스프링 데이터 JPA의 트레이드 오프
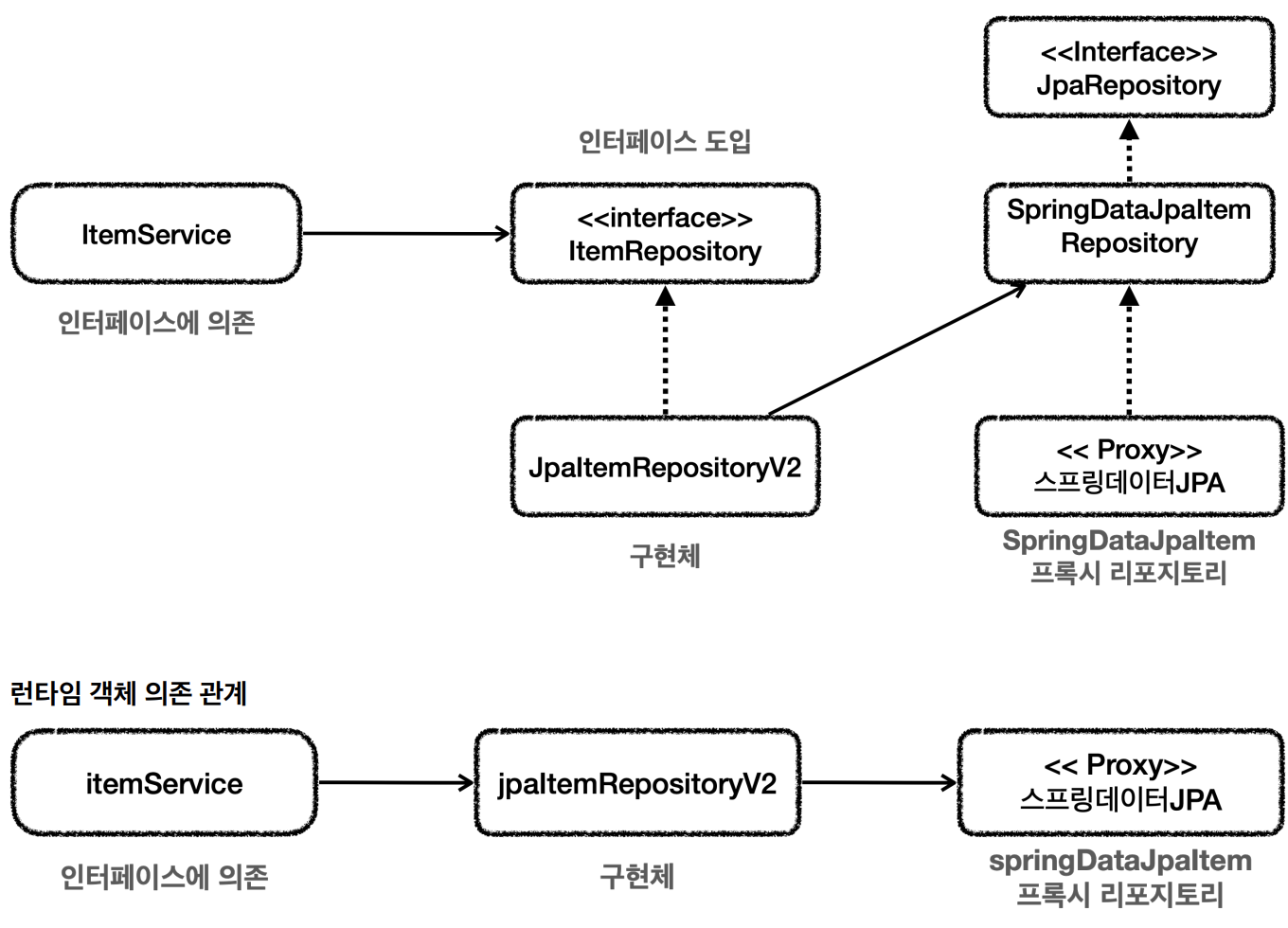
중간에서 JpaItemRepositoryV2 가 어댑터 역할을 해준 덕분에 ItemService 가 사용하는 ItemRepository 인터페이스를 그대로 유지할 수 있고  클라이언트인 ItemService 의 코드를 변경하지 않아도 되는 장점이 있었다.
클라이언트인 ItemService 의 코드를 변경하지 않아도 되는 장점이 있었다.
