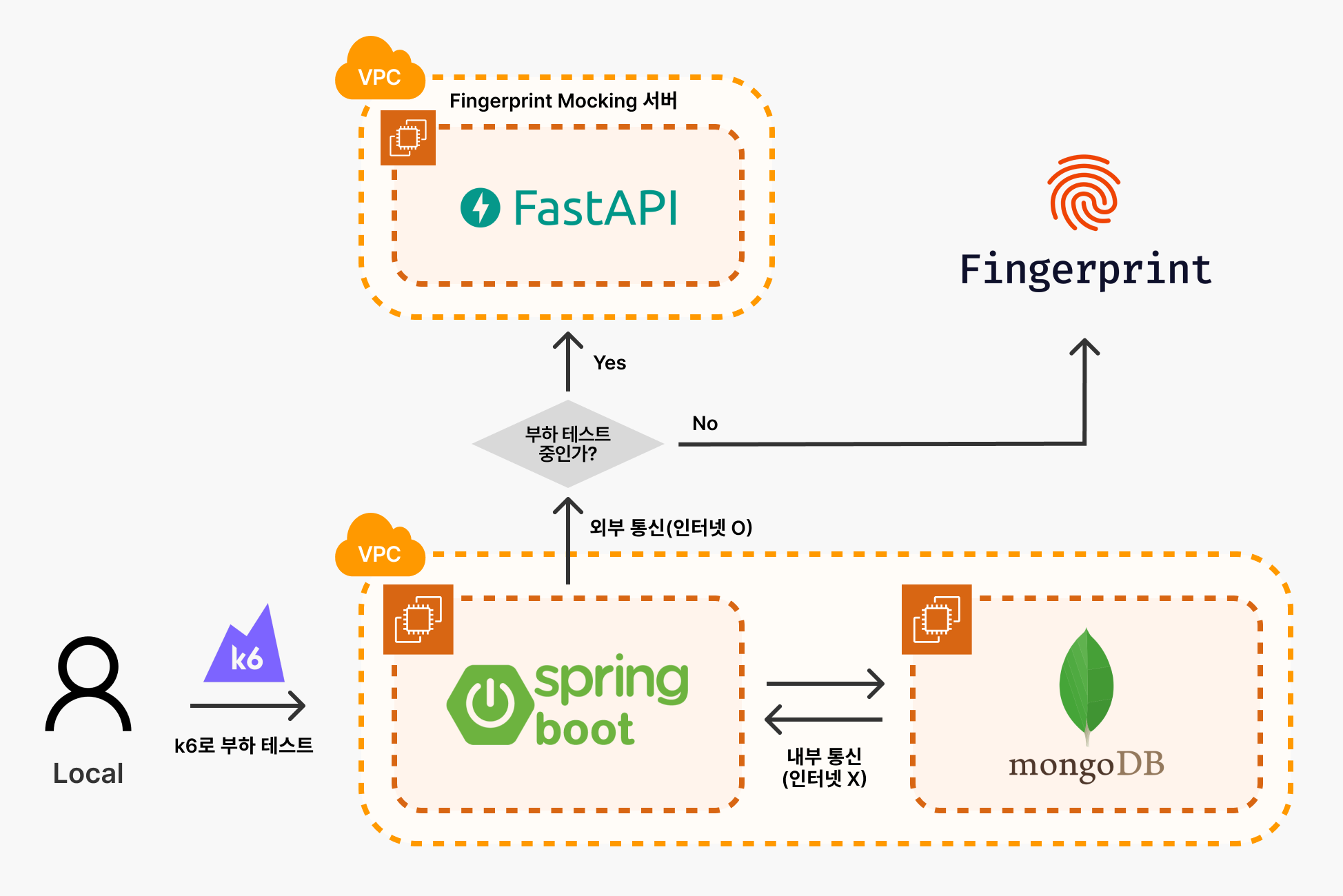
외부 서비스 모킹 서버 구성
현재 설문 응답 시 중복 참가자 검사를 위해 Fingerprint라는 외부 서비스를 이용하고 있다.
