백준 2075. N번째 큰 수
문제
N×N의 표에 수 N^2개 채워져 있다. 채워진 수에는 한 가지 특징이 있는데, 모든 수는 자신의 한 칸 위에 있는 수보다 크다는 것이다. N=5일 때의 예를 보자.
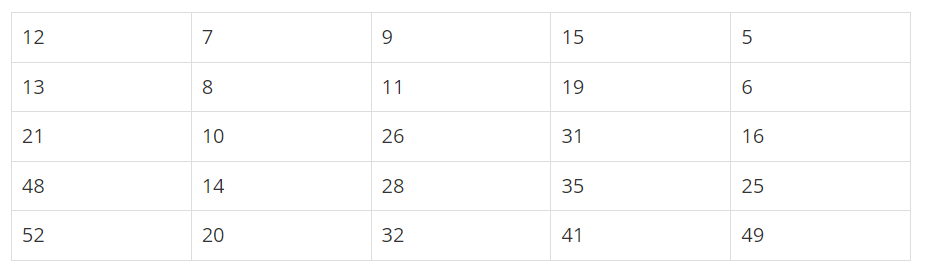
이러한 표가 주어졌을 때, N번째 큰 수를 찾는 프로그램을 작성하시오. 표에 채워진 수는 모두 다르다.
입력
첫째 줄에 N(1 ≤ N ≤ 1,500)이 주어진다. 다음 N개의 줄에는 각 줄마다 N개의 수가 주어진다. 표에 적힌 수는 -10억보다 크거나 같고, 10억보다 작거나 같은 정수이다.
출력
첫째 줄에 N번째 큰 수를 출력한다.
예제 입력 1
5
12 7 9 15 5
13 8 11 19 6
21 10 26 31 16
48 14 28 35 25
52 20 32 41 49
예제 출력 1
35
풀이
입력값을 리스트로 받아와 내림차순 정렬 후 [N-1]번째 인덱스 값을 출력해준다.
코드
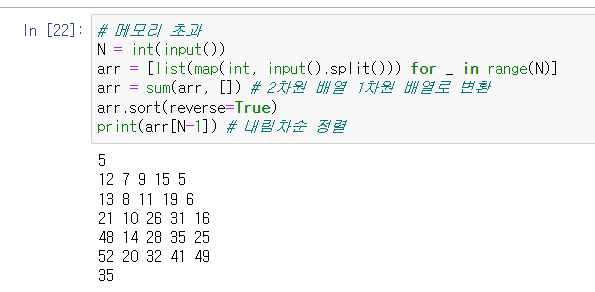
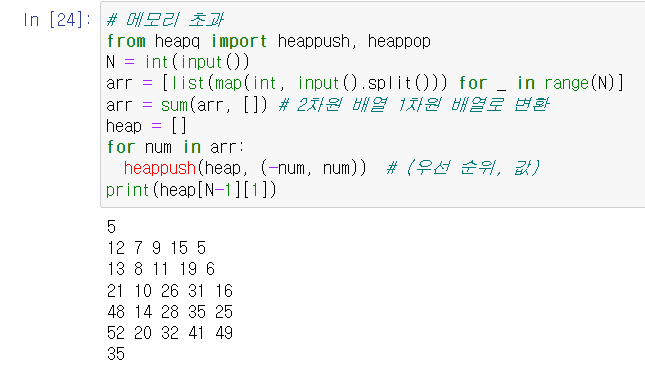
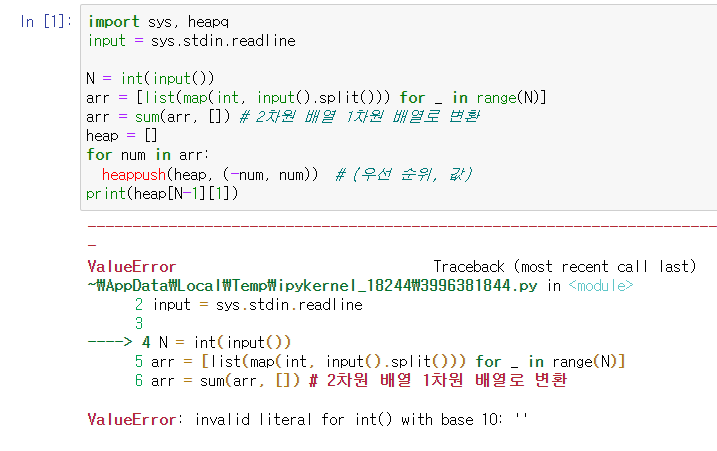
-> 메모리 부족 문제 해결 X
[heap 참고자료] https://www.daleseo.com/python-heapq/
힙 자료구조
heapq 모듈은 이진 트리(binary tree) 기반의 최소 힙(min heap) 자료구조를 제공한다.
