JPA
1.Spring SQL 중심적인 개발의 문제점
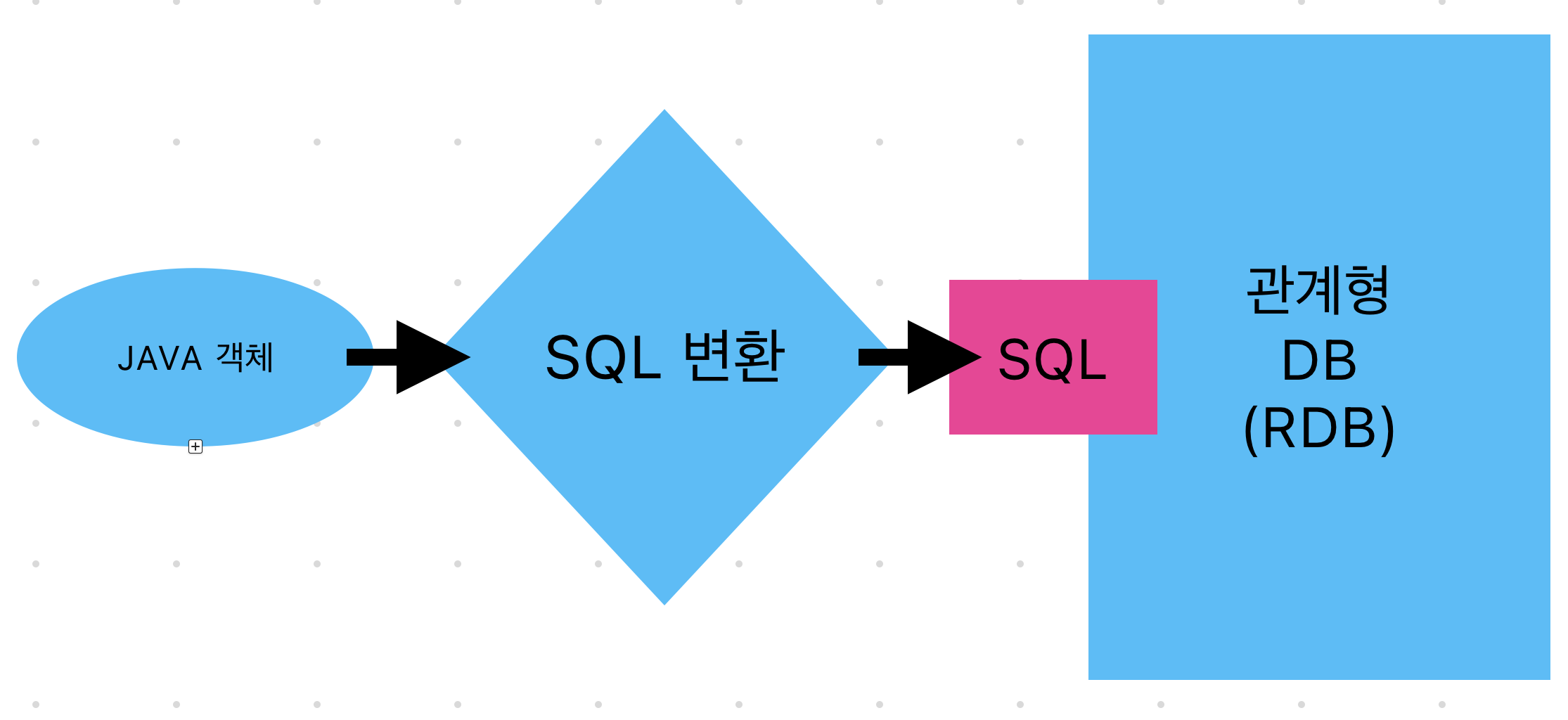
SQL 중심적인 개발의 문제점 우선 우리는 어플리케이션을 개발할 때 보통은 객체지향 언어를 사용한다. 예를들어 JAVA, Scala, Kotlin 등등... 그리고 DB는 보통 관계형 DB를 사용한다. 예를들어 Oracle, MySQL 등등... 그럼 이를 합치면 객
2.Spring JPA, QueryDSL 속성
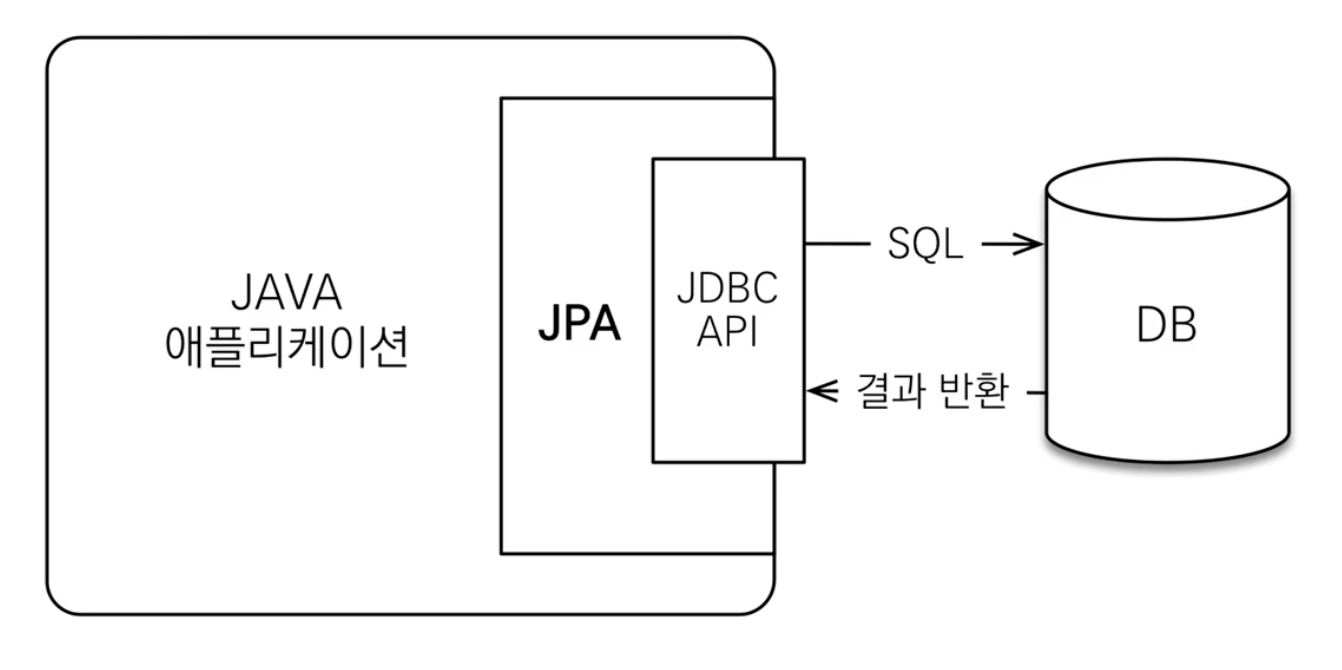
