
standard SQL
1.관계형 대수
- 관계형 데이터베이스(table)에서 원하는 정보를 유도하기 위한 기본 연산 집합
- 일반 집합 연살 별 SQL
union(합집합) intersect(교집합) except(차집합) cross join(카디션 프로덕트) - 순수관계 연산
selection(행연산,Ω), projection(열연산,Π), join, division(2table중 연관있는 것 만, %뒤에 있는 table과 연관이 있는 것들만 출력) 
2.집합 연산자란?
-
두 개 이상의 테이블에서 조인을 사용하지 않고 연관된 데이터를 조회하는 방법중 하나이다.
테이블에서 select한 컬럼의 수와 각 컬럼의 데이터 타입이 테이블간 상호호환 가능해야 한다.1)union
-
2개의 테이블을 하나로 만드는 연산 union에 사용할 컬럼의 수와 데이터 형식이 일치해야 하며 합친 후에 테이블에서 중복된 데이터는 제거된다.
이를 위해 union은 테이블을 합칠 때 정렬 과정을 발생시킨다. 관계형 대수의 일반 집합 연산에서 합집합의 역할을 한다. -
우선 2개의 table을 정렬한다 그다음 중복제거를 한다.
2)union all
-
union과 거의 같은 기능을 수행하나 union과 달리 중복제거와 정렬을 하지 않는다고 한다. 중복 제거를 하지 않는다는 것이 가장
큰 차이점이다.
select * from 테이블 이름
union all
select * from 테이블 이름2;3)intersect
-
2개의 테이블에 대해 겹치는 부분(공통적으로 존재하는 data)을 추출하는 연산, 추출후에는 중복된 결과를 제거한다.
-
관계형 대수의 일반 집합 연산에서 교집합의 역할을 한다.
4)except(MINUS in ORACLE)
-
2개의 테이블에서 겹치는 부분을 앞의 테이블에서 제외하여 추출하는 연산, 추출 후에는 중복된 결과를 제거한다.
-
관계형 대수의 일반 집합 연산에서 차집합의 역할을 한다.
3.계층형 질의
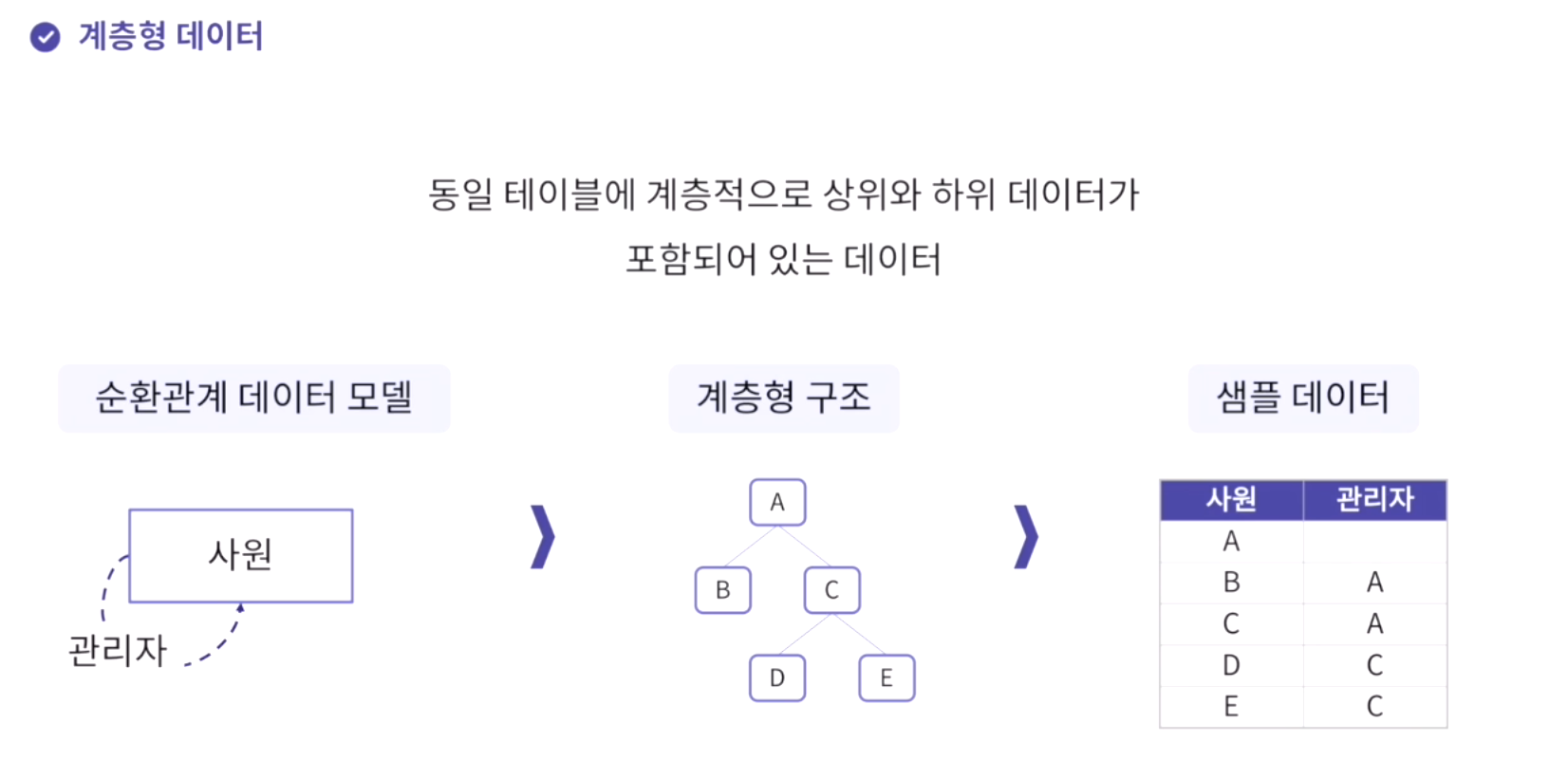
- 테이블에 계층형 데이터가 존재하는 경우 데이터를 조회하기 위해 사용하는 것이다.