하지만, 해당 서비스에는 요청 수 제한이 있고, 이를 초과하면 추가 비용이 발생하기 때문에 부하 테스트로 많은 호출을 할 수 없었다.
그래서, 위와 같이 부하 테스트를 진행 중이면 외부 네트워크에 별도로 구성한 Fingerprint Mocking 서버로 요청을 보내도록 하였다. Repository 링크
Fingerprint Mocking 서버는 API 요청을 받으면 Fingerprint API의 평균 응답 시간인 175ms 뒤에 요청을 반환하도록 구현하였다.
스크립트 작성 & 결과 저장 및 시각화(k6 & InfluxDB & Grafana)
다른 부하 테스트 도구에 비해 성능이 가장 좋고, 시나리오 기반의 테스트가 가능한 k6로 스크립트를 작성했다.
스크립트가 긴 관계로, 자세한 코드는 이곳에서 확인할 수 있다.
또한, 테스트 결과를 저장하고 이를 쉽게 확인하고 분석하기 위해 InfluxDB와 Grafana를 로컬 환경에 세팅하였다. Repository 링크
Grafana 대시보드는 해당 링크의 대시보드를 조금 커스텀하여 각 API의 응답과 시나리오 성공률 등을 볼 수 있도록 하였다.
3️⃣ 부하 테스트 진행 및 결과 분석
진행 과정
- 5분 동안 50회의 시나리오를 완료할 수 있는지 확인한다.
- 갑작스럽게 요청이 몰리는 경우를 확인하기 위하여 5분 동안 250회의 시나리오를 완료할 수 있는지 확인한다.
- 다시 5분 동안 50회의 시나리오를 완료할 수 있는지 확인한다.
테스트 결과 - 3개의 API가 요구사항 달성에 실패
테스트 결과, 설문 응답 API, 설문 결과 조회 API, 참가자 목록 조회 API의 응답 시간이 요구사항을 달성하지 못하였다.
문제점 찾기 - 왜 느릴까?
APM이 제공하는 Breakdown Table을 통해 요구사항을 달성하지 못한 3가지 API들의 세부 동작과 소요 시간을 확인해보았다.
- 설문 결과 API
- 참가자 목록 조회 API
- 설문 응답 API
위 자료들을 확인해보면, 세 API 전부 공통적으로 MongoDB 쿼리가 대부분의 응답 시간을 차지하는 것을 확인할 수 있었다.
각 쿼리들이 왜 느린지 분석하기 위해 MongoDB의 slow query log를 분석하였다.
-
responses find & getMore
{ "attr.command.filter.surveyId.$uuid": "613e7ee7-11a2-4016-a35d-856e19336fb2", "attr.command.find": "responses", "attr.cursorid": 28276713418472440, "attr.docsExamined": 1698444, "attr.durationMillis": 58192, "attr.nreturned": 101, "attr.planSummary": "COLLSCAN", }확인해보면, 우선 find 명령으로 surveyId가
613e7ee7-11a2-4016-a35d-856e19336fb2인 응답을COLLSCAN방식(컬렉션 전체를 스캔)으로 먼저 101개 찾는다.{ "attr.command.collection": "responses", "attr.command.getMore": 28276713418472440, "attr.cursorExhausted": true, "attr.docsExamined": 863996, "attr.durationMillis": 25245, "attr.nreturned": 534, "attr.planSummary": "COLLSCAN", }그 다음, find 명령으로 생성된 커서를 통해 나머지 데이터 534개를 찾아서 반환한다.
결국 가장 큰 문제는 surveyId에 해당하는 응답들을 찾는 과정에서 컬렉션 전체를 탐색하는 것이 가장 큰 문제이다.