JPA 시작 스프링이 DI 컨테이너를 포함한 애플리케이션 전반의 다양한 기능을 제공한다면, JPA는 ORM 데이터 접근 기술을 제공한다. 대표적으로 JdbcTemplate이나 MyBatis 같은 SQL 매퍼 기술은 SQL을 개발자가 직접 작성해야 하지만, JPA를 사
3.Spring JPA 기본
앞선 포스팅에서 설명했듯 JPA에서 가장 중요한 부분은 객체와 테이블을 매핑하는 것이다. JPA가 제공하는 애노테이션을 사용해서 Item 객체와 테이블을 매핑해보자.@Entity : JPA가 사용하는 객체라는 뜻이다. 이 에노테이션이 있어야 JPA가 인식할 수 있다.
4.JPA 예외 변환
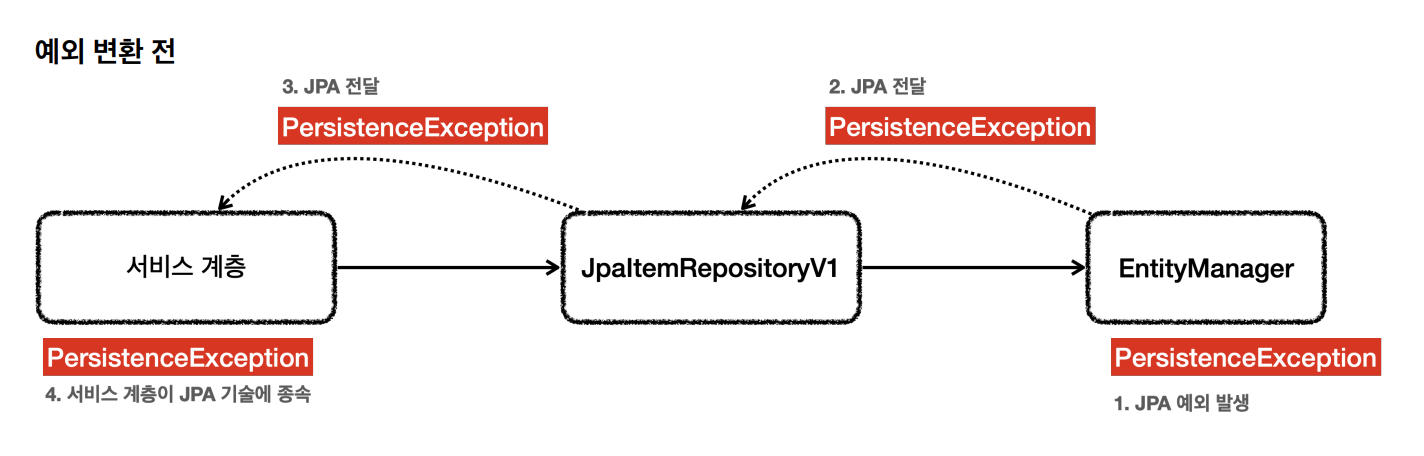
JPA의 경우 예외가 발생하면 JPA예외가 발생하게 된다.EntityManager 는 순수한 JPA 기술이고, 스프링과는 관계가 없다. 따라서 엔티티 매니저는 예외가 발생하면 JPA 관련 예외를 발생시킨다.JPA는 PersistenceException 과 그 하위 예외
5.JPA 스프링 데이터 JPA
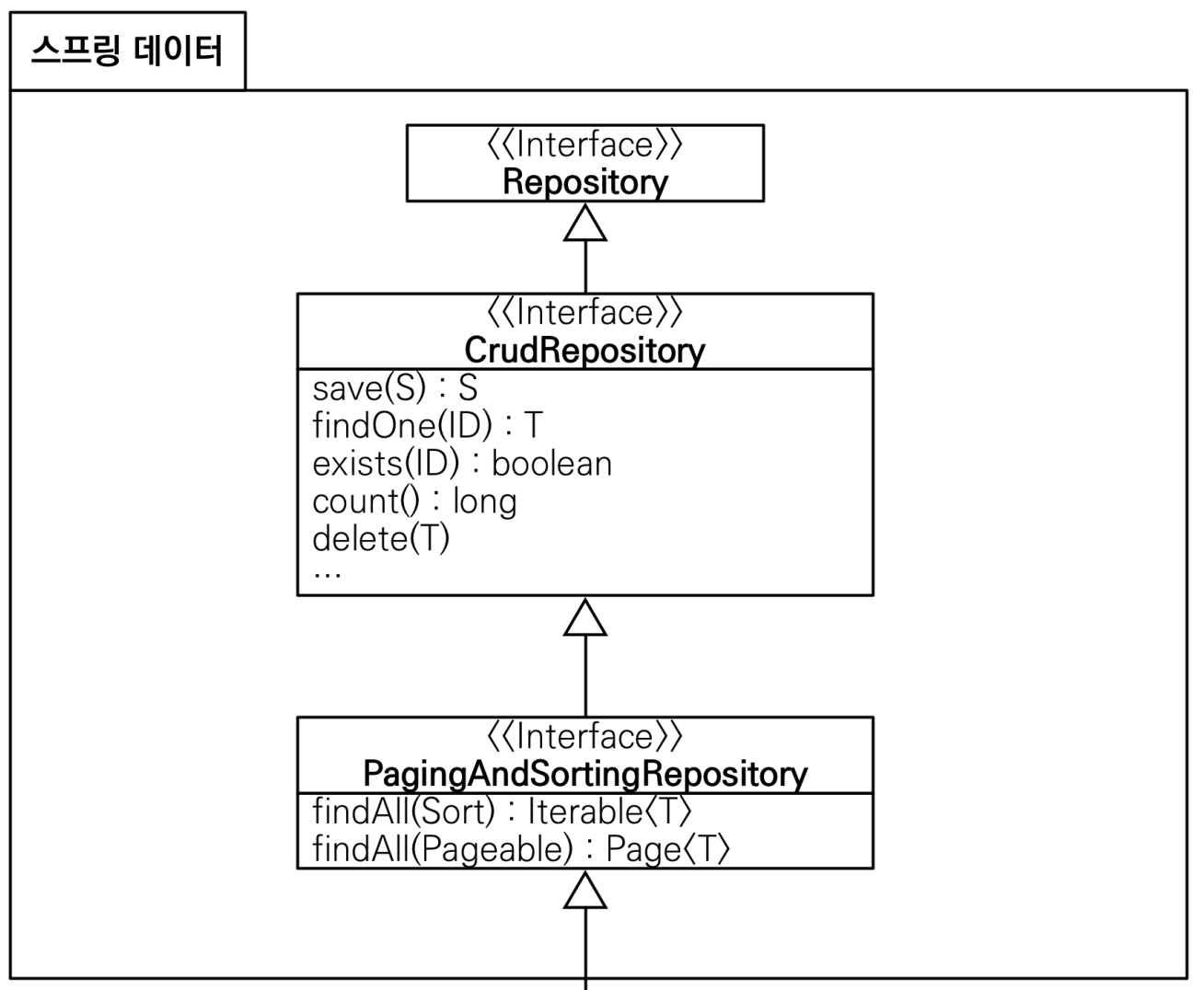
코딩량이 확 준다.도메인 클래스를 중요하게 다룬다.비즈니스 로직 이해가 쉽고 집중하기 좋다.