최신 버전 oracle23 깔고 virtual box 깔면 맥북 m1,m2에서도 편하게 oracle 사용이 가능하다.
요약하기
- DML / DCL / DDL
- select / from / where / group by / having / order by
13. 시퀀스와 인덱스
- 시퀀스로 입력한 번호는 아무리 중간에 값이 빠져있어도 수정하지 않는 것이 옳다.
13.1 시퀀스 개념 이해와 시퀀스 생성
1️⃣ START WITH
시퀀스 번호의 시작 값을 지정할 때 사용된다. 1부터 시작되는 시퀀스를 생성하려면 START WITH 1이라고 기술하면 된다.
2️⃣ INCREMENT BY
연속적인 시퀀스 번호의 증가치를 지정할 때 사용된다. 만일 1씩 증가하는 시퀀스를 생성하려면 INCREMENT BU 1이라고 기술하면 된다.
3️⃣ MAXVALUE n | NOMAXVALUE
MAXVALUE는 시퀀스가 가질 수 있는 최대값을 지정한다. 만일 NOMAXVALUE를 지정하게 되면 ASCENDING 순서일 경우에는 10^27승이고, DESCENDING 순서일 경우에는 -1로 설정됩니다.
4️⃣ MINVALUE n | NOMINVALUE
MINVALUE는 시퀀스가 가질 수 있는 최소값을 지정한다. 만일 NOMINVALUE을 지정하게 되면 ASCENDING 순서일 경우에는 1이고, DESCENDIGN 순서일 경우에는 10^26승으로 설정됩니다.
5️⃣ CYCLE | NOCYCLE
CYCLE은 지정된 시퀀스 값이 최대값까지 증가가 완료되게 되면 다시 START WITH 옵션에 지정한 시작 값에서 다시 시퀀스를 시작하도록 한다. NOCYCLE은 증가가 완료되게 되면 에러를 유발시킨다.
6️⃣ CACHE n | NOCACHE
CACHE는 메모리상의 시퀀스 값을 관리하도록 하는 것인데 기본 값은 20이다. NOCA-CHE는 원칙적으로 메모리 상에서 시퀀스를 관리하지 않는다.
13.1.1 시퀀스 관련 데이터 딕셔너리
-- 시퀀스 객체 생성하기
create sequence dept_deptno_seq
start with 10
increment by 10;
-- user_sequences의 테이블 구조 살피기
desc user_sequences;
-- 시퀀스 객체 정보 살피기
select sequence_name, min_value, max_value, increment_by, cycle_flag
from user_sequences;13.1.2 CURRVAL, NEXTVAL
CURRVAL, NEXTVAL 사용하기
-- 시퀀스 객체로부터 새로운 값 생성하기
select dept_deptno_seq.nextval from dual;
-- 시퀀스 객체로부터 현재 값 알아내기
select dept_deptno_seq.currval from dual;
-- 시퀀스 객체로부터 새로운 값 생성하기
select dept_deptno_seq.nextval from dual;시퀀스 사용 시 주의할 점
-- 시퀀스 객체 생성하기
create sequence sample_seq;
-- 시퀀스 객체로부터 현재 값 알아내기
select sample_seq.currval from dual;
-- 시퀀스 객체로부터 새로운 값 생성하기
select sample_seq.nextval from dual;
-- 시퀀스 객체로부터 현재 값 알아내기
select sample_seq.currval from dual;13.2 시퀀스 실무에 적용하기
-- 사원 번호를 자동으로 부여하기 위한 시퀀스 객체 생성하기
create sequence emp_seq
start with 1
increment by 1
maxvalue 100000;
-- 사원 정보 추가하기
insert into emp01
values(emp_seq.nextval, '홍길동', SYSDATE);시퀀스를 테이블의 기본 키에 접목하기
-- 사원 번호를 자동으로 부여하기 위한 시퀀스 객체 생성하기
create sequence emp_seq
start with 1
increment by 1
maxvalue 100000;
-- 사원 테이블 제거하기
drop table emp01;
-- 사원 테이블 생성하기
create table emp01(
empno number(4) primary key,
ename varchar(10),
hiredate date
);
-- 제약 조건 확인하기
select constraint_name, constraint_type, table_name
from user_constraints
where table_name in('EMP01');
-- 제약 조건이 부여된 컬럼 확인하기
select constraint_name, column_name, table_name