- DB별로 계층형 질의가 조금씩 다른데 우선 oracle부터 알아보자
- 계층형 data는 다음과 같다.
- 문법
select LEVEL. 자식 컬럼, 부모 컬럼, 원하는 컬럼
from 테이블 명
start with 부모 컬럼 is null // 부모 컬럼이 null인 행이 root node가 됨
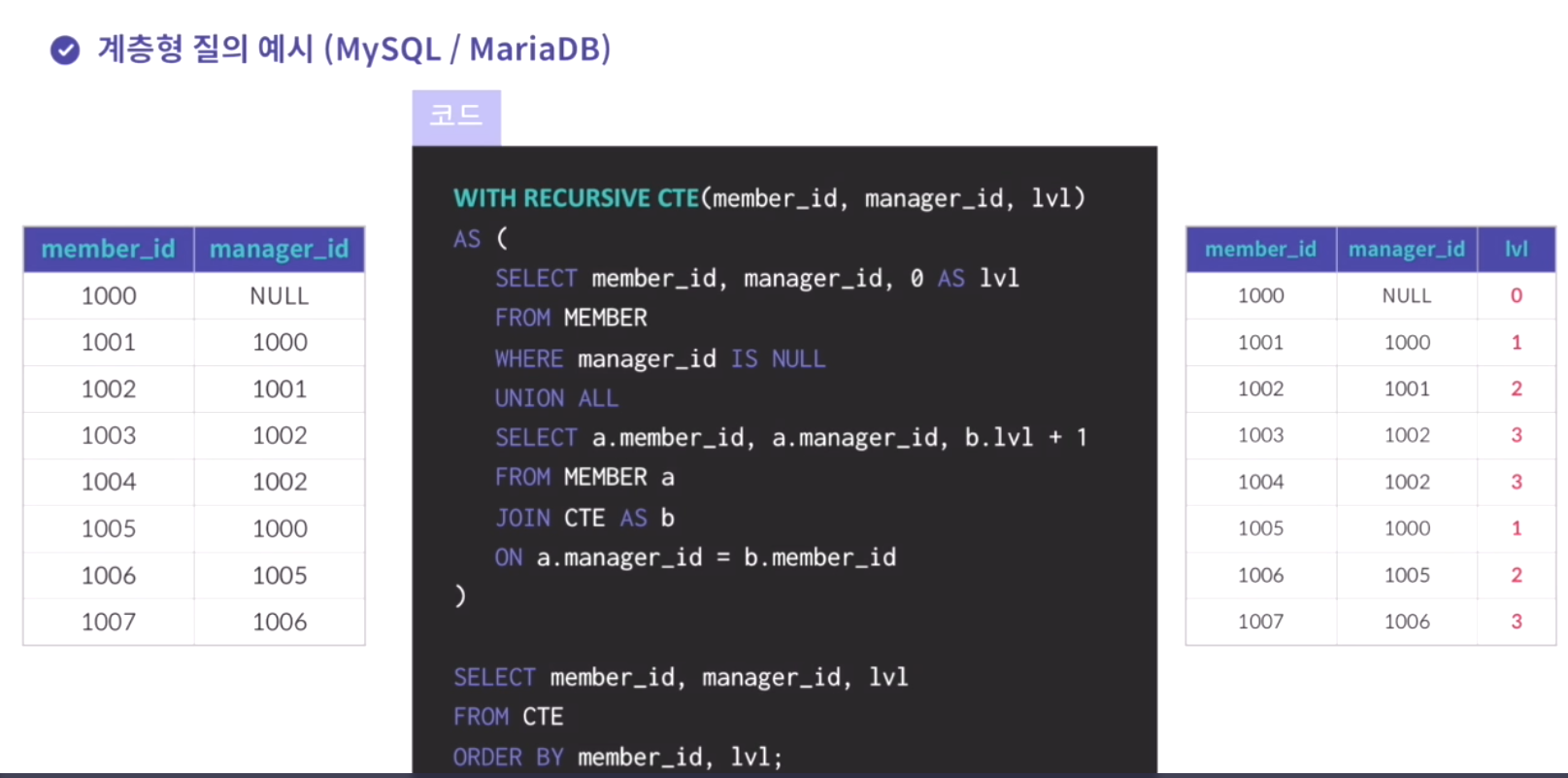
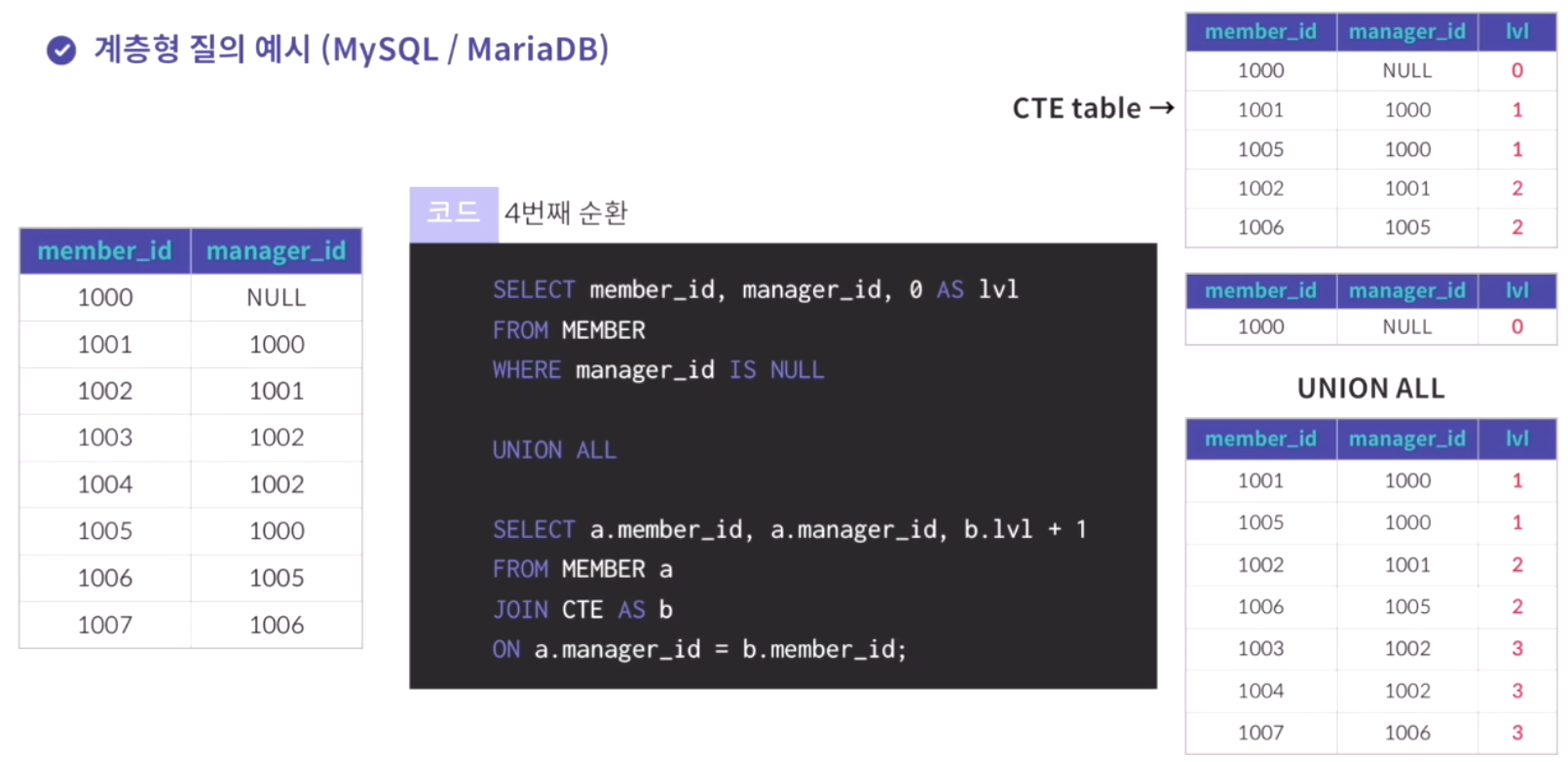
connect by prior 자식 컬럼 = 부모 컬럼; // 상위 데이터와 하위 데이터의 연결 방식1)oracle
select level, 컬럼이름, 컬럼이름 from 테이블 이름
start with 컬럼이름 is null connect by prior 컬럼이름 = 컬럼이름; //약간 셀프조인같은 느낌
매니져가 null인, 없는 즉 최상위 data를 찾겠다. 상위데이터 하위데이터select level, lpad('',4*(level-1))||사원번호, 관리자
from 테이블 이름 start with 커럼이름 is null connect by prior 컬럼이름 = 컬럼이름;2)SQL server

智(지)! 德(덕)! 體(체)!