더 많은 테스트 케이스를 작성 가능하다.스프링 데이터 JPA는 JPA를 편리하게 사용할 수 있도록 도와주는 라이브러리이다.수많은 편리한 기능을 제공하지만 가장 대표적인 기능은 다
6.QueryDsl 소개

우리가 백엔드 어플리케이션에서 작성하는 SQL문은 엄연히 문자열이다. 즉, 이는 code assistant가 되지 않는다. 이런걸 type-safe라 한다.이정도면 감이 왔을 텐데 query를 Java로 type-safe하게 작성할 수 있도록 지원하는 프레임웤이 바로
7.JPA 소개
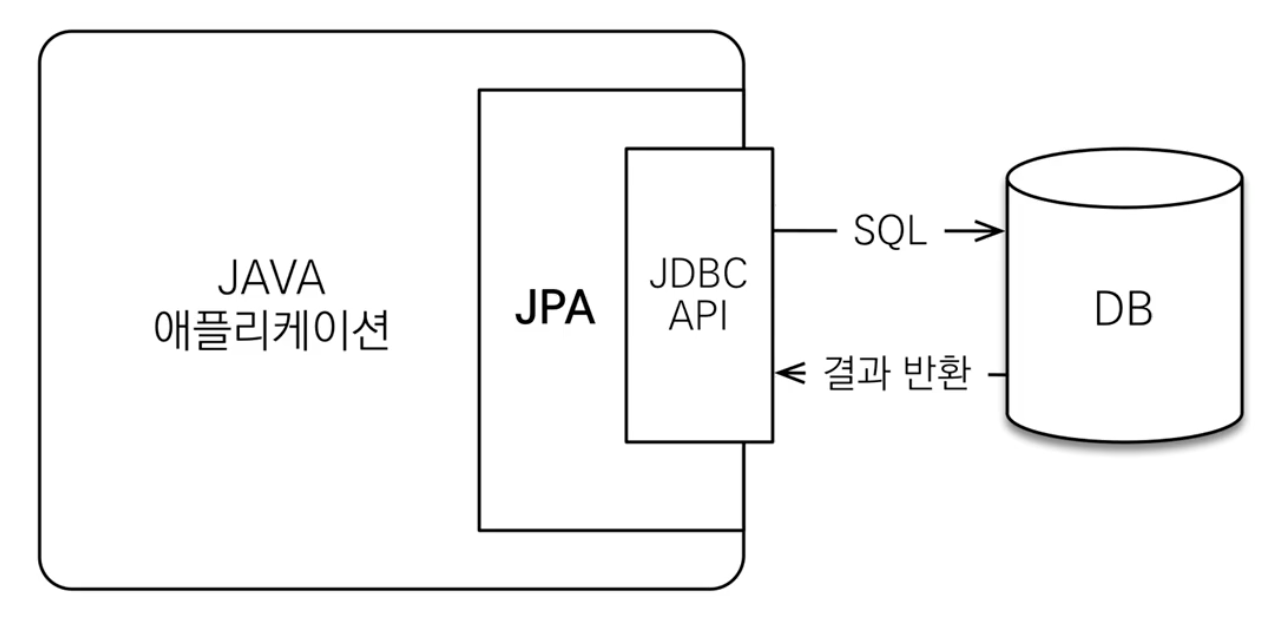
