HTTP 에 대해서 간단히 알아보자
HTTP

키워드
- HTTP(Hypertext Transfer Protocol)
- HTTP와 HTTPS의 차이(TLS)
- 클라이언트-서버 모델
- stateless와 stateful
- HTTP Cookie와 HTTP Session
- HTTP 메시지 구조
- HTTP 요청(Request)와 응답(Response)
- multipart/form-data
- HTTP 요청 메서드(HTTP request methods)
- 멱등성
- HTTP 응답 상태 코드(HTTP response status code)
- 리다이렉션
- HTTP 요청(Request)와 응답(Response)
최종 목표
HTTP 에 대해서 간단히 알아보고 직접 구현해보자.
웹의 핵심 요소인 HTTP는 웹 개발자에게 있어서 필수적으로 알아야 하는 지식이다. 그러나 상당수의 개발자들이 HTTP가 어떠한 원리로 동작하는지 제대로 알지 못하고 있다. 이번 과정을 통해 HTTP 통신을 처리하는 웹 서버가 의외로 간단한 원리로 구현되어 있다는 걸 알게 될 것이다. 직접 간단한 웹 서버를 구현해보면서, HTTP를 제대로 이해하고 동시에 Spring Web MVC가 어떤 편의를 제공하는지 절실하게 느껴보자.
현재 목표
HTTP 에 대해서 간단히 알아보자.
HTTP 란?
다음은 MDN 에 적힌 HTTP 의 정의이다. 하나씩 알아보자.
하이퍼텍스트 전송 프로토콜(HTTP)은 HTML과 같은 하이퍼미디어 문서를 전송하기 위한 애플리케이션 레이어 프로토콜입니다.
웹 브라우저와 웹 서버간의 통신을 위해 설계되었지만 다른 목적으로도 사용할 수 있습니다.
HTTP는 클라이언트가 요청을 하기 위해 연결을 연 다음 응답을 받을때 까지 대기하는 전통적인 클라이언트-서버 모델을 따릅니다.
HTTP는 무상태 프로토콜이며, 서버가 두 요청 간에 어떠한 데이터(상태)도 유지하지 않습니다.
아래 개념 3개를 알아보면서 HTTP 에 대해 알아보자.
개념1: 애플리케이션 레이어 프로토콜
개념2: 클라이언트-서버 모델
개념3: 무상태 프로토콜
프로토콜 이란?
규칙의 집합, 규약, 약속이다. 무언가를 전송할 때 어떤 방식으로 할 지에 대한 약속이다.
우리가 우측 통행하는 이유도 프로토콜처럼 약속이기 때문이다. 약속에는 항상 생긴 이유가 있다. 우측 통행은 그냥 가면 부딪히기 때문에 생긴 것이다.
개념1: 애플리케이션 레이어 란?
애플리케이션 레이어는 여러 의미로 쓰이지만, 여기서는 OSI 7계층을 이용해서 설명하겠다.
OSI 7계층 이란?
우리가 네트워크로 통신을 할 때 이런 계층을 통해서 한다.
- 응용 계층
- 표현 계층
- 세션 계층
- 전송 계층
- 네트워크 계층
- 데이터 링크 계층
- 물리 계층
실제로 7개의 계층을 모두 적용하지는 않는다.
대부분 1, 2, 3, 4 계층까지만 하고 바로 7 계층으로 넘어간다.
우리는 2, 3, 4, 7 계층만 살펴보자. 1계층인 물리 계층은 정말로 기계에 대한 내용이기 때문이다.
2, 3, 4, 7 계층?
- 2계층 - 데이터 링크 계층 ⇒ MAC address
- 3계층 - 네트워크 계층 ⇒ IP address
- 4계층 - 전송 계층 → TCP, UDP ⇒ Port number
- 7계층 - 응용 계층 → HTTP 등
- HTTPS를 위한 TLS 같은 보안 계층이 먼저 들어갈 수도 있다.
기기를 사면 MAC Address 가 할당된다. (2계층)
인터넷을 연결하면 IP Address 가 할당된다. (3계층)
Port Number 는 프로그램에서 지정한다. (4계층)
2, 3, 4 계층은 기본적으로 주어지는 것들이다.
2계층은?
