
G마켓 상품 수집
1. 페이지가 넘어갈 때 카테고리별 상품 수집
1. 시작 페이지의 url get
gmarket_url = "http://corners.gmarket.co.kr/Bestsellers"
driver = wb.Chrome()
driver.get(gmarket_url)2. 각 카테고리 별 페이지 url list에 담기
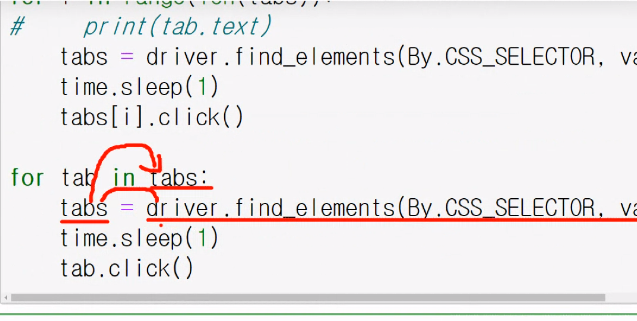
tabs = driver.find_elements(By.CSS_SELECTOR, value="#categoryTabG > :not(li:first-child)")3. 카테고리 별 페이지 전환하는 코드
for i in range(len(tabs)):
# 전에 있던 HTML과 현재 HTML이 다르기 때문에(동적 페이지니까) 계속 새로 loading을 해줘야 한다.
tabs = driver.find_elements(By.CSS_SELECTOR, value="#categoryTabG > :not(li:first-child)")
time.sleep(1)
tabs[i].click()4. 카테고리 별 상품을 담을 배열 생성 후 담기
temlist = []
pricelist = []
itemCatelist = []
# 뒤의 for문 안에 넣기
itemNms = driver.find_elements(By.CLASS_NAME, value="itemname")
itemPrices = driver.find_elements(By.CSS_SELECTOR, value="div.s-price > strong > span > span")
for j in range(len(itemNms)):
itemlist.append(itemNms[j].text)
pricelist.append(itemPrices[j].text)
itemCatelist.append(category)5. 잘 담겼다면 dic으로 만들어 DataFrame화 하기
item_dic = {
"카테고리":itemCatelist,
"상품명":itemlist,
"가격":pricelist
}
item_df = pd.DataFrame(item_dic)
item_df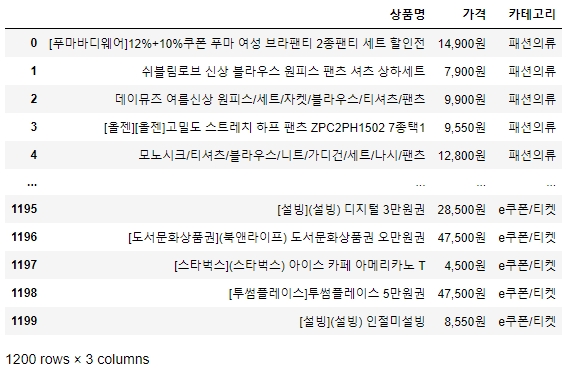
2. error
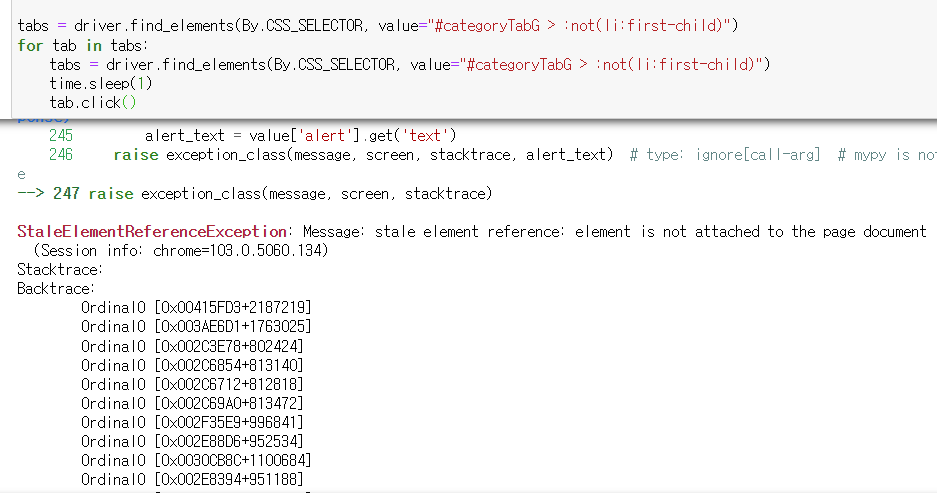
- 드라이버에 들어있는 변수와 현재 페이지와의 드라이버주소가 다르기 때문에 에러가 난다.

