
그룹함수 & 윈도우 함수
1. 윈도우 함수
- 문법
select window_funtion(arguments)
over([partition by 칼럼명][order by 절][wondowing절])
from 테이블 명;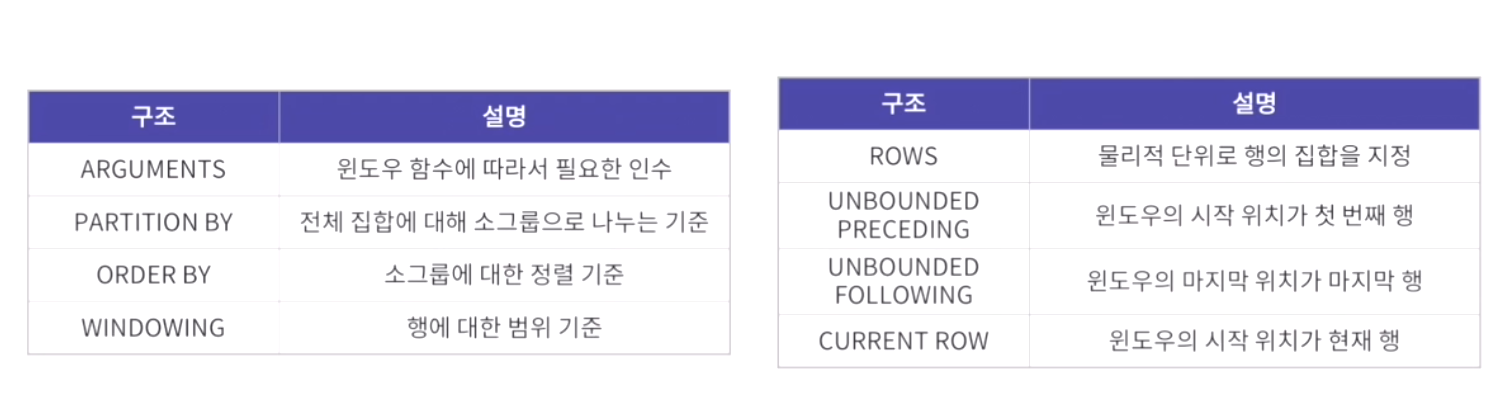
- 오른쪽 table은 windowing의 명령어들이다.
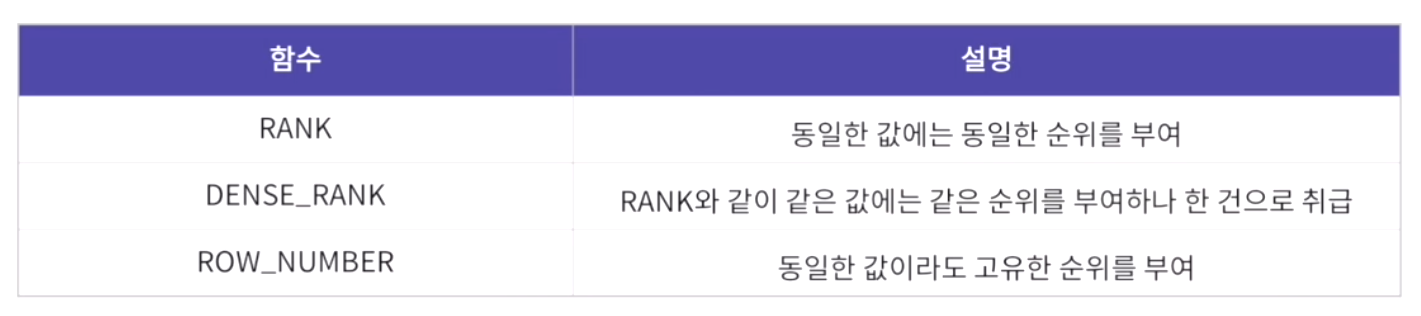
1) 순위 함수
rank() over([partition by 칼럼명][order by 칼럼명][windowing 절])