min heap을 사용하면 원소들이 항상 정렬된 상태로 추가되고 삭제되며, min heap에서 가장 작은값은 언제나 인덱스 0, 즉, 이진 트리의 루트에 위치한다. 내부적으로 min heap 내의 모든 원소(k)는 항상 자식 원소들(2k+1, 2k+2) 보다 크기가 작거나 같도록 원소가 추가되고 삭제된다.
최소힙에 원소 추가
from heapq import heappush
heappush(heap, 4)
heappush(heap, 1)
heappush(heap, 7)
heappush(heap, 3)
print(heap)최소힙에서 원소 삭제
from heapq import heappop
print(heappop(heap))
print(heap)기존 리스트를 힙으로 변환
from heapq import heapify
heap = [4, 1, 7, 3, 8, 5]
heapify(heap)
print(heap)[응용] 최대 힙
from heapq import heappush, heappop
nums = [4, 1, 7, 3, 8, 5]
heap = []
for num in nums:
heappush(heap, (-num, num)) # (우선 순위, 값)
while heap:
print(heappop(heap)[1]) # index 1[input 메모리 초과 방지1] https://choichumji.tistory.com/64
[input 메모리 초과 방지2] https://velog.io/@yeseolee/Python-%ED%8C%8C%EC%9D%B4%EC%8D%AC-%EC%9E%85%EB%A0%A5-%EC%A0%95%EB%A6%ACsys.stdin.readline
arr = list(map(int,input().split()))
arr.sort()
print(arr)import sys
arr = sys.stdin.readline().restrip()백준 2178. 미로 탐색 - 미해결
문제
N×M크기의 배열로 표현되는 미로가 있다.
1 0 1 1 1 1
1 0 1 0 1 0
1 0 1 0 1 1
1 1 1 0 1 1
미로에서 1은 이동할 수 있는 칸을 나타내고, 0은 이동할 수 없는 칸을 나타낸다. 이러한 미로가 주어졌을 때, (1, 1)에서 출발하여 (N, M)의 위치로 이동할 때 지나야 하는 최소의 칸 수를 구하는 프로그램을 작성하시오. 한 칸에서 다른 칸으로 이동할 때, 서로 인접한 칸으로만 이동할 수 있다.
위의 예에서는 15칸을 지나야 (N, M)의 위치로 이동할 수 있다. 칸을 셀 때에는 시작 위치와 도착 위치도 포함한다.
입력
첫째 줄에 두 정수 N, M(2 ≤ N, M ≤ 100)이 주어진다. 다음 N개의 줄에는 M개의 정수로 미로가 주어진다. 각각의 수들은 붙어서 입력으로 주어진다.
출력
첫째 줄에 지나야 하는 최소의 칸 수를 출력한다. 항상 도착위치로 이동할 수 있는 경우만 입력으로 주어진다.
예제 입력 1
4 6
101111
101010
101011
111011
예제 출력 1
15
예제 입력 2
4 6
110110
110110
111111
111101
예제 출력 2
9
예제 입력 3
2 25
1011101110111011101110111
1110111011101110111011101
예제 출력 3
38
예제 입력 4
7 7
1011111
1110001
1000001
1000001
1000001
1000001
1111111
예제 출력 4
13
[ 풀이 ]
- BFS를 활용하여 전체를 순환하며 최단경로를 찾는 문제이다.