- 2계층 - 데이터 링크 계층 ⇒ MAC address
2계층은 소프트웨처 측면에서 하드웨어를 추상화한 것이다.
기기 같은 것을 구분을 하기 위해서 MAC Address 를 쓴다.
그래서 MAC Address 는 사실상 하드웨어에서 얻는 것이다.
3계층 이란?
- 3계층 - 네트워크 계층 ⇒ IP address
3계층에서는 IP Address 를 쓴다. (2계층에서 MAC Address 를 쓰는 것처럼)
IP 는 인터넷 프로토콜이다. 서로 멀리 떨어져 있는 애들끼리 서로를 인식하는 방법 중에 하나이다.
4계층 이란?
- 4계층 - 전송 계층 → TCP, UDP ⇒ Port number
내 컴퓨터에는 여러 가지가 프로그램이 돌아갈 수 있다.
그래서 컴퓨터 대 컴퓨터를 연결이 아닌 프로그램 대 프로그램 연결을 얘기해보자.
두 프로그램을 연결해야 하는데, 먼저 IP Address 로 기기를 찾는다. 그리고 그 다음에 내 프로그램이 어떤 걸 쓴다는 것을 나타내기 위해서 Port Number 를 쓴다.
7계층 이란?
- 7계층 - 응용 계층 → HTTP 등
- HTTPS를 위한 TLS 같은 보안 계층이 먼저 들어갈 수도 있다.
2, 3, 4 계층을 적용하고 나머지는 건너 뛰어서 7계층으로 왔다. 7계층은 HTTP 같은 걸 의미한다.
2, 3, 4 계층은 기본적으로 주어진 느낌이라 인프라 개념인데, 7계층은 웹 브라우저라는 특별한 프로그램을 써서 직접 프로그램을 만든 것이다.
7계층 HTTPS 란?
- 7계층 - 응용 계층 → HTTP 등
- HTTPS를 위한 TLS 같은 보안 계층이 먼저 들어갈 수도 있다.
HTTPS 는 보안 프로토콜이다. HTTPS 는 HTTP 와 별개로 따로 있는 게 아니다. TLS 하나를 거쳐서 HTTP 를 그대로 쓴다고 생각하면 된다.
이는 아래 사진을 보면 TLS 같은 보안 계층이 먼저 들어갈 수 있다.
Web 이란?
우리가 WEB 이라고 부르는 것은 파란색 박스 부분을 제외한 부분이다. 즉, HTTP 부터 위에 것들이다. 이것들을 통틀어서 WEB 이라고 한다. 웹을 공부한다고 하면 범위가 이렇게 된다고 생각하면 된다.
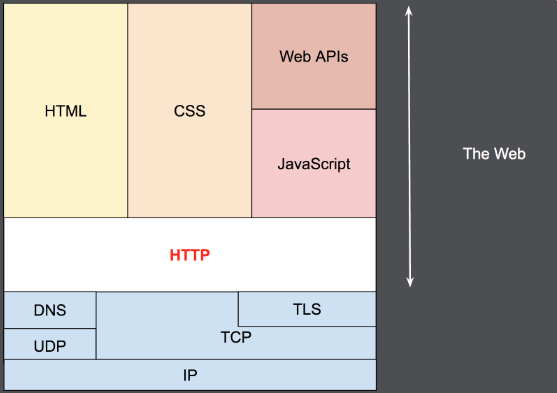
그리고 사진을 다시 보며, 구조에 대해 파악해보자.
IP 부터 시작한다. 우리가 어딘가에 접속할 때 MAC Address 를 쓰지 않는다. 내 MAC Adrress 로컬에서만 인지할 수 있고 원격에서 알 수 없다. 그래서 원격에서 알 수 있는 IP부터 시작하는 것이다.
IP가 있고 그 위에다가 TCP나 UDP를 얹을 수 있다. 그 다음에 DNS 같은 것들도 얹을 수 있다.
그래서 일단 기본적으로 IP에 TCP 를 얹고 그 위에 HTTP 가 올라간다고 생각하면 된다.
개념2: 클라이언트-서버 모델 이란?
- 서비스/리소스 → URL
- scheme://host:port/path?query#fragment - 클라이언트 → 요청
- 서버 → (처리) → 응답
서비스 개념에서 보자. 클라이언트는 고객이고 서버는 종업원이다. 고객이 "햄버거 하나 주세요" 라는 요청을 보내면 종업원은 햄버거를 만들어서 준다. 이 과정은 요청, 처리(햄버거를 만드는 처리), 응답이 이루어진 것이다.
