URI(Uniform Resource Identifier)
-
리소스를 식별하는 통합된 방법
-
URL, URI, URN 다 들어본 놈 들인데
URI는 URL(Locator) 과 URN(Name) 또는 둘다 추가로 분류될 수 있다.
표준 스펙 찾기 -> 1.1.3
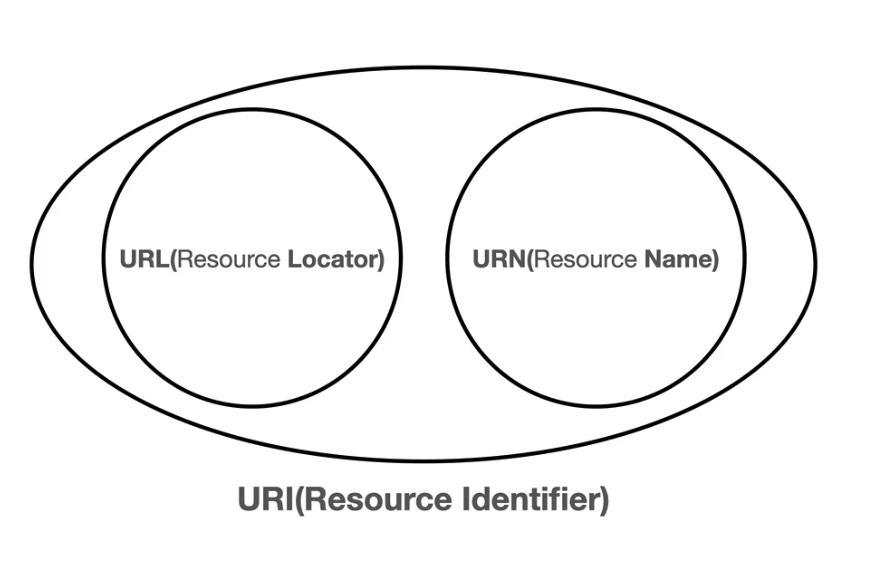
- 대강 정리하자면 리소스의 실제 위치는 URL에 있고 리소스의 이름은 URN이다.
그리고 생긴것은 아래 그림과 같이 생겼다.
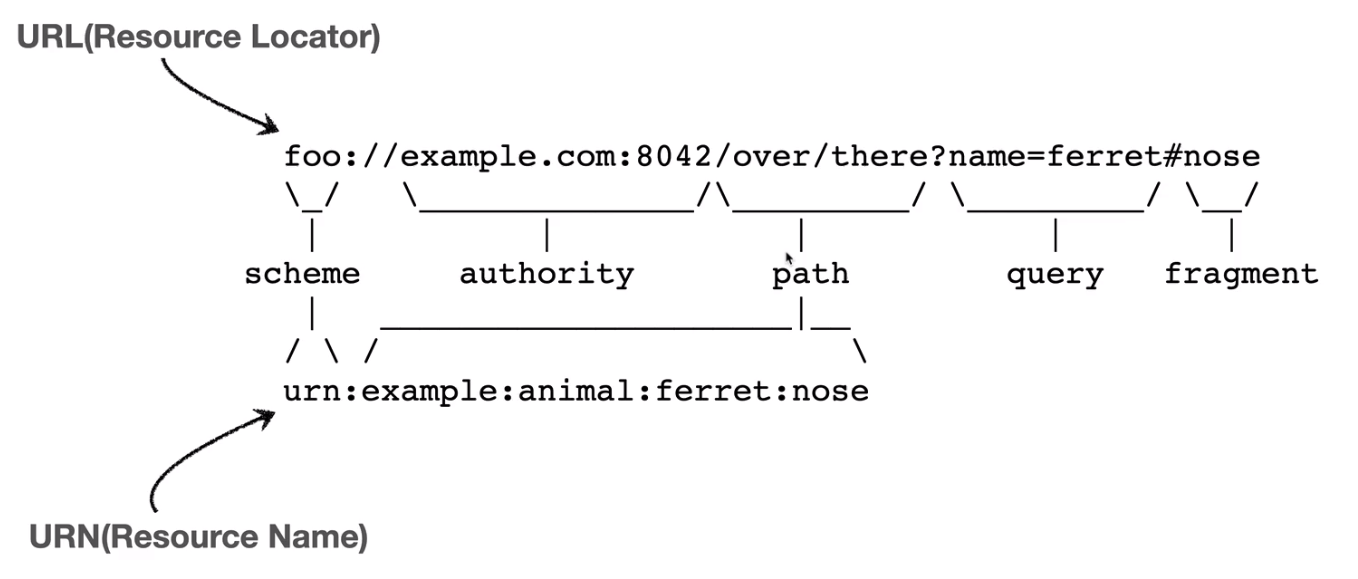
- 그래서 URN은 그냥 정의일 뿐이고 사실 이게 뭘 찾는다 해서 리소스 결과가 맵핑이 되어야하는데 그게 아니기 때문에 URL만 쓴다고 생각하면 된다.
URI 정의
- Uniform: 리소스 식별하는 통일된 방식
- Resource: 자원, URL로 식별할 수 있는 모든 것 (html파일~실시간 교통정보 등 다양한 정보)
- Identifier: 다른 항목과 구분하는데 필요한 정보
URL, URN 정의
- URL-locator: 리소스가 있는 위치를 지정
- URN-namej: 리소스에 이름을 부여
- 위치는 변할 수 있지만 이름은 변하지 않는다.
- urn:isbn:xxxxxxxx
- URN이름만으로 실제 리소스를 찾을 수 있는 방법이 보편화 되지 않음
URL 분석
https://www.google.com/search?q=hello&sourceid=chrome&ie=UTF-8scheme://[userinfo@]host[:port][/path][?query][#fragment]
https://www.google.com:443/search?q=hello&hl=ko
- 프로토콜(https, http, ftp)
- 호스트명(www.google.com)
- 포트번호(443, 80...)
- 경로(/search)
- query parameter | query string(q=hello&hl=ko)
- userinfo는 URL에 사용자 정보를 포함해서 인증하는 건데 거의 사용하지 않는다.
- fragment는 html 내부 북마크 등에 사용된다. 이는 서버에 전송하는 정보는 아니다.
웹 브라우저 요청 흐름
- 클라이언트가 검색창에 뭔가를 친다.
- 웹 브라우저에서 인식하여 URL을 만들어서 DNS에 보낸다.