2) 일반 집계 함수
일반 집계함수(sum, avg, max, min...)을 group by 구문 없이 사용할 수 있다.
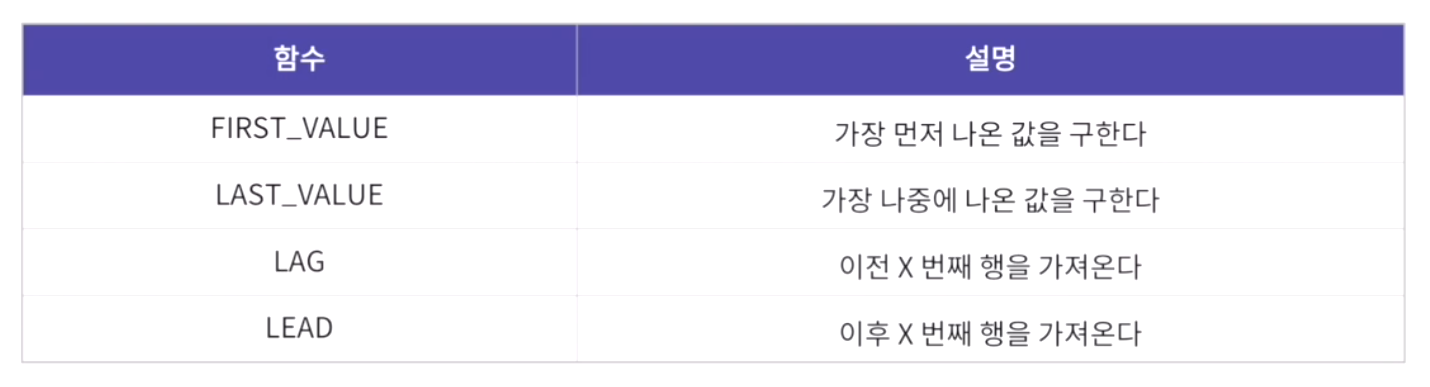
3) 그룹 내 행 순서 함수
2. 그룹함수
1) 그룹 내 비율함수

- ratio_to_report 함수는 maria db에 제공되지 않기에 sum함수로 구현하는 예시이다.

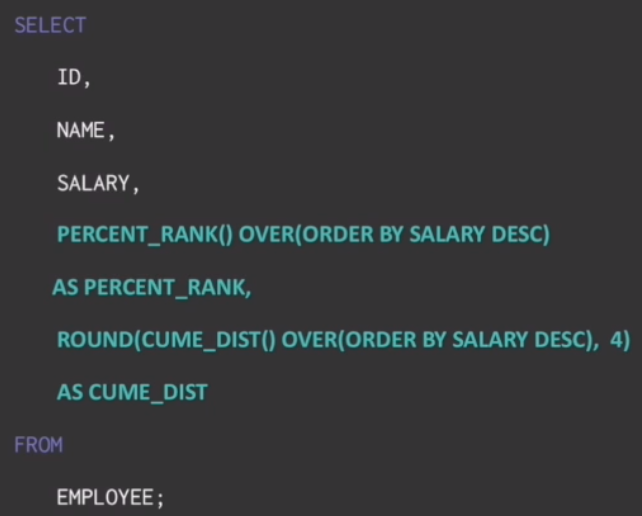
- percent_rank와 come_dist의 함수 예시
- ntile 함수예시

2) 그룹 함수란?
- 데이터를 통계내기 위해서는, 전체 데이터에 대한 통계는 물론이고 데이터 일부에 대한 소계, 중계 또한 필요하다. 각 레벨 별 SQL을 UNION문 으로 묶어 작성할 수도 있으나 ORACLE DB에서는 이러한 통계 데이터를 위한 몇가지 함수를 제공한다.
group by
- roll up : 그룹화하는 컬럼에 대한 부분적인!! 통계를 제공해준다.
~~query~~
group by roll up(talbeAlias.table1, tableAlias.table2);- cube : roll up 함수에서 제공하는 결과를 포함해서, cube함수에서는 그룹화 하는 컬럼에 대해 결합가능한 모든 경우의 수에 대해 다차원 집계를 생성한다.
group by roll up(talbeAlias.table1, tableAlias.table2);
group by roll up(talbeAlias.table2, tableAlias.table1);
# result == 다르다.
group by cube(talbeAlias.table1, tableAlias.table);
# result == 같다.- maria DB는 cube를 지원하지 않기에 roll up qeury를 2개를 이용하여 union으로 묶어주면 된다.
3) gruoping set
- 명시된 컬럼에 대해 개별 통계를 생성한다. 각 컬럼에 대해 gruop by로 생성한 통계를 모두 union all 한 결과와 동일하다.

- maria DB는 sets 를 지원하지 않기에 gruop by qeury를 2개를 이용하여 union all으로 묶어주면 된다.

智(지)! 德(덕)! 體(체)!