@Service
@RequiredArgsConstructor
public class ItemServiceV1 implements ItemService {
private final ItemRepository itemRepository;
@Override
public Item save(Item item) {
return itemRepository.save(item);
}
@Override
public void update(Long itemId, ItemUpdateDto updateParam) {
itemRepository.update(itemId, updateParam);
}
@Override
public Optional<Item> findById(Long id) {
return itemRepository.findById(id);
}
@Override
public List<Item> findItems(ItemSearchCond cond) {
return itemRepository.findAll(cond);
}
}(물론 ItemRepository 인터페이스 메서드 명 자체를 JpaRepository 메서드 명과 맞췄기 때문에 가능.)
그런데 여기서 의문점이 생긴다. 왜 서비스 단에서 그냥 SpringDataJpaItemRepository를 바로 쓰지 않을까? 왜 ItemRepository를 한 번 거쳐서 갈까?
이것은 우리가 DI, OCP 에 너무 초점을 맞추다 보니까 이렇게 구조가 복잡하게 된 것이다.
또 실제 이 코드를 구현해야하는 개발자 입장에서 보면 중간에 어댑터도 만들고, 실제 코드까지 만들어야 하는 불편함이 생긴다.
정리하자면 유지보수 관점에서 ItemService 를 변경하지 않고, ItemRepository 의 구현체를 변경할 수 있는 장점이 있다. 그러니까 DI, OCP 원칙을 지킬 수 있다는 좋은 점이 분명히 있다. 하지만 반대로 구조가 복잡해지면서 어댑터 코드와 실제 코드까지 함께 유지보수 해야 하는 어려움도 발생한다.
다만, 개발을 할 때는 항상 자원이 무한한 것이 아니다. 그리고 어설픈 추상화는 오히려 독이 되는 경우도 많다.
무엇보다 추상화도 비용이 든다. 인터페이스도 비용이 든다. 여기서 말하는 비용은 유지보수 관점에서 비용을 뜻한다. 이 추상화 비용을 넘어설 만큼 효과가 있을 때 추상화를 도입하는 것이 실용적이다.
이것이 바로 trade-off 이다.
여기서 고급 개발자 영한쌤은 말씀하신다.
초기 프로젝트 생성에서추상화vs단순 개발은 우선단순 개발을 선택하는 것이 조금 더 좋다고 본다.
단순하면서 빨리 해결할 수 있기 때문이다. 우선 개발을 해놓고 추후 여견이 되면 리팩토링을 통해 그 부분들을 개선해 나간다고 보시는 것이다.
실용적 구조
Spring Data Jpa + Querydsl 조합으로 구조를 작성해보자.
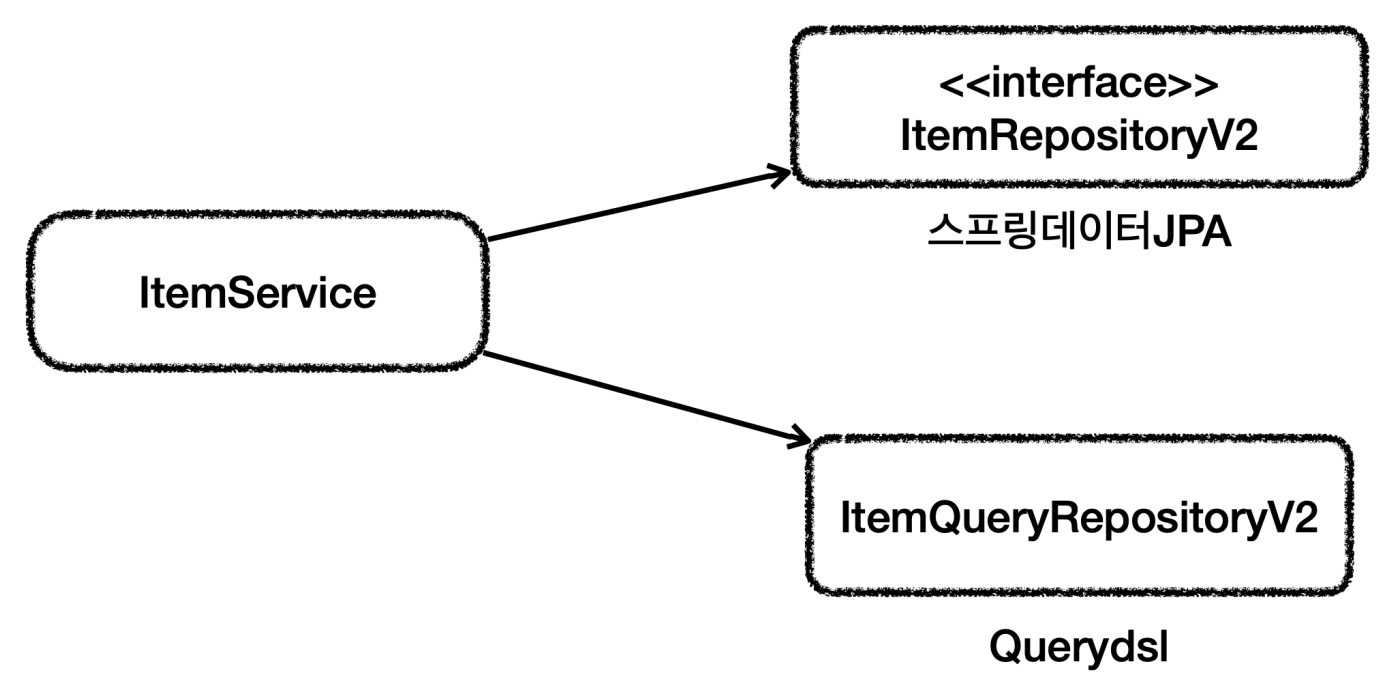
ItemRepositoryV2 는 스프링 데이터 JPA의 기능을 제공하는 리포지토리이다.