유튜브 데이터 수집
1. 필요 library import
from selenium import webdriver as wb
from selenium.webdriver.common.by import By
# 키보드의 값을 가지고 있는 라이브러리
from selenium.webdriver.common.keys import Keys
from tqdm.notebook import tqdm
import pandas as pd
import time 2. 원하는 페이지 로딩
yt_url = "https://www.youtube.com/c/gimongcho/videos"
driver = wb.Chrome()
driver.get(yt_url)3. 원하는 요소 확인
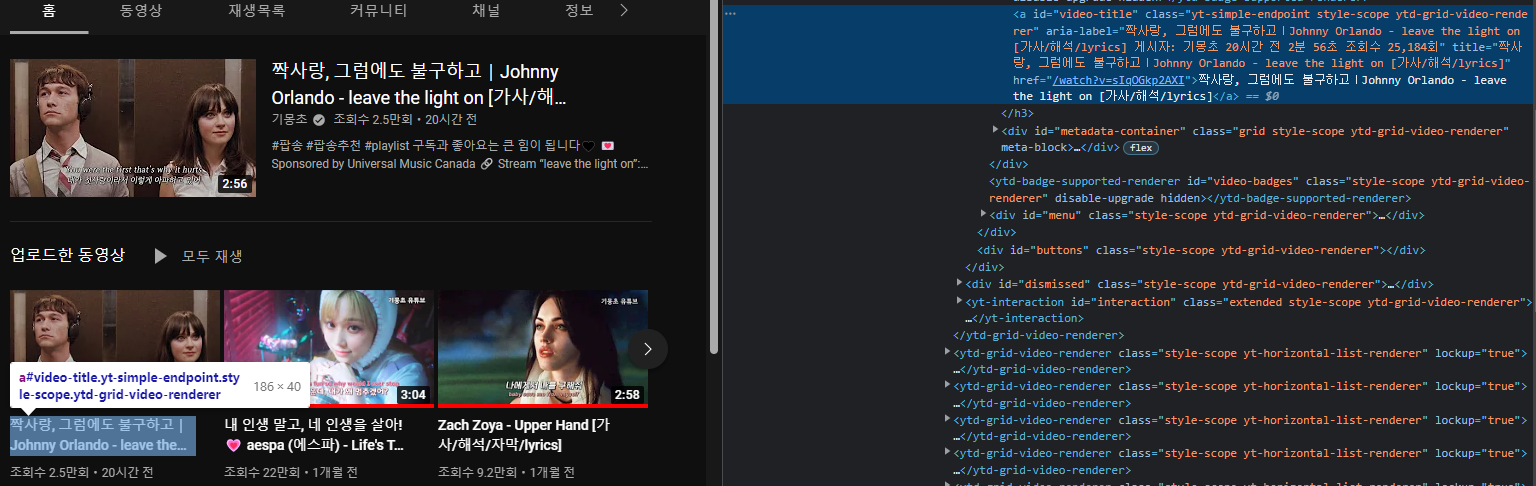
videos = driver.find_elements(By.ID, value="video-title")3-1. 요소 리스트가 잘 들어왔는지 검산
title = videos[0].text
url = videos[0].get_attribute("href")
view = videos[0].get_attribute("aria-label")
start = view.find("조")+4
end = view.rfind("회")
title, url, int(view[start:end].replace(",",""))
4-1. 페이지의 끝을 스크롤
document.body.scrollHeight : 페이지의 끝
last_height = driver.execute_script("return document.body.scrollHeight")
while True:
# 끝까지 스크롤 다운
driver.execute_script("window.scrollTo(0, document.body.scrollHeight);")
time.sleep(1)
# 스크롤 다운 후 스크롤 높이 다시 가져옴
new_height = driver.execute_script("return document.body.scrollHeight")
if new_height == last_height:
break
last_height = new_height4-2. 페이지의 끝을 스크롤
ActionChains 의 move_to_element : 특정 element를 알고 있을 때, 그 위치까지 scroll 하는 것.
# 우선 imoprt가 필수!
from selenium.webdriver import ActionChainssome_tag = driver.find_element_by_id('요소 명')
action = ActionChains(driver)
action.move_to_element(some_tag).perform()5. 배열 생성후 for문 돌며 수집
videos = driver.find_elements(By.ID, value="video-title")
titleList = []
urlList = []
viewList = []
for video in tqdm(videos):
try:
title = video.text
url = video.get_attribute("href")
view = video.get_attribute("aria-label")
start = view.find("조회수")+3
end = view.rfind("회")
titleList.append(title)
urlList.append(url)
viewList.append(view[start:end])
except:
print("수집실패")6. dictionary를 이용하여 DataFrame화
video_dic = {
"제목":titleList,
"주소":urlList,
"조회수":viewList
}
video_df = pd.DataFrame(video_dic)
video_df

智(지)! 德(덕)! 體(체)!