앞서 자세히 설명(https://velog.io/@jeong_woo/Spring-JPA-QueryDSL-%EC%86%8D%EC%84%B11\. 신뢰할 수 있는 엔티티, 계층 (객체 그래프 탐색)2\. 성능 최적화 1\. 1차 캐시와 (동일 트랜잭션 안에서)
8.JPA 영속성 context
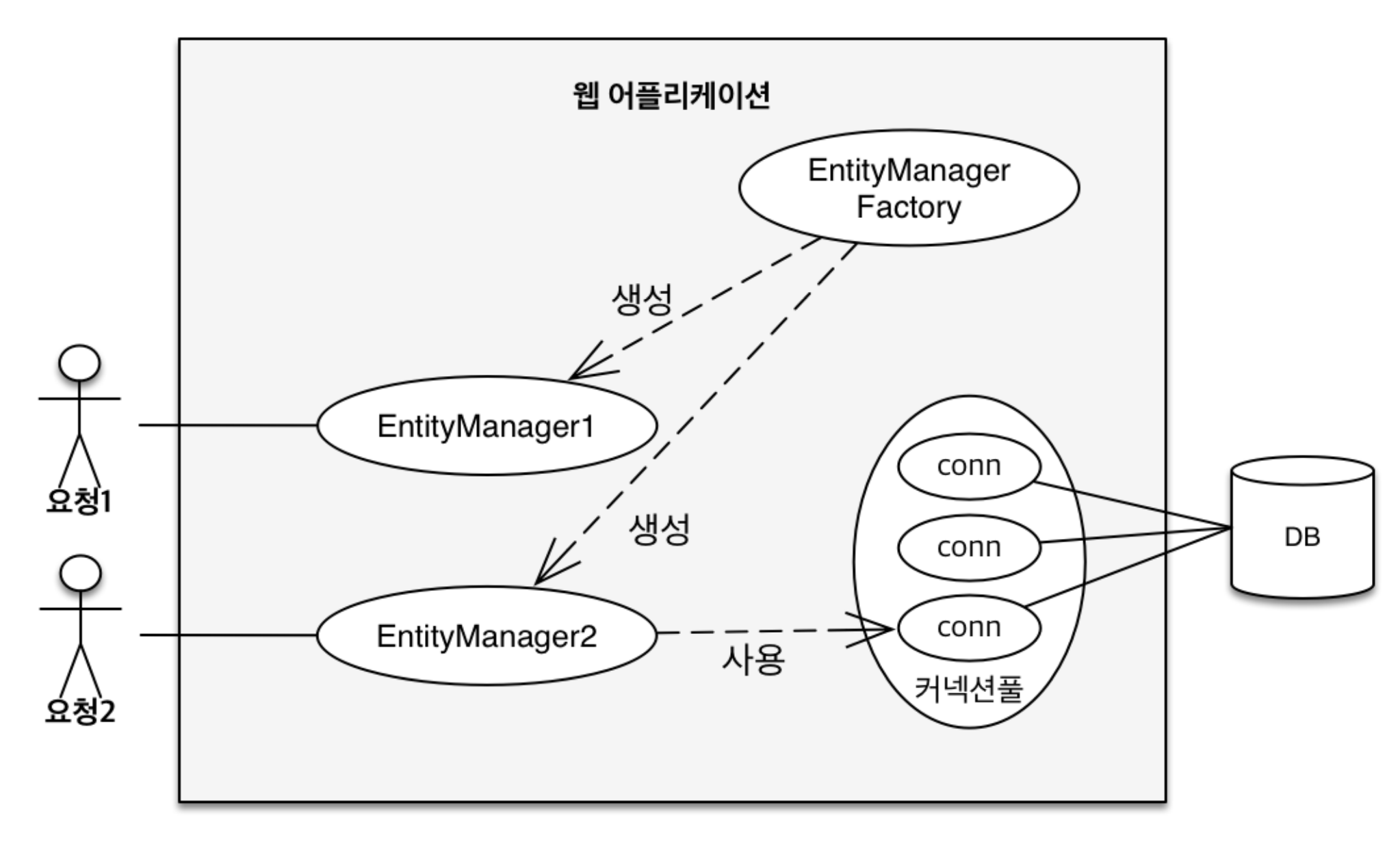
Object Reational Mapping (객체와 관계형 데이터베이스 매핑)영속성 컨텍스트앞서 우리는 JPA가 어떻게 동작을 하는지를 배웠었다."