최근 flutter 의 DB 에 관해 알아보는 중 Hive 를 알게 되었다.
그러나 지원을 중단한 듯 보였다.
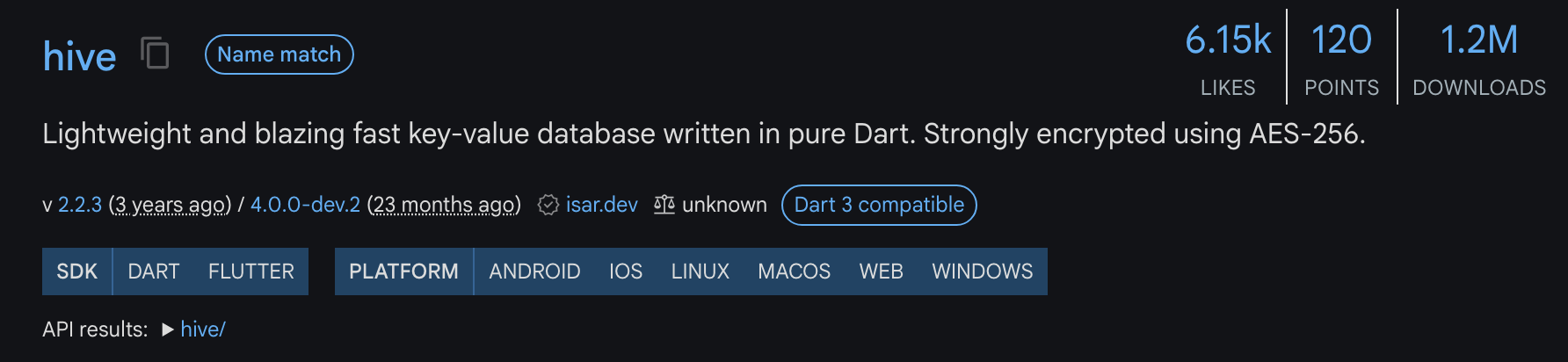
무려 개발중인 버전도 2년 전이 마지막 업데이트다.
이때, 다른 대안이 없을까 서치하다가 완벽한 대안인 Object Box 에 대해 알게되었다.
1. ObjectBox 개념
ObjectBox는 순수 Dart 객체를 그대로 영속화하면서 SQLite 대비 최대 10배 빠른 성능을 제공하는 ACID 준수, 임베디드 NoSQL-DB 이다.
말은 SQL이 필요없지만 JPA 와 결이 비슷하다고 느낀 나로서는 아무래도 오히려 SQL 에 어느정도 지식이 있어야 사용이 용이하겠다고 판단하였다.
또 다른 장점은 필요 시 데이터 동기화·벡터검색까지 확장할 수 있다.
|구분|요약|비고|
|:---:|:---:|:--:|
|데이터 모델| @Entity 클래스로 정의, @Id() 자동증가 기본값 |Null-safety 완전 지원|
|저장소(Store)| Store 객체 1개가 DB 파일과 연동 |openStore() 헬퍼 함수 권장|
|Box| store.box<T>()로 얻는 엔티티 단위 DAO |CRUD·쿼리·트랜잭션 담당|
|쿼리| 타입 안전 QueryBuilder / 플러그식 조건 API| findAsync()로 격리 Isolate 실행 가능|
|관계(Link)| ToOne·ToMany 내장, LAZY 로딩 지원 |양방향은 Backlink 사용|
|반응형| query.watch() 또는 box.watch() → Stream| UI 자동 갱신에 용이|
|코드 생성| build_runner로 objectbox.g.dart 생성| 변경 시마다 재실행 필요|2. define entity
import 'package:objectbox/objectbox.dart';
()
class Person {
()
int id = 0;
String firstName;
String lastName;
Person({required this.firstName, required this.lastName});
}이때, id가 0이면 put() 호출 시 자동 할당
JPA와 동일하게 @Entity()는 클래스, @Id()는 식별자이며, 이 둘은 필수이다.
원시 타입(Int, double, bool, String, DateTime, Uint8List) 및 조인을 위한 ToOne, ToMany 도 지원된다.
3. generate code
flutter pub run build_runner build --delete-conflicting-outputs이제 entity 를 다 작성하였다면 위 명령어를 실행한다.
그러면 objectbox.g.dart, objectbox-model.json이 생성된다.
analyzer 버전 불일치 등으로 78 오류가 나면 objectbox_generator 최신 버전으로 올리거나 캐시를 지운다.