from user_cons_columns
where table_name in ('EMP01');
-- 사원 정보 추가하기
insert into emp01
values(emp_seq.nextval, '홍길동', SYSDATE);
insert into emp01
values(emp_seq.nextval, '강감찬', SYSDATE);
-- 사원 정보 조회하기
select * froom emp01;13.3 시퀀스 제거하고 수정하기
시퀀스 제거하기
-- 시퀀스 객체 정보 살피기
select sequence_name, min_value, max_value, increment_by, cycle_flag
from user_sequences;
-- 시퀀스 객체 제거하기
drop sequence dept_deptno_seq;
-- 시퀀스 객체 정보 살피기
select sequence_name, min_value, max_value, increment_by, cycle_flag
from user_sequences;13.4 인덱스의 개요
-- user_ind_dolumns 데이터 딕셔너리로 인덱스 확인하기
select index_name, table_name, columns_name
from user_ind_columns
where table_name in('EMP', 'DEPT');
-- 사원 테이블 제거하기
drop table emp01;
-- 사원 테이블 생성하기
create table emp01
as
select * from emp;
-- user_ind_columns 데이터 딕셔너리로 인덱스 확인하기
select table_name, index_name, column_name
from user_ind_columns
where table_name in ('EMP', 'EMP01');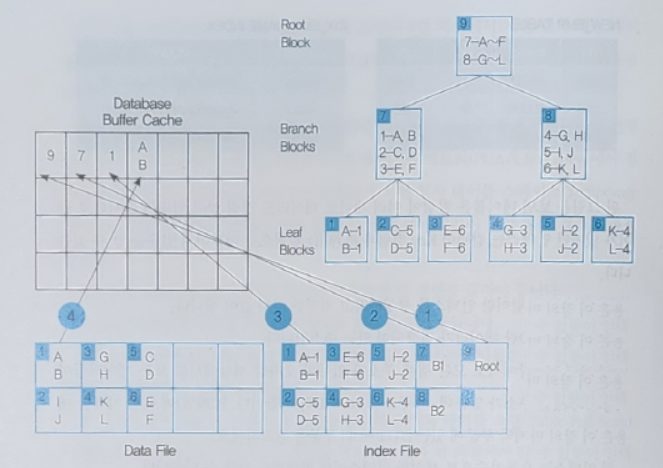
13.5 인덱스의 종류 살피기
13.5.1 고유 | 비고유 인덱스
create unique index index_name
on table_name (column_name);고유 인덱스와 비고유 인덱스 정의하기
-- 부서 테이블 제거하기
drop table dept01;
-- 빈 부서 테이블 생성하기
create table dept01
as
select * from dept where 1=0;
-- 부서 테이블에 데이터 추가하기
insert into dept01 values(10, '인사과', '서울');
insert into dept01 values(20, '총무과', '대전');
insert into dept01 values(30, '교육팀', '대전');
-- 부서 테이블에 데이터 조회하기
select * from dept01;
-- 고유 인덱스 지정하기
create UNIQUE index IDX_DEPT01_DEPNO
on dept01(deptno);
-- 이미 존재하는 고유 인덱스를 생성할 경우 오류가 발생하는 예
create UNIQUE index IDX_DEPT01_LOC
on dept01(loc);
-- 비고유 인덱스 생성하기
create index IDX_DEPT01_LOG
on dept01(loc);13.5.2 결합 인덱스
-- 결합 인덱스 생성하기
create index idx_dept01_com
on dept01(deptno, dname);
-- user_ind_coluns 테이블로 인덱스가 지정된 컬럼 확인하기
select index_name, column_name
from user_ind_columns
where table_name in('dept01');13.5.3 함수 기반 인덱스
-- 함수 기반 인덱스 생성하기
create index idx_emp01_annsal
on emp01(sal*12);
-- user_ind_columns 테이블로 인덱스가 지정된 컬럼 확인하기
select index_name, column_name
from user_ind_columns
where table_name in('emp01');14. 사용자 권한
14.1 사용자 관리
create user tester2
identified by 1234;
grant connect, resource to tester2;
14.2 데이터베이스 보안을 위한 권한
14.2.1 권한의 역할과 종류
데이터베이스 관리자의 시스템 권한
- create user: 새롭게 사용자를 생성하는 권한
- drop user: 사용자를 삭제하는 권한
- drop any table: 임의의 테이블을 삭제할 수 있는 권한
- query rewrite: 함수 기반 인덱스를 생성하는 권한
- backup any table: 임의의 테이블을 백업할 수 있는 권한
