
다수의 talble 제어
1.데이터 그룹화
1) group by
- 문법
select column1, count(*)
from table_name
group by column1; // 그룹 기준의 컬럼.
#result
## column1이 같은 열에서 column의 개수를 출력.- limit 와 order by 처럼 group by도 쿼리 제일 마지막에 사용.
- sum, avg, count, max, min를 활용하면 더욱 좋음.
- 마치 distinct 처럼 쓰임 즉, from절 다음에 쓰이는 distinct 라고 생각하면 편할듯.
2) having
- group by 와 함게 쓰이며 data group에 조건을 적용함.
select column1, column2
from table_name
group by column1
having 조건;select column1, count(*)
from table_name
group by column1
having count(column1)>1;
#result
## column1을 기준으로 group을 묶을건데 이때 column1의 개수(count)가 1이 넘는 애들만 골라서 group화 하세요.2.여러 테이블 조회(join)
- data table을 같이 놔두면 되는데 굳이 여러개의 key를 이요하여 분리를 해놓은 이유는 뭘까?
바로 보안성 때문이다. 하나가 털리더라고 하나가 털리지 않도록 하기 위해.
1) inner join
- 문법
select *
from table_name
inner join table_name2;2) inner join / on
- 문법
select *
from table_name
inner join table_name2
on table_name2.column = talbe_name1.column;- 써보니까 배운 where절 join보다 더 구림.
3) left join
- 문법
select *
from table_name
left join table_name2 // 연결할 table 즉, 더 작은 table
on table_name2.column = talbe_name1.column;- talbe_name1 > table_name2 즉, table_name1의 모든 정보가 다 출력 될 수 있게 함.
- 더 중요한 table을 from 바로 다음에 오게 함.

4) right join
- 문법
select *
from table_name
right join table_name2 //
on table_name2.column = talbe_name1.column;- 이번엔 더 중요한 table을 right join 절 바로 옆에 준다.
- right join의 예시
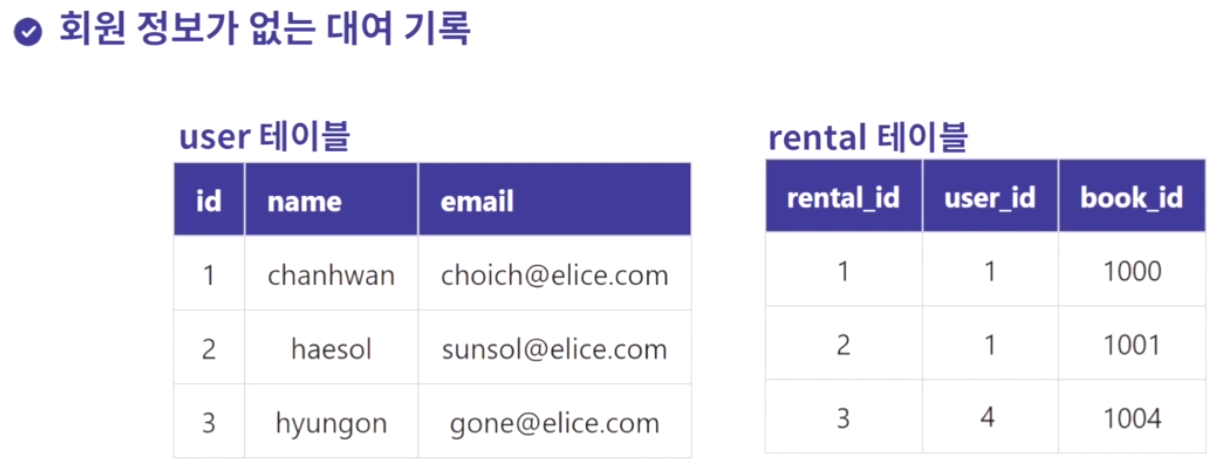

- 주로 left join부터 확인 함

智(지)! 德(덕)! 體(체)!