
sub-query
1. 사용지침
- 서브쿼리는 항상 괄호로 묶습니다.
- 비교조건의 오른쪽에 서브 쿼리를 넣습니다.
- sub-query는 모든절에서 사용이 가능합니다. 하지만!! order by절에서는 사용을 금합니다. 성능이 매우 떨어지기 때문!!
- 서브쿼리 결과값이 단일 행이라면 단일 행 연산자를, 복수 행이라면 다중 행 연산자를 사용합니다.

2. 서브쿼리 사용법
- 내가 뭘 모르는지 찾기.
- 모르는 값을 서브쿼리를 통해 찾기.
- 모르는 값을 어떤 컬럼으로 찾을 지 결정
- 메인 쿼리에서 어떤 컬럼이 받을 지 결정
- 서브 쿼리의 결과에 따라 복수 또는 단일행 연산자 결정
- 문법적으로 서브쿼리의 결과값과 받아주는 메인쿼리의 컬럼의 data type이 반드시 같아야 한다.
3. having 절에서 서브쿼리
- having은 앞서 공부했든 그룹함수가 적용되는 곳이다. 이에 맞춰 서브쿼리의 받는 select절또한 그룹함수로 맞춰줘야한다.
- join 보다는 sub-query가 더 성능이 좋다.
select employee_id, last_name
from employees
where salary = ( // 여기가 in이 아니라 '='인 이유는
select min(avg(salary)) // avg밖에 min으로 인해서 결과값이 1개로 나오기 때문.
from employees
group by department_id4. null 값 반환
- 서브쿼리에서 null값을 반환한다면 no row selected라는 오류를 뿜게 된다.
5. 다중행 서브쿼리
- in : 목록에 있는 임의의 멤버와 동일한지를 확인하는 것 ( '=' 느낌)
- any : if "> all (서브쿼리 절)" 인 경우 최댓값보다 큰 값을 표시
if "< all (서브쿼리 절)" 인 경우 최솟값보다 작은 값을 표시
(max 연산자를 쓰면 되지 않나요? -> 물론 가능은 하지만 any, all이 성능 면에서 더 빠르다) - all : if "> any (서브쿼리 절)" 인 경우 최솟값보다 큰 값을 표시
if "< any (서브쿼리 절)" 인 경우 최댓값보다 작은 값을 표시
6. 2중 서브쿼리 및 서브쿼리의 그룹함수
- 2중 서브쿼리
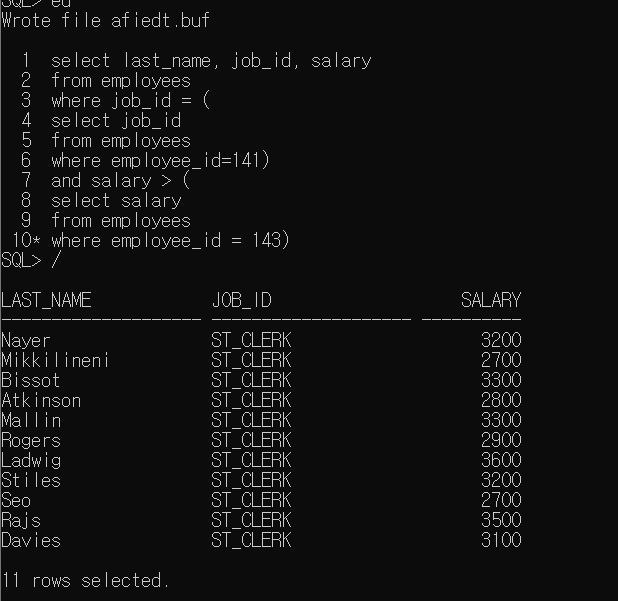
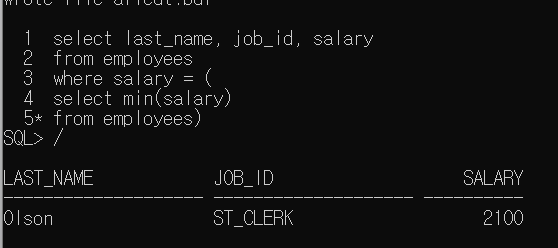
- 서브쿼리에서 그룹함수의 사용

智(지)! 德(덕)! 體(체)!