이때 처리는 명확히 나와야 한다. "햄버거 하나 주세요" 가 명확해지기 위해서 중요한 부분은 어디일까? 리소스 즉, "햄버거" 이다.
응답할 때 리소스를 얻어서 처리한다. 그리고 처리한 내용을 HTML 과 같은 하이퍼미디어 문서의 형태로 돌려준다.
리소스는 URL 을 이용해서 드러낼 수 있다.
개념3: 무상태 란?
HTTP는 각각의 요청이 독립적이다. 그래서 클라이언트는 항상 자신이 누구인지 알려줘야 한다.
무상태 특징에 대해 알아보자.
특징1: HTTP는 각각의 요청이 독립적이다
HTTP는 각각의 요청이 독립적이다.
예를 들어서, 햄버거 가게에 가서 "햄버거 주세요" 를 말하고 "콜라도 주세요" 라고 말한다면, 내가 두 개를 같이 주문한 사람인 것을 알기 때문에 한 꺼번에 내어준다.
하지만 HTTP 는 그렇지 않다. 각각의 요청이 독립적이다. 한 꺼번에 받고 싶다면, "저는 A 입니다. 햄버거 주세요" 를 말하고 "저는 A 입니다. 콜라를 주세요" 라고 말해야 한다.
결국 항상 내가 누구인지 알려줘야 한다는 의미이다.
특징2: 그래서 클라이언트는 항상 자신이 누구인지 알려줘야 한다
HTTP는 각각의 요청이 독립적이다. 그래서 클라이언트는 항상 자신이 누구인지 알려줘야 한다.
그렇다면 내가 누구인지 유지시키면 되지 않을까? 어떤 방법을 쓸 수 있을까? 클라이언트가 자신이 누구인지 알려주는 방법은 다음과 같다.
특징2: 내가 누군인지 유지시키는 방법은?
1. 요청과 응답을 통해 계속 주고 받는 쿠키
요청과 응답에 어떤 값들을 계속 넣으면 된다.
내가 어떤 값을 넣어서 서버에 요청한다. 그러면 서버에서는 요청받았던 값을 그대로 돌려주거나 조작해서 돌려준다.
2. 데이터는 서버에서 관리하고 쿠키 등으로 key를 관리하는 세션
예를 들어보자.
클라이언트: "나 처음이야"
서버: "그럼 너는 123 이라고 부를게"
서버: "123 에 대한 데이터를 어딘가에 저장할게."
123 은 클라이언트의 세션 키가 된다. 세션 자체는 서버에서 관리하지만, 세션에 대한 키는 대게로 쿠키에서 관리한다.
그리고 위에서 말했듯이 쿠키는 요청할 때마다 계속 전달이 된다. 그래서 무겁다.
예전에는 쿠키를 이용하지 않고 URL에 넣기도 했다. 지금은 절대 이렇게 하지 않는다.
3. 웹 브라우저의 기능 (localStorage 등)
만약, 보편적인 리소스에 접근할 때도 내가 누군지 식별하는 게 필요할까? 그냥 가벼운 요청에서는 식별하지 않게 하는 방법은 없을까?
서버에서 관리되고 있는 데이터에 세션 키를 가지고 매칭해본다. 그리고 로컬 스토리지에 넣는다. 그러면 클라이언트가 독자적으로 데이터를 가질 수 있다.
HTTP 메시지 란?
클라이언트가 요청을 하면 그 요청에 대한 결과인 응답을 서버한테 받는다. 여기서 서로 주고 받는 것을 메시지 라고 한다. 서로 주고 받는 행위는 트랜잭션 이라고 한다.
HTTP 메시지의 특징은 다음과 같다.
- 기본적으로는 사람이 읽을 수 있는 형태이다.
- 요청과 응답 모두 동일 구조이다.
- Start line → 요청과 응답의 형태가 다르다.
- Headers
- 빈 줄
- Body
- 크기를 알기 어렵다. Headers의 Content-Length 항목 등을 활용한다.
- 위와 다르게 꼭 사람이 읽을 수 있는 텍스트 형태일 필요는 없다. 바이너리 등 가능.