-
participants find & getMore
{ "attr.command.filter.surveyId.$uuid": "2b051e6a-4d92-4ad9-b34c-7e4b7de89377", "attr.command.find": "participants", "attr.cursorid": 1970698316047089400, "attr.docsExamined": 109091, "attr.durationMillis": 2728, "attr.nreturned": 101, "attr.planSummary": "COLLSCAN" }responses와 동일하게, find 명령으로 surveyId가
2b051e6a-4d92-4ad9-b34c-7e4b7de89377인 참가자를 COLLSCAN 방식(컬렉션 전체를 스캔)으로 먼저 101개 찾는다.{ "attr.command.collection": "participants", "attr.command.getMore": 1970698316047089400, "attr.cursorExhausted": true, "attr.docsExamined": 110830, "attr.durationMillis": 2762, "attr.nreturned": 101, "attr.planSummary": "COLLSCAN" }그 다음, find 명령으로 생성된 커서를 통해 나머지 데이터 101개를 찾아서 반환한다.
여기도 마찬가지로 결국 가장 큰 문제는 surveyId에 해당하는 참가자들을 찾는 과정에서 컬렉션 전체를 탐색하는 것이 가장 큰 문제이다.
4️⃣ 개선 및 결과 비교
개선하기 - responses와 participants의 surveyId 속성에 대해 index 생성
결국 가장 큰 문제는 응답과 참가자를 조회할 때 surveyId에 대해 index가 없어서 컬렉션 전체를 조회하는 것이었다.
그래서, responses 컬렉션과 participants 컬렉션의 surveyId에 대해 아래와 같이 index를 생성해주었다.
db.responses.createIndex({ surveyId: 1 })
db.participants.createIndex({ surveyId: 1 })- 물론, 인덱스를 생성하게되면 쓰기 작업의 속도가 느려진다는 사이드 이펙트가 발생할 수 있지만, 읽기 속도가 너무 느린 상태이므로, 다시 부하 테스트를 진행하고 결과를 비교해보기로 했다.
2차 부하 테스트 진행 결과
index의 효과는 굉장했다… 모든 API가 요구사항을 만족시켰다.
개선 전과 후의 응답시간을 비교해보면 확연한 차이를 보인다. 또한, 쓰기 작업이 있는 설문 응답 API도 요구사항을 만족했기 때문에 걱정했던 사이드 이펙트는 큰 영향이 없는 것으로 나타났다.
성과
responses 컬렉션과 participants 컬렉션에 각각 surveyId에 대한 index를 생성한 결과 아래와 같은 성과를 거두었다.
- 설문 결과 조회 API
- 18.45s → 38.12ms (약 99.8% 감소)
- 참가자 목록 조회 API
- 4.01s → 24.32ms (약 99.4% 감소)
- 설문 응답 API
- 3.95s → 263.49ms (약 93.3% 감소)
5️⃣ 느낀점
이전에 서비스를 개발했을 땐 대충 "어느정도는 버티겠지?"라고 생각하고, 문제가 닥치고 나서야 급하게 해결했던 기억이 난다.
이번 기회에 서비스 사용 시나리오를 꼼꼼하게 작성하고, 이를 바탕으로 부하 테스트를 진행해보니 놓쳤던 문제를 조기에 발견할 수 있어서 좋았다. 또한, 1분에 설문 참여를 50번 해도 문제가 없다는 것을 확인하면서 서버의 처리량을 확실히 알 수 있었고, 앞으로 서비스 운영에 안정감이 생겨서 좋았다.
마지막으로, 이 글의 주인공인 설문이용… 많은 관심 가져주시면 감사하겠습니다 🙇♂️
- 설문이용은, 설문 제작에 어려움을 겪는 사용자들이 ai를 활용해서 간단하게 설문을 만들고, 사용하기 어려운 외부 도구 없이 쉽게 설문 결과를 분석할 수 있도록 도와줍니다! 설문이용 시작하기