4. init store
import 'objectbox.g.dart'; // 반드시 포함
import 'package:path_provider/path_provider.dart';
import 'package:path/path.dart' as p;
late final Store store;
Future<void> initStore() async {
final dir = await getApplicationSupportDirectory(); // Android는 /files
store = await openStore(directory: p.join(dir.path, 'person_db')); // 권장
}5. CRUD
1. Box 가져오기
final personBox = store.box<Person>();2. Create · Read · Update · Delete
// C
final id = personBox.put(Person(firstName: 'Jane', lastName: 'Doe'));
// R
final jane = personBox.get(id);
// U
jane!.lastName = 'Black';
personBox.put(jane);
// D
personBox.remove(jane.id);put()은 내부 트랜잭션 포함; 대량 삽입은 putMany(list) 사용해 속도 10배 이상 향상
3. QueryBuilder
이 부분이 바로 sql 을 몰라도 된다고 하는데 sql 을 알아야 query 를 작성할 수 있을 것으로 보인다.
물롱 sql 과 nosql 간의 괴리가 있을 수 있겠다.
final query = personBox
.query(Person_.lastName.equals('Black') &
Person_.firstName.startsWith('J'))
.order(Person_.id, flags: Order.descending) // 정렬
.build();
final results = query.find(); // List<Person>
query.close(); // 리소스 해제AND, OR 은 &, | 연산자로 표현한다.
참고로 pagenation 을 위한 오프셋, 제한은 query.offset = 40; query.limit = 20;
4. 비동기 쿼리
final people = await query.findAsync(); // Isolate에서 실행6. Relations
1. ToOne
()
class Order {
int id = 0;
final customer = ToOne<Customer>(); // Target entity
}
()
class Customer {
int id = 0;
String name;
}order.customer.target = customerObj;
box.put(order) 하면 두 객체 모두 저장.
2. ToMany & Backlink
()
class Tag {
int id = 0;
String name;
('tags')
final tasks = ToMany<Task>();
}
()
class Task {
int id = 0;
String title;
final tags = ToMany<Tag>();
}Backlink는 반대편에서 자동으로 역참조 컬렉션 생성.
3. Relation Query
final urgentTasks = taskBox
.query(Task_.tags.contains(Tag_.name, 'urgent'))
.build()
.find();7. 반응형 스트림
ObjectBox는 데이터 변경을 Stream으로 내보내 UI를 실시간으로 업데이트할 수 있다.
final query = personBox.query().build();
final subscription = query.watch(triggerImmediately: true)
.listen((Query<Person> q) {
final list = q.find();
setState(() => persons = list);
});triggerImmediately 옵션으로 초기 데이터 전송.
limit을 사용하려면 query.limit = 10 후 watch() 호출.
subscription.cancel() 시 Query 자동 close.
8. 트랜잭션 및 동시성
store.runInTransaction(TxMode.write, () {
for (final p in persons) personBox.put(p);
});다트 Isolate 전송용 runInTransactionAsync()도 제공해 CPU 탐색 쿼리를 오프로드할 수 있다.
CPU 집약적인 데이터베이스 작업을 메인(UI) 스레드에서 직접 실행하지 않고, 별도의 Isolate(백그라운드 스레드)에서 실행하도록 넘길 수 있다는 의미이다.
작업이 다른 Isolate에서 진행되는 동안, 메인 UI 스레드는 계속해서 사용자 인터페이스를 원활하게 갱신하고 사용자 입력을 처리할 수 있다. 그 후 무거운 작업이 완료되면, 그 결과만 메인 스레드로 다시 전달받게 된다.
9. 마이그레이션(스키마 업데이트)하는 법
엔티티·필드 이름 변경: 원본에 @Id() 값 유지, 새 필드 추가 후 build_runner 재실행하면 자동 마이그레이션.삭제:필드를 주석 처리 후 빌드→앱 배포→코드에서 제거이렇게 귀찮지만 2-step 절차 권장.
바로 삭제하면 ID 재사용 충돌 가능.- 스키마 충돌 오류(예: last index ID 1 is higher than 0)는 모델 JSON·DB 파일 간 불일치로 발생한다.
사전 모델 동기화 후 배포해야 한다.
10. 성능 최적화
| 팁 | 설명 |
|---|---|
| 인덱스 추가 | @Index() 애너테이션으로 검색 속도 향상 |
| 대량 작업 | putMany()·runInTransaction() 사용, 거래당 I/O 최소화 |
| 쿼리 재사용 | Query 인스턴스 캐싱, 필요 시 query.reset()으로 매개변수만 교체 |
| 스트림 최소화 | 동일 박스에 다수 watch를 두면 비용 증가, 가능하면 하나의 Query로 합산 |
| 디렉터리 지정 | 데스크톱·테스트는 고유 path 지정해 파일 충돌·삭제 방지 |