- 하나가 아니라 여럿일 수도 있다. 파일 업로드 등을 위해 쓰이는 multipart/form-data가 대표적.
특징1: 기본적으로는 사람이 읽을 수 있는 형태이다
트랜잭션을 통해서 서로 메시지를 주고 받는다. 이때 HTTP 에서는 기본적으로 사람이 읽을 수 있는 형태로 주고 받게 되어있다.
HTTP 와 반대로 사람이 읽을 수 없을 형태를 주고 받는 예시를 생각해보자.
온라인 게임이 그 예시가 될 수 있다. 온라인 게임을 만들 때는 123 이라는 숫자를 보낼 때 바이너리 형태로 보낸다면 1바이트로 충분히 보낼 수 있다.
이렇게 퍼포먼스를 많이 요구하는데서는 이렇게 바이너리 형태를 많이 쓴다. 아니면 해킹을 막기 위한 목적으로 암호화를 해서 보내기도 한다.
하지만 기본적으로 HTTP 에서는 사람이 읽을 수 있는 형태를 지향한다. 사람이 읽을 수 있으면 디버깅도 쉽고 처리도 쉽다.
특징2: 요청과 응답 모두 동일 구조이다
HTTP 메시지는 요청할 때와 응답할 때를 비교했을 때 완전히 다른 모양으로 만들 수 있지만,
기본적인 구조는 동일하다. HTTP 메시지의 구조에 대해 알아보자.
HTTP 메시지의 구조 란?
HTTP 메시지의 구조는 총 4가지로 구성된다.
- Start line
- 요청과 응답의 형태가 다르다.
- Headers
- 빈 줄
- Body
- 크기를 알기 어렵다. Headers의 Content-Length 항목 등을 활용한다.
- 위와 다르게 꼭 사람이 읽을 수 있는 텍스트 형태일 필요는 없다. 바이너리 등 가능.
- 하나가 아니라 여럿일 수도 있다. 파일 업로드 등을 위해 쓰이는 multipart/form-data가 대표적.
Body 의 특징은?
특징1: 크기를 알기 어렵다
Body 의 크기를 알기 어렵기 때문에 다 받았는지 알 수가 없다.
→ 그래서 Headers의 Content-Length 항목 등을 활용한다. Content-Length 항목의 크기만큼 받을 수 있다.
특징2: 위와 다르게 꼭 사람이 읽을 수 있는 텍스트 형태일 필요는 없다
Start line 과 Headers 는 사람이 읽을 수 있는 텍스트 형태이다. 하지만 Body 는 아닐 수 있다.
Start Line 과 Headers 는 사람이 읽을 수 있는 텍스트 형태인데, Body 만 바이너리 같은 형태로 가능하다.
→ 바이너리 등 가능
특징3: 하나가 아니라 여럿일 수도 있다
→ 파일 업로드 등을 위해 쓰이는 multipart/form-data가 대표적
HTTP Method 란? (요청)
'주소에 대해 무엇을 할 지'를 HTTP 메서드를 통해서 결정한다.
- GET → Read
- HEAD → GET without body
- POST → Submit (멱등성X) ⇒ Collection Pattern에서 Create로 사용
- PUT → Update (+Create) ⇒ Overwrite!
- PATCH → Update (partial) (멱등성X)
- DELETE → Delete
- OPTIONS → 지원 확인
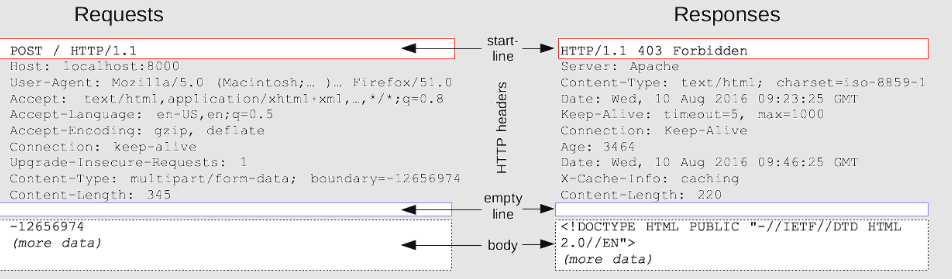
이미지에서 Requests 부분에
주소는 '/' 이다.