[ 코드 ]

[BFS 참고자료] https://gmlwjd9405.github.io/2018/08/15/algorithm-bfs.html
그래프 탐색이란
하나의 정점으로부터 시작하여 차례대로 모든 정점들을 한 번씩 방문하는 것
https://gmlwjd9405.github.io/2018/08/15/algorithm-bfs.html
너비 우선 탐색(BFS, Breadth-First Search)
너비 우선 탐색이란
루트 노드(혹은 다른 임의의 노드)에서 시작해서 인접한 노드를 먼저 탐색하는 방법
- 시작 정점으로부터 가까운 정점을 먼저 방문하고 멀리 떨어져 있는 정점을 나중에 방문하는 순회 방법이다.
- 즉, 깊게(deep) 탐색하기 전에 넓게(wide) 탐색하는 것이다.
- 사용하는 경우: 두 노드 사이의 최단 경로 혹은 임의의 경로를 찾고 싶을 때 이 방법을 선택한다.
- Ex) 지구상에 존재하는 모든 친구 관계를 그래프로 표현한 후 Ash와 Vanessa 사이에 존재하는 경로를 찾는 경우
- 깊이 우선 탐색의 경우 - 모든 친구 관계를 다 살펴봐야 할지도 모른다.
- 너비 우선 탐색의 경우 - Ash와 가까운 관계부터 탐색
- 너비 우선 탐색(BFS)이 깊이 우선 탐색(DFS)보다 좀 더 복잡하다.
너비 우선 탐색(BFS)의 특징
- 직관적이지 않은 면이 있다.
- BFS는 시작 노드에서 시작해서 거리에 따라 단계별로 탐색한다고 볼 수 있다.
- BFS는 재귀적으로 동작하지 않는다.
- 이 알고리즘을 구현할 때 가장 큰 차이점은, 그래프 탐색의 경우 어떤 노드를 방문했었는지 여부를 반드시 검사 해야 한다는 것이다.
- 이를 검사하지 않을 경우 무한루프에 빠질 위험이 있다.
- BFS는 방문한 노드들을 차례로 저장한 후 꺼낼 수 있는 자료 구조인 큐(Queue)를 사용한다.
- 즉, 선입선출(FIFO) 원칙으로 탐색