- DNS는 도메인 네임에 맞는 주소와 포트정보를 찾다.
- 정보를 기반으로 HTTP req message를 생성한다.

- 물론 이것보다 복잡하다. 무튼 HTTP version 정보와 host 정보도 포함되어있다.
- 그리고 HTTP req message를 소켓 라이브리를 통해 OS에다가 tcp/ip 연결(3-way handshaking)을 하고 패킷을 만든 후 데이터를 전달한다.
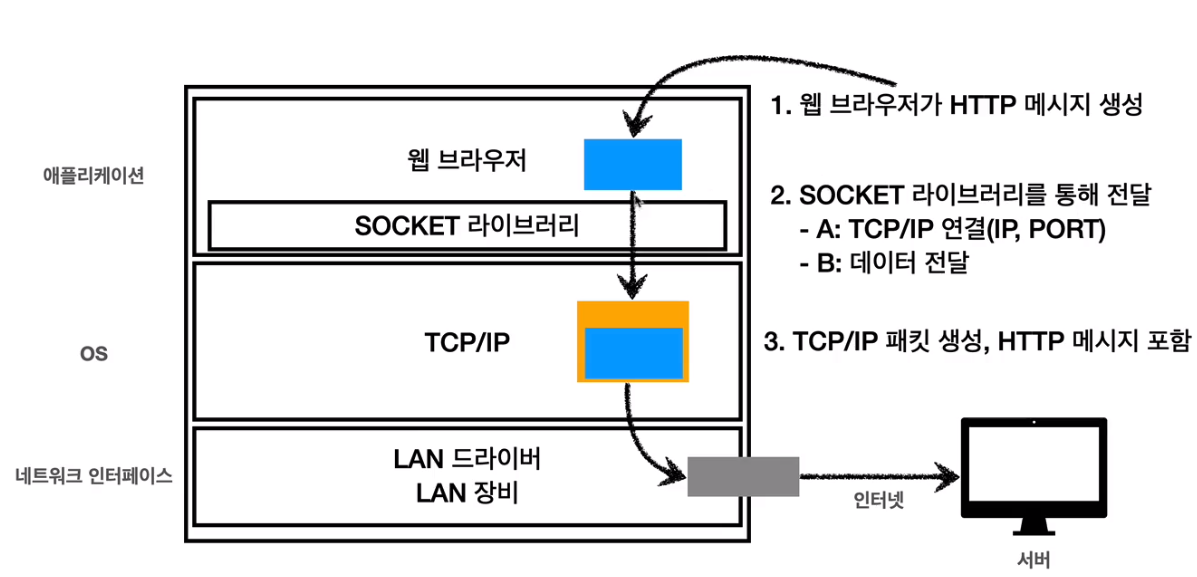
- 저기를 확대해보면 이렇게 생겼는데 저 파란 부분이 전송 데이터(HTTP message)이다.

-
그리고 이제 중간노드들을 거쳐 구글 서버에 도착하면 tcp/ip 패킷을 까서 버리고 http message만 끄집어내서 (파라미터 등을)해석한다.

-
그리고 서버에서 응답 message(패킷)를 아래와 같이 만들고 똑같이 tcp/ip 패킷을 씌운다.

-
그럼 응답받은 우리 브라우저가 HTTP messsage를 까서 해석하고 html 문서를 렌더링하는 것이다.

智(지)! 德(덕)! 體(체)!