버전은 HTTP 1.1 이다
최신 버전이 존재하긴 우리가 일반적으로 쓰는 것은 1.1 기반이다.
2.0 을 쓰더라도 1.1 과 거의 동일한 형태를 고도화 시킨 것이다.
HEAD 란?
- HEAD → GET without body
body 없이 head 만 얻고 싶을 때가 있다. 예를 들어, 존재하지 않는 페이지를 갔을 때 존재하지 않는 다는 사실만 알면 된다. 이걸 Head 가 처리할 수 있다. 그래서 body 는 필요없다.
POST 란?
- POST → Submit (멱등성X) ⇒ Collection Pattern에서 Create로 사용
멱등성이란? 같은 것을 여러 번 해도 바뀌는 게 없는 것이다.
POST 는 멱등성을 보장하지 않는다. 회원가입을 예로 들어보자. 처음엔 됐지만 두 번째부터는 동일한 아이디가 있기 때문에 에러가 난다.
그리고 Collection Pattern 는 산업 표준처럼 쓰이는데 여기서 POST 는 '모든 데이터를 보낸다' 는 의미가 아니라 'Create' 의 의미로 제한을 건다.
PUT 란?
- PUT → Update (+Create) ⇒ Overwrite!
PUT 은 Update 또는 Create 를 하는데 POST 가 Create 용도이다 보니 PUT 은 Update 로 많이 쓰인다.
PUT 에서 Update 는 일부만 고치는 게 아니라 전체를 고치는 Overwrite
이다.
예를 들어보자. 회원 정보에서 이름을 수정하려고, PUT 으로 수정한 이름만 보냈다. 그러면 수정한 이름을 빼고 나머지 정보는 다 날아간다.
PATCH 란?
- PATCH → Update (partial=부분적) (멱등성X)
PATCH 는 나중에 추가된 HTTP Method 이다.
PATCH 는 PUT 과 다르게 부분적으로 Update 가 가능하다.
물론 실제로 코딩을 하면 PUT 과 PATCH 를 비슷하게 만들 수 있다.
하지만 원론적인 이 둘의 차이점을 잘 기억해두자.
HTTP Status Code 란? (응답)
현재 URL 과 HTTP Method 을 이용해서 리소스를 어떻게 해달라는 요청이 왔다. 이제 어떻게 됐다라는 상태 코드를 보내주면 된다.
HTTP Status Code 는 세자리 수로 표현한다. 그리고 표준으로 정해져 있다.
- 1xx → 정보
- 우리가 직접 쓰는 일은 드믈다.
- HTTP 완벽 가이드 읽으면 알 수 있다.
- 2xx → 성공
200 OK201 Created(POST 로 요청해서 성공했다.)204 No Content(성공했는데 body 가 없다.)
- 3xx → 리다이렉션
304 Not Modified가 특수한 형태로 자주 보인다.- 304 는 응답이 안 바뀌었을 때 나온다.
- 예를 들어, 캐쉬를 날리지 않고 새로 고침을 하면 304 가 나온다.
- 4xx → 클라이언트 쪽 문제
- 404 Not Found
- 5xx → 서버 쪽 문제
- 500 Internal Server Error
- 서버 내부 에러이다.
- 500 Internal Server Error
이미지에서 Responses 를 보면 버전, HTTP Status Code, HTTP Status Message 이 나와있다.
HTTP Status Message 는 별로 중요하지 않다. 읽을 수 있지만 실제로 쓰는 값이 아니다.
예를 들어서 HTTP Status Code 가 200 로 왔는데, HTTP Status Message 가 'Not Found' 가 왔다. 웹 브라우저는 200d은 OK 이기 때문에 성공했다고 인지하고 성공으로 처리한다. 뒤에 Message 가 'Not Found' 건 뭐건 신경쓰지 않는다.
아하! 포인트
HTTP 에 대해 처음 공부해봤다.
요청을 받았을 때, 에러에 따라서 적절한 처리를 해줄 수 있을 것 같다.
굉장히 기본적인 내용인데도 모르는 부분이 많아서 정리가 오래 걸렸다. 그래도 흐름을 놓치지 않고 따라가고 있어서 다행이다.
다음에는?
이 게시물의 내용을 코드로 구현해보자.