- 일반적으로 큐를 이용해서 반복적 형태로 구현하는 것이 가장 잘 동작한다.
- ‘Prim’, ‘Dijkstra’ 알고리즘과 유사하다.
너비 우선 탐색(BFS)의 과정
깊이가 1인 모든 노드를 방문하고 나서 그 다음에는 깊이가 2인 모든 노드를, 그 다음에는 깊이가 3인 모든 노드를 방문하는 식으로 계속 방문하다가 더 이상 방문할 곳이 없으면 탐색을 마친다.
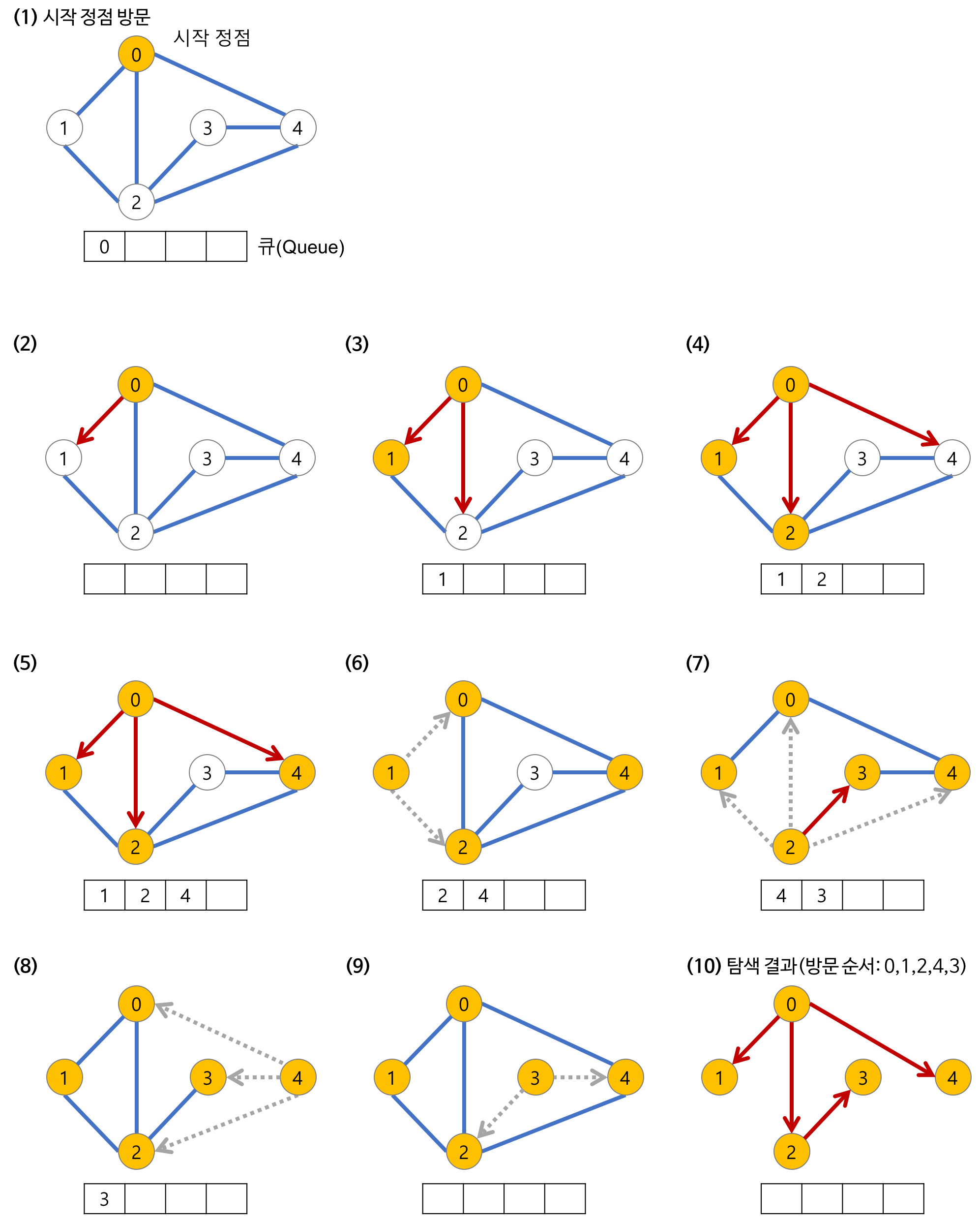
- a 노드(시작 노드)를 방문한다. (방문한 노드 체크)
- 큐에 방문된 노드를 삽입(enqueue)한다.
- 초기 상태의 큐에는 시작 노드만이 저장
- 즉, a 노드의 이웃 노드를 모두 방문한 다음에 이웃의 이웃들을 방문한다.
- 큐에서 꺼낸 노드과 인접한 노드들을 모두 차례로 방문한다.
- 큐에서 꺼낸 노드를 방문한다.
- 큐에서 커낸 노드과 인접한 노드들을 모두 방문한다.
- 인접한 노드가 없다면 큐의 앞에서 노드를 꺼낸다(dequeue).
- 큐에 방문된 노드를 삽입(enqueue)한다.
- 큐가 소진될 때까지 계속한다.
너비 우선 탐색(BFS)의 구현
- 구현 방법
- 자료 구조 큐(Queue)를 이용
- BFS 의사코드(pseudocode)
void search(Node root) {
Queue queue = new Queue();
root.marked = true; // (방문한 노드 체크)
queue.enqueue(root); // 1-1. 큐의 끝에 추가
// 3. 큐가 소진될 때까지 계속한다.
while (!queue.isEmpty()) {
Node r = queue.dequeue(); // 큐의 앞에서 노드 추출
visit(r); // 2-1. 큐에서 추출한 노드 방문
// 2-2. 큐에서 꺼낸 노드와 인접한 노드들을 모두 차례로 방문한다.