엔티티를 영구 저장하는 환경" 으로 번역해볼 수 있겠다.그럼 아래 코드를 보면 우리는 " 아~ entity 객체를 db에
9.JPA entity mapping
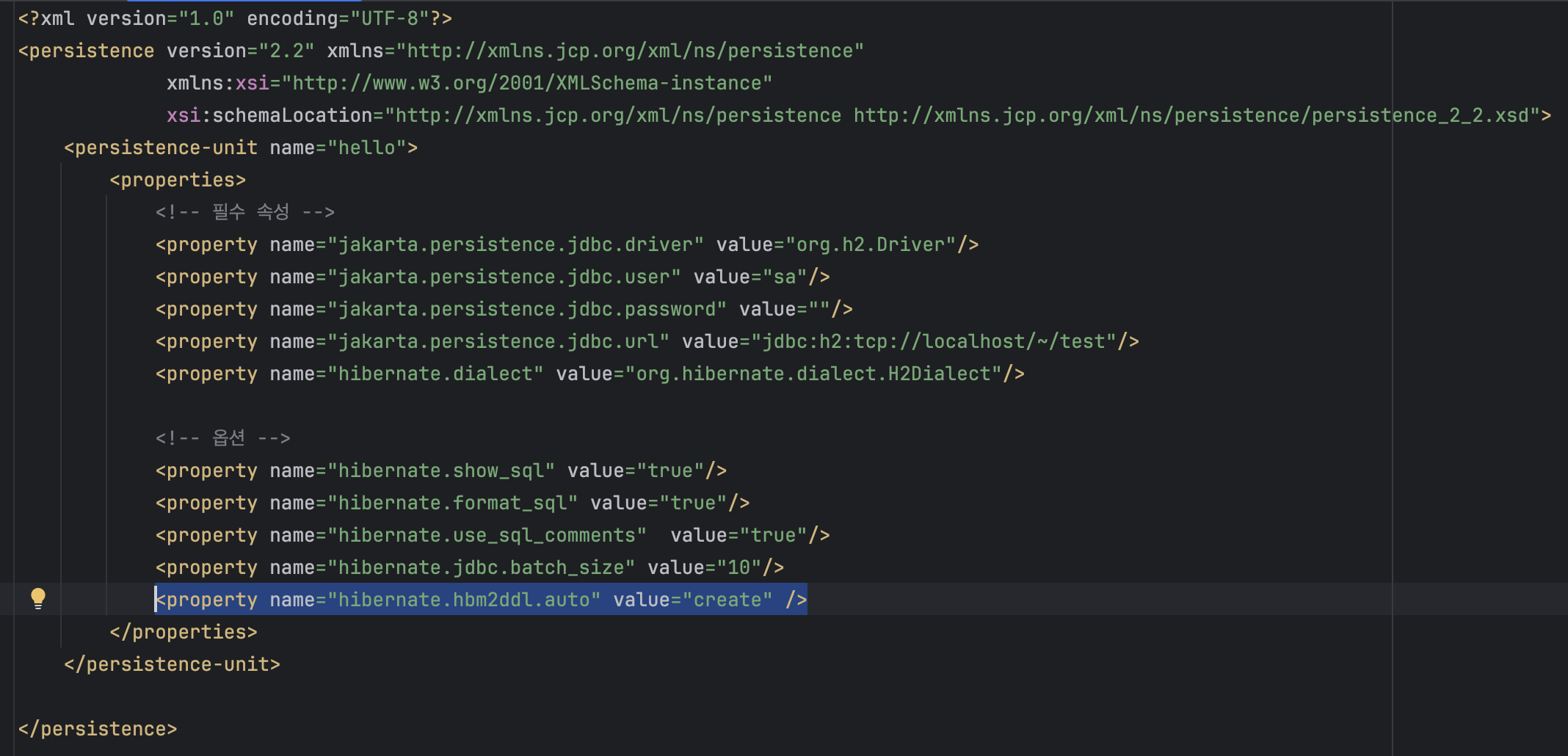
앞서 언급한 JPA에서 가장 중요한 것(https://velog.io/@jeong_woo/JPA-%EC%98%81%EC%86%8D%EC%84%B1-context@Entity가 붙은 클래스는 JPA가 관리, 엔티티라 한다.JPA를 사용해서 테이블과 매핑할 클래스
10.JPA 객체 지향형 연관관계 매핑