ItemQueryRepositoryV2 는 Querydsl을 사용해서 복잡한 쿼리 기능을 제공하는 리포지토리이다.
이렇게 둘을 분리하면 기본 CRUD와 단순 조회는 스프링 데이터 JPA가 담당하고, 복잡한 조회 쿼리는 Querydsl이 담당하게 된다. 물론 ItemService 는 기존 ItemRepository 를 사용할 수 없기 때문에 코드를 변경해야 한다.
ItemRepositoryV2
public interface ItemRepositoryV2 extends JpaRepository<Item, Long> {}spring data jpa를 사용하기 위함.
참고로 JpaRepository 를 상속받으면 spring 차원에서 알아서 Bean으로 등록을 하기 때문에 추후 Config에서 따로 추가하지 않아도 됨.
여기에 추가로 단순한 조회 쿼리들을 추가해도 된다.
ItemQueryRepositoryV2
@Repository
public class ItemQueryRepositoryV2 {
private final JPAQueryFactory query;
public ItemQueryRepositoryV2(EntityManager em) {
this.query = new JPAQueryFactory(em);
}
public List<Item> findAll(ItemSearchCond cond) {
return query.select(item)
.from(item)
.where(
likeItemName(cond.getItemName()),
maxPrice(cond.getMaxPrice())
)
.fetch();
}
private BooleanExpression likeItemName(String itemName) {
if (StringUtils.hasText(itemName)) {
return item.itemName.like("%" + itemName + "%");
}
return null;
}
private BooleanExpression maxPrice(Integer maxPrice) {
if (maxPrice != null) {
return item.price.loe(maxPrice);
}
return null;
}
}복잡한 쿼리나 동적 쿼리를 작성하기 위함.
복잡한 쿼리들은 여기서 관리하면 됨.
ItemServiceV2
@Service
@RequiredArgsConstructor
@Transactional
public class ItemServiceV2 implements ItemService {
private final ItemRepositoryV2 itemRepositoryV2;
private final ItemQueryRepositoryV2 itemQueryRepositoryV2;
@Override
public Item save(Item item) {
return itemRepositoryV2.save(item);
}
@Override
public void update(Long itemId, ItemUpdateDto updateParam) {
// .orElseThrow 는 spring data jpa 에서 제공하는 findById 의 반환값 자체가 optional 이다.
Item findItem = itemRepositoryV2.findById(itemId).orElseThrow();
findItem.setItemName(updateParam.getItemName());
findItem.setPrice(updateParam.getPrice());
findItem.setQuantity(updateParam.getQuantity());
}
@Override
public Optional<Item> findById(Long id) {
return itemRepositoryV2.findById(id);
}
@Override
public List<Item> findItems(ItemSearchCond cond) {
return itemQueryRepositoryV2.findAll(cond);
}
}구조를 단순화 하기 위해 중간에 인터페이스를 삭제 후 spring data jpa 를 직접 물림.