foreach (Node n in r.adjacent) {
if (n.marked == false) {
n.marked = true; // (방문한 노드 체크)
queue.enqueue(n); // 2-3. 큐의 끝에 추가
}
}
}
}https://gmlwjd9405.github.io/2018/08/15/algorithm-bfs.html
너비 우선 탐색(BFS)의 시간 복잡도
인접 리스트로 표현된 그래프: O(N+E)
인접 행렬로 표현된 그래프: O(N^2)
깊이 우선 탐색(DFS)과 마찬가지로 그래프 내에 적은 숫자의 간선만을 가지는 희소 그래프(Sparse Graph) 의 경우 인접 행렬보다 인접 리스트를 사용하는 것이 유리하다.
https://gmlwjd9405.github.io/2018/08/15/algorithm-bfs.html
백준 2108. 통계학
문제
수를 처리하는 것은 통계학에서 상당히 중요한 일이다. 통계학에서 N개의 수를 대표하는 기본 통계값에는 다음과 같은 것들이 있다. 단, N은 홀수라고 가정하자.
- 산술평균 : N개의 수들의 합을 N으로 나눈 값
- 중앙값 : N개의 수들을 증가하는 순서로 나열했을 경우 그 중앙에 위치하는 값
- 최빈값 : N개의 수들 중 가장 많이 나타나는 값
- 범위 : N개의 수들 중 최댓값과 최솟값의 차이
N개의 수가 주어졌을 때, 네 가지 기본 통계값을 구하는 프로그램을 작성하시오.
입력
첫째 줄에 수의 개수 N(1 ≤ N ≤ 500,000)이 주어진다. 단, N은 홀수이다. 그 다음 N개의 줄에는 정수들이 주어진다. 입력되는 정수의 절댓값은 4,000을 넘지 않는다.
출력
첫째 줄에는 산술평균을 출력한다. 소수점 이하 첫째 자리에서 반올림한 값을 출력한다.
둘째 줄에는 중앙값을 출력한다.
셋째 줄에는 최빈값을 출력한다. 여러 개 있을 때에는 최빈값 중 두 번째로 작은 값을 출력한다.
넷째 줄에는 범위를 출력한다.
예제 입력 1
5
1
3
8
-2
2
예제 출력 1
2
2
1
10
예제 입력 2
1
4000
예제 출력 2
4000
4000
4000
0
예제 입력 3
5
-1
-2
-3
-1
-2
예제 출력 3
-2
-2
-1
2
예제 입력 4
3
0
0
-1
예제 출력 4
0
0
0
1
(0 + 0 + (-1)) / 3 = -0.333333... 이고 이를 첫째 자리에서 반올림하면 0이다. -0으로 출력하면 안된다.
풀이
- 산술평균
- 중앙값
- 최빈값
- 범위
코드

[counter 모듈 참고]https://www.daleseo.com/python-collections-counter/

백준 16926. 배열 돌리기 1 - 미해결
문제
크기가 N×M인 배열이 있을 때, 배열을 돌려보려고 한다. 배열은 다음과 같이 반시계 방향으로 돌려야 한다.

예를 들어, 아래와 같은 배열을 2번 회전시키면 다음과 같이 변하게 된다.

배열과 정수 R이 주어졌을 때, 배열을 R번 회전시킨 결과를 구해보자.
입력
첫째 줄에 배열의 크기 N, M과 수행해야 하는 회전의 수 R이 주어진다.
둘째 줄부터 N개의 줄에 배열 A의 원소 Aij가 주어진다.
출력
입력으로 주어진 배열을 R번 회전시킨 결과를 출력한다.
제한
- 2 ≤ N, M ≤ 300
- 1 ≤ R ≤ 1,000
- min(N, M) mod 2 = 0
- 1 ≤ Aij ≤ 108
예제 입력 1
4 4 2
1 2 3 4
5 6 7 8
9 10 11 12
13 14 15 16
예제 출력 1
3 4 8 12
2 11 10 16
1 7 6 15
5 9 13 14
예제 입력 2
5 4 7
1 2 3 4
7 8 9 10
13 14 15 16
19 20 21 22
25 26 27 28
예제 출력 2
28 27 26 25
22 9 15 19
16 8 21 13
10 14 20 7
4 3 2 1
예제 입력 3
2 2 3
1 1
1 1
예제 출력 3
1 1
1 1
풀이
- 구현문제
- key 변수를 만들고 처음 시작할 때 값을 넣어준 뒤, 배열을 돌리다 보면 비어있는 배열이 생기는데 그때 temp 변수 안에 저장해두었던 값을 빈 배열에 넣어주면 된다.