사용자를 위한 시스템 권한
- create session: 데이터베이스에 접속할 수 있는 권한
- create table: 사용자 스키마에서 테이블을 생성할 수 있는 권한
- create view: 사용자 스키마에서 뷰를 생성할 수 있는 권한
- create sequence: 사용자 스키마에서 시퀀스를 생성할 수 있는 권한
- create procedure: 사용자 스키마에서 함수를 생성할 수 있는 권한
14.2.2 권한을 부여하는 GRANT 명령어
sys
-- 권한부여
grant connect, resource to tester2;
-- 권한 회수
revoke connect, resource from tester2;
-- 권한 부여
grant create session to tester2;create table 권한 부여하기
tester2
show user;
-- 테이블 생성하기
create table emp01(
empno number(4),
ename varchar2(10),
job varchar2(9),
depno number(2)
);sys
grant create table to tester2;14.2.3 WITH ADMIN OPTION
WITH ADMIN OPTION을 지정하여 권한 부여
-- sys로 접속하기
-- 사용자 생성과 권한 부여하기
create user tester3 identified by 1234;
grant create session to tester3
with admin option;
-- tester3 사용자로 접속하기
-- 권한 부여하기
grant create session to tester2;WITH ADMIN OPTION을 지정하지 않고 권한 부여
-- sys로 접속하기
-- 사용자 생성과 권한 부여
create user tester4 identified by 1234;
grant create session to tester4;
-- tester4 사용자로 접속하기
-- 권한 부여하기
grant create session to tester2;14.2.4 객체 권한
다른 유저의 객체에 접근하기
-- tester2 사용자로 접속하기
-- 테이블 조회하기
select * from dept;테이블 객체에 대한 SELECT 권한 부여하기
-- tester1 사용자로 접속하기
-- 객체 권한 부여하기
grant select on dept to tester2;
-- 테이블 조회하기
show user
select * from dept;14.2.7 사용자에게서 권한을 뺏기 위한 REVOKE 명령어
객체 권한 제거하기
-- tester1 사용자로 접속하기
-- tester 사용자가 다른 사용자에게 부여한 권한 정보 조회하기
select * from USER_TAB_PRIVS_MADE;
-- SELECT 권한을 철회하기
revoke select on dept from tester2;
-- tester1 사용자가 다른 사용자에게 부여한 권한 정보 조회하기
select * from USER_TAB_PRIVS_MADE;
-- 테이블 조회하기
select * from teester1.dept;14.2.8 WITH GRANT OPTION
- 사용자는 그 객체를 접근할 권한을 부여 받음과 동시에, 그 권한을 다른 사용자에게 부여할 수 있는 권한도 함께 부여 받게 된다.
WITH GRANT OPTION을 지정하여 객체 권한 부여하기
-- tester1 사용자로 접속하기
-- 권한 부여하기
grant select on tester1.dept to tester3
with grant option;
-- tester3 사용자로 접속하기
-- 권한 부여하기
grant select on tester1.dept to tester2;WITH GRANT OPTION을 지정하지 않고 객체 권한 부여하기
-- tester1 사용자로 접속하기
grant select on tester1.dept to tester4;
-- 사용자 접속하기
-- 권한 부여하기
grant select on tester1.dept to tester2;14.3 롤을 사용한 권한 부여
14.3.1 사전 정의된 롤의 종류
CONNECT 롤
사용자가 데이터베이스에 접속 가능하도록 하기 위해서 다음과 같이 가장 기본적인 시스템 권한 8가지를 묶어 놓았다.
RESOURCE 롤
사용자가 객체(테이블, 뷰, 인덱스)를 생성할 수 있도록 하기 위해서 시스템 권한을 묶어 놓았다.
DBA 롤
사용자들이 소유한 데이터베이스 객체를 관리하고, 사용자들을 작성하고 변경하고 제거할 수 있도록 하는 모든 권한을 가진다. 시스템 자원을 무제한적으로 사용하며, 시스템 관리에 필요한 모든 권한을 부여할 수 있는 강력한 건한을 보유한 롤이다.