V2Config
@Configuration
@RequiredArgsConstructor
public class V2Config {
private final EntityManager entityManager;
private final ItemRepositoryV2 itemRepositoryV2; // springDataJpa
@Bean
public ItemService itemService() {
return new ItemServiceV2(itemRepositoryV2, itemQueryRepositoryV2());
}
@Bean
public ItemQueryRepositoryV2 itemQueryRepositoryV2() {
return new ItemQueryRepositoryV2(entityManager);
}
// 이전 프로젝트에서 작성한 TestDataInit 을 위한 의존성 주입
@Bean
public ItemRepository itemRepository() {
return new JpaItemRepositoryV3(entityManager);
}
}뭐 사실 그냥 ItemQueryRepositoryV2 도 ComponentScan 하고 끝내버리면 되긴 한다.
다양한 데이터 접근 기술 조합
어떤 데이터 접근 기술을 선택하는 것이 좋을까?
이 부분은 하나의 정답이 있다기 보다는, 비즈니스 상황과, 현재 프로젝트 구성원의 역량에 따라서 결정하는 것이 맞다고 생각한다. JdbcTemplate 이나 MyBatis 같은 기술들은 SQL을 직접 작성해야 하는 단점은 있지만 기술이 단순하기 때문에 SQL에 익숙한 개발자라면 금방 적응할 수 있다.
JPA, 스프링 데이터 JPA, Querydsl 같은 기술들은 개발 생산성을 혁신할 수 있지만, 학습 곡선이 높기 때문에, 이런 부분을 감안해야 한다. 그리고 매우 복잡한 통계 쿼리를 주로 작성하는 경우에는 잘 맞지 않는다.
개인적으로 추천하는 방향은 JPA, 스프링 데이터 JPA, Querydsl을 기본으로 사용하고, 만약 복잡한 쿼리를 써야 하는데, 해결이 잘 안되면 해당 부분에는 JdbcTemplate이나 MyBatis를 함께 사용하는 것이다.
실무에서 95% 정도는 JPA, 스프링 데이터 JPA, Querydsl 등으로 해결하고, 나머지 5%는 SQL을 직접 사용해야 하니 JdbcTemplate이나 MyBatis로 해결한다. 물론 이 비율은 프로젝트 마다 다르다. 아주 복잡한 통계 쿼리를 자주 작성해야 하면 JdbcTemplate이나 MyBatis의 비중이 높아질 수 있다.
트랜잭션 매니저 선택
JPA, 스프링 데이터 JPA, Querydsl은 모두 JPA 기술을 사용하는 것이기 때문에 트랜잭션 매니저로 JpaTransactionManager 를 선택하면 된다. 해당 기술을 사용하면 스프링 부트는 자동으로 JpaTransactionManager 를 스프링 빈에 등록한다.
그런데 JdbcTemplate , MyBatis 와 같은 기술들은 내부에서 JDBC를 직접 사용하기 때문에 DataSourceTransactionManager 를 사용한다.
따라서 JPA와 JdbcTemplate 두 기술을 함께 사용하면 트랜잭션 매니저가 달라진다. 결국 트랜잭션을 하나로 묶을 수 없는 문제가 발생할 수 있다.
그런데 이 부분은 걱정하지 않아도 된다.
JpaTransactionManager의 다양한 지원
JpaTransactionManager 는 놀랍게도 DataSourceTransactionManager 가 제공하는 기능도 대부분 제공한다. JPA라는 기술도 결국 내부에서는 DataSource와 JDBC 커넥션을 사용하기 때문이다. 따라서 JdbcTemplate , MyBatis 와 함께 사용할 수 있다.
결과적으로 JpaTransactionManager 를 하나만 스프링 빈에 등록하면, JPA, JdbcTemplate, MyBatis 모두를 하나의 트랜잭션으로 묶어서 사용할 수 있다. 물론 함께 롤백도 할 수 있다.
주의점
이렇게 JPA와 JdbcTemplate을 함께 사용할 경우 JPA의 "플러시 타이밍"에 주의해야 한다. JPA는 데이터를 변경하면 변경 사항을 즉시 데이터베이스에 반영하지 않는다. 기본적으로 트랜잭션이 커밋되는 시점에 변경 사항을 데이터베이스에 반영한다. 그래서 하나의 트랜잭션 안에서 JPA를 통해 데이터를 변경한 다음에 JdbcTemplate을 호출하는 경우 JdbcTemplate에서는 JPA가 변경한 데이터를 읽기 못하는 문제가 발생한다.
이 문제를 해결하려면 JPA 호출이 끝난 시점에 JPA가 제공하는 플러시라는 기능을 사용해서 JPA의 변경 내역을 데이터베이스에 반영해주어야 한다. 그래야 그 다음에 호출되는 JdbcTemplate에서 JPA가 반영한 데이터를 사용할 수 있다.