- n과 m중 작은 값은 2로 나눠준 값 만큼 for문을 돌려 가장자리부터 안에 있는 배열까지 돌려주는 방식을 사용한다.
코드

백준 1913. 달팽이 - 미해결
문제
홀수인 자연수 N이 주어지면, 다음과 같이 1부터 N2까지의 자연수를 달팽이 모양으로 N×N의 표에 채울 수 있다.
9 2 3
8 1 4
7 6 5
25 10 11 12 13
24 9 2 3 14
23 8 1 4 15
22 7 6 5 16
21 20 19 18 17
N이 주어졌을 때, 이러한 표를 출력하는 프로그램을 작성하시오. 또한 N2 이하의 자연수가 하나 주어졌을 때, 그 좌표도 함께 출력하시오. 예를 들어 N=5인 경우 6의 좌표는 (4,3)이다.
입력
첫째 줄에 홀수인 자연수 N(3 ≤ N ≤ 999)이 주어진다. 둘째 줄에는 위치를 찾고자 하는 N2 이하의 자연수가 하나 주어진다.
출력
N개의 줄에 걸쳐 표를 출력한다. 각 줄에 N개의 자연수를 한 칸씩 띄어서 출력하면 되며, 자릿수를 맞출 필요가 없다. N+1번째 줄에는 입력받은 자연수의 좌표를 나타내는 두 정수를 한 칸 띄어서 출력한다.
예제 입력 1
7
35
예제 출력 1
49 26 27 28 29 30 31
48 25 10 11 12 13 32
47 24 9 2 3 14 33
46 23 8 1 4 15 34
45 22 7 6 5 16 35
44 21 20 19 18 17 36
43 42 41 40 39 38 37
5 7
풀이
- 구현문제이다.
코드
백준 14719. 빗물
문제
2차원 세계에 블록이 쌓여있다. 비가 오면 블록 사이에 빗물이 고인다.image.png
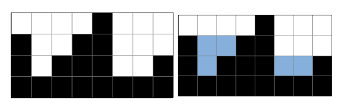
비는 충분히 많이 온다. 고이는 빗물의 총량은 얼마일까?
입력
첫 번째 줄에는 2차원 세계의 세로 길이 H과 2차원 세계의 가로 길이 W가 주어진다. (1 ≤ H, W ≤ 500)
두 번째 줄에는 블록이 쌓인 높이를 의미하는 0이상 H이하의 정수가 2차원 세계의 맨 왼쪽 위치부터 차례대로 W개 주어진다.
따라서 블록 내부의 빈 공간이 생길 수 없다. 또 2차원 세계의 바닥은 항상 막혀있다고 가정하여도 좋다.
출력
2차원 세계에서는 한 칸의 용량은 1이다. 고이는 빗물의 총량을 출력하여라.
빗물이 전혀 고이지 않을 경우 0을 출력하여라.
예제 입력 1
4 4
3 0 1 4
예제 출력 1
5
예제 입력 2
4 8
3 1 2 3 4 1 1 2
예제 출력 2
5
예제 입력 3
3 5
0 0 0 2 0
예제 출력 3
0
힌트
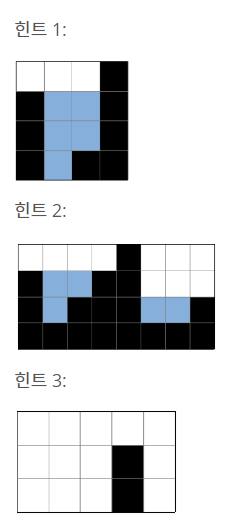
풀이
- 구현문제이다.
- 물이 고이기 위해서는 양 옆에 자신보다 높은 블록이 존재해야 한다.
- 각 블록을 순회하며 블록기준 양옆의 가장 높은 블록을 구하고 그에 따라 고이는 물의 양을 구한다.
코드