롤 부여하기
-- sys로 접속하기
-- 사용자가 생성하여 접속하기
create user tester5 identified by 1234;
conn tester5@pdborcl/1234
-- sys로 접속하기
-- 권한 부여하기
grant connect, resource to tester5;14.3.2 롤 관련 데이터 딕셔너리
- ROLE_SYS_PRIVS: 롤에 부여된 시스템 권한 정보
- ROLE_TAB_PRIVS: 롤에 부여된 테이블 관련 권한 정보
- USER_ROLE_PRIVS: 접근 가능한 롤 정보
- USER_TAB_PRIVS_MADE: 해당 사용자 소유의 오브젝트에 대한 오브젝트 권한 정보
- USER_TAB_PRIVS_RECD: 사용자에게 부여된 오브젝트 권한 정보
- USER_COL_PRIVS_MADE: 사용자 소유의 오브젝트 중 컬럼에 부여된 오브젝트 권한 정보
- USER_COL_PRIVS_REDC: 사용자에게 부여된 특정 컬럼에 대한 오브젝트 권한 정보
14.3.3 사용자 롤 정의
-- 테이블 조회하기
select * from tester1.dept;롤을 생성하여 시스템 권한 할당하기
-- sys로 접속하여 롤 생성하기
show user
-- 롤에 권한 부여하기
grant create session, create table, create view to mrole;
-- 사용자를 생성하여 롤 부여하기
create user tester6 identified by 1234;
grant mrole to tester6;
-- tester6 사용자로 접속해서 부여된 롤 확인하기
select * from user_role_privs;롤을 생성하여 객체 권한 할당하기
-- sys로 접속하여 롤 생성하기
show user
alter session set container=PDBORCL;
create role mrole2;
-- 롤에 객체 권한 부여하기
grant select on dept to mrole2;
-- tester6에게 롤 부여하기
grant mrole2 to tester6;
-- tester6에게 부여된 롤 확인하기
select * from user_role_privs;
-- 테이블 조회하기
select * from tester1.dept;
-- 롤 확인하기
column role format A10
column owner format A10
column column_name format A15
column privilege format A15
select *
from role_tab_privs
where table_name in ('dept');14.3.4 롤 회수하기
롤 회수하기
-- 부여된 롤 권한 확인하기
select * from user_role_privs;
-- 부여된 롤 회수하기
revoke mrole2 from tester6;
-- 부여된 롤 권한 확인하기
select * from user_role_privs;롤 제거하기
-- 롤 확인하기
select * from user_role_privs
where granted_role like '%mrole%';
-- 롤 제거하기
drop role mrole2;
select * from user_role_privs
where granted_role like '%mrole%';14.3.5 롤의 장점
디폴트 롤을 생성하여 여러 사용자에게 권한 부여하기
-- 롤 생성하기
CREATE ROLE DEF_ROLE;
-- 롤에 권한 부여하기
GRANT CREATE SESSION TO DEF_ROLE;
GRANT CREATE TABLE TO DEF_ROLE;
-- 롤에 객체 권한 부여하기
GRANT UPDATE ON dept TO DEF_ROLE;
GRANT DELETE ON dept TO DEF_ROLE;
GRANT SELECT ON dept TO DEF_ROLE;
-- 사용자 생성하기
CREATE USER USERA1 IDENTIFIED BY A1234;
CREATE USER USERA2 IDENTIFIED BY A1234;
CREATE USER USERA3 IDENTIFIED BY A1234;
-- 롤 부여하기
show user
GRANT DEF_ROLE TO USERA1;
GRANT DEF_ROLE TO USERA2;
GRANT DEF_ROLE TO USERA3;
-- 데이터 딕셔너리로 롤 확인하기
SELECT * FROM ROLE_SYS_PRIVS WHERE ROLE='DEF_ROLE';
SELECT * FROM ROLE_TAB_PRIVS WHERE ROLE='DEF_ROLE';
-- 롤 확인하기
SELECT * FROM USER_ROLE_PRIVS;
SELECT * FROM USER_ROLE_PRIVS;