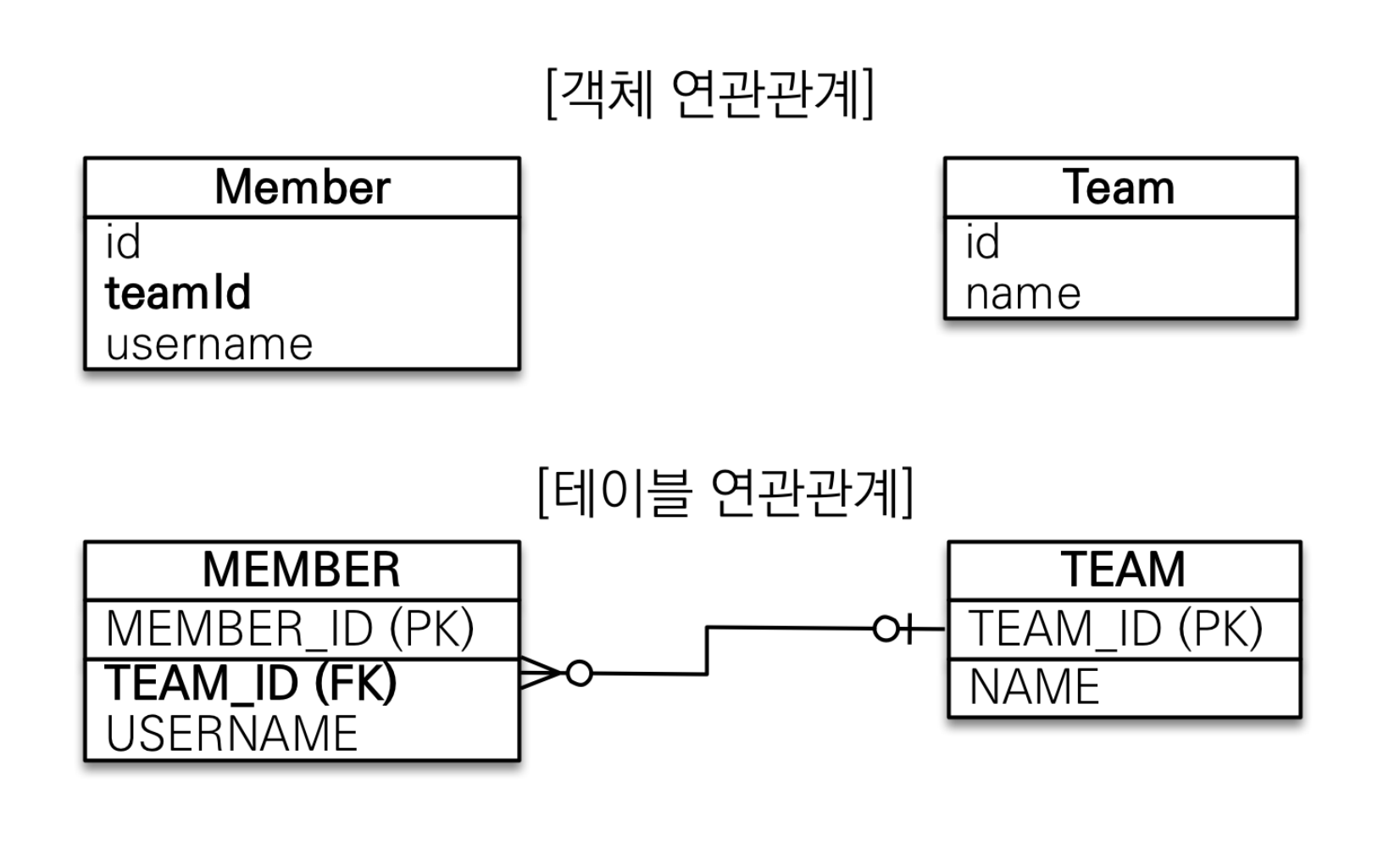
엔티티 설계순서 (데이터 중심 설계) 요구사항 분석 기능 목록 명세화 도메인 모델 분석 1) 회원과 주문의 관계: 회원은 여러 번 주문할 수 있다. (일대다) 2) 주문과 상품의 관계: 주문할 때 여러 상품을 선택할 수 있다. 반대로 같은 상품도 여러 번 주
11.JPA 다양한 연관관계 Mapping
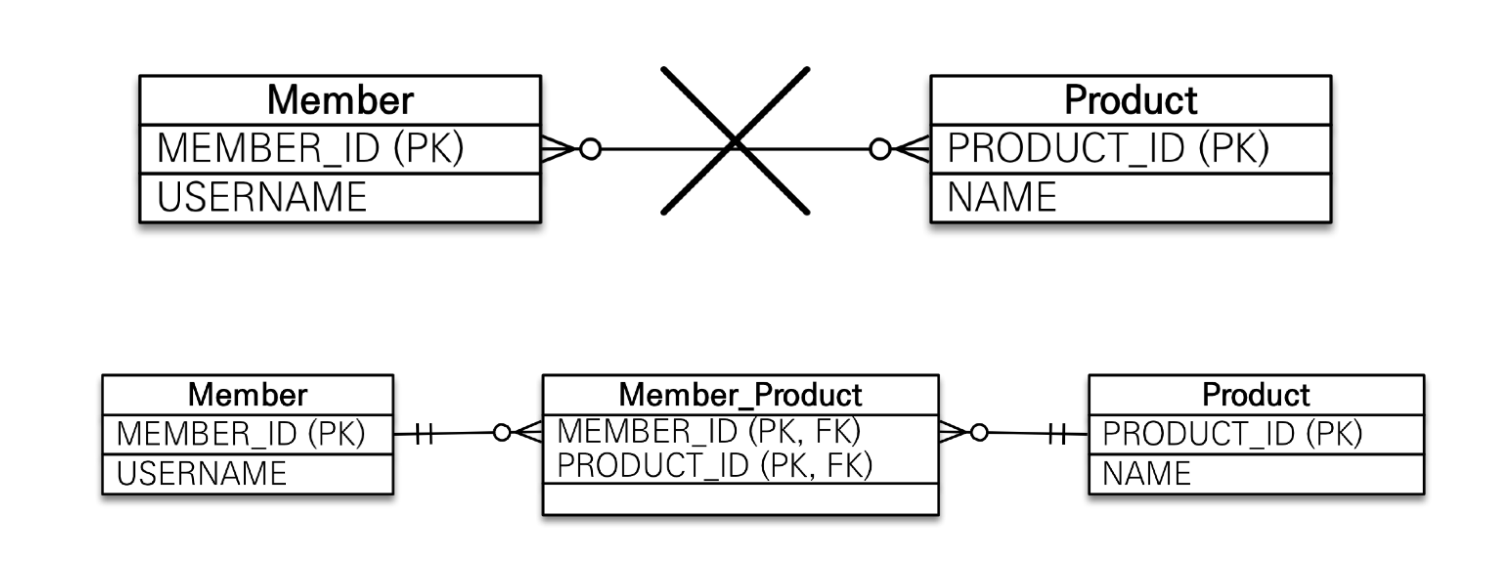
1. 연관관계 매핑시 고려사항 3가지 1) 다중성 일대일: @OneToOne 일대일 다대일(가장 많이 사용): @ManyToOne 일대다 일대다: @OneToMany 다대일 다대다: @ManyToMany 다대다 여기서 다중성은 DB를 기준으로 다중성을 체크해
12.상속관계 매핑, @MappedSuperclass
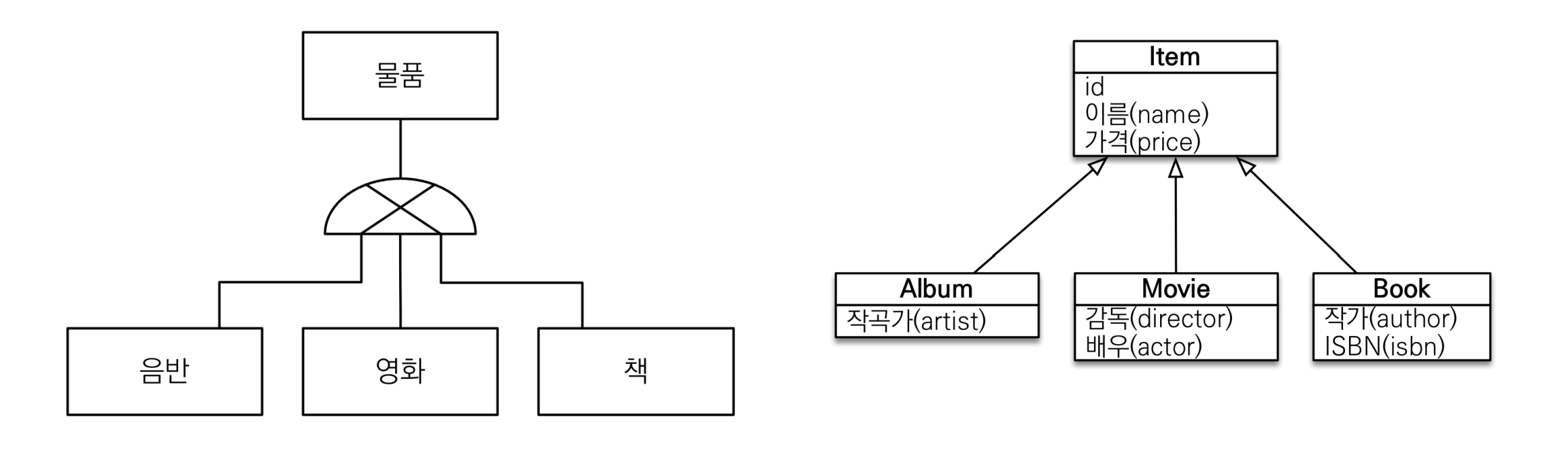
사실 RDB 에는 상속 개념이 없다.다만 슈퍼타입 서브타입 관계라는 모델링 기법이 객체 상속과 유사하다.그래서 정리하면 상속관계 매핑: 객체의 상속과 구조 와 DB에서 슈퍼타입, 서브타입 관계 를 서로 매핑하겠다는 것이다.따라서 앞선 포스팅의 연관관계에서는 DB는 바뀌