SELECT * FROM USER_ROLE_PRIVS;
-- 롤 부여하기
CREATE USER USERA4 IDENTIFIED BY A1234;
GRANT DEF_ROLE TO USERA4;14.4 동의어
테이블 생성 후 객체 권한 부여하기
-- sys로 접속하기
show user
-- 테이블 생성하기
create table systbl(
ename varchar2(20)
);
-- 테이블 생성하기
INSERT INTO SYSTBL VALUES('전수빈');
INSERT INTO SYSTBL VALUES('정원지');
SELECT * FROM SYSTBL;
-- 객체 권한 부여하기
GRANT SELECT ON. SYSTBL TO tester1;
-- 테이블 조회하기
SELECT * FROM SYSTBL;
-- 테이블 조회하기
SELECT * FROM sys.SYSTBL;동의어 생성하기
-- 동의어 생성하기
CREATE SYSNONYM PRISYSTBL FOR sys.SYSTBL;
SELECT * FROM FRISYSTBL;
-- 동의어 생성하기
alter session set container=PDBORCL;
GRANT CREATE SYNONYM TO tester1;
-- 동의어 생성하기
CREATE SYNONYM PRISYSTBL FOR sys.SYSTBL;
SELECT * FROM PRISYSTBL;비공개 동의어 의미 파악하기
-- 롤을 생성하여 권한 부여하기
CREATE ROLE TEST_ROLE;
GRANT CONNECT, RESOURCE, CREATE SYNONYM TO TEST_ROLE;
GRANT SELECT ON tester1.DEPT TO TEST_ROLE;
-- 사용자 생성하기
CREATE USER USERB1 IDENTIFIED BY B1234;
CREATE USER USERB2 IDENTIFIED BY B1234;
-- 롤 부여하기
GRANT TEST_ROLE TO USERB1;
GRANT TEST_ROLE TO USERB2;공개 동의어 정의하기
-- 공개 동의어 생성하기
alter session set container=PDBORCL;
CREATE PUBLIC SYNONYM PubDEPT FOR tester1.DEPT;
-- USERB1과 USERB2 계정으로 접속하여 DEPT로 테이블 조회한다.
CONN USERB1@pdborcl/B1234
SELECT * FROM PUBDEPT;
CONN USERB2@pdborcl/B1234
SELECT * FROM PUBDEPT;비공개 동의어 제거하기
-- 비공개 동의어의 제거 실피
CONN USERB2@pdborcl/B1234
DROP SYNONYM DEPT;
-- 비공개 동의어의 제거 실패
alter session set container=PDBORCL;
DROP SYNONYM DEPT;
-- 비공개 동의어의 제거
CONN USERB1@pdborcl/B1234
DROP SYNONYM DEPT;공개 동의어 제거하기
-- 공개 동의어의 제거 실패
CONN USERB1@pdborcl/B1234
DROP SYNONYM PUBDEPT;
-- 공개 동의어의 제거 실패
alter session set container=PDBORCL;
DROP SYNONYM PUBDEPT;
-- 공개 동의어의 제거
DROP PUBLIC SYNONYM PUBDEPT;ORACLE 구조와 SQL문장 처리순서
ORACLE Startup 절차
SQL> STARTUP
1. NOMOUNT
→ PARAMETER FILE (initSID.ora) READ
SGA 구성. BACKGROUND PROCESS를 생성.
2. MOUNT
→ CONTROL FILE READ
일반적인 DATABASE 정보 확인 DATAFILE, REDOLOG FILE의 위치와 상태 동기화 정보(SCN) 확인
3. OPEN →DATAFILE OPEN
DATABASE READ, WRITE 가능
Oracle 서버
- 정보를 개방적이고 포괄적이며 통합적으로 관리할 수 있는 데이터베이스 관리 시스템이다.
- Oracle 인스턴스와 오라클 데이터베이스로 구성된다.
Oracle 인스턴스
- 오라클 데이터베이스를 액세스하는 수단이다.
- 항상 한 번에 한 개의 데이터베이스만 연다.
- 메모리와 백그라운드 프로세스 구조로 구성된다.
오라클 데이터베이스
- 하나의 단위로 취급되는 데이터 모음이다.
- 세 가지 파일 유형으로 구성된다.
- 데이터 파일
- 제어 파일
- 리두 로그 파일
물리적 구조
- 물리적 구조에는 다음 세 가지 파일 유형이 포함된다.
- 제어 파일
- 데이터 파일
- 온라인 리두 로그 파일
메모리 구조
- Oracle의 메모리 구조는 다음 두 가지 메모리 영역으로 구성된다.
– SGA(시스템 글로벌 영역): 인스턴스가 시작될 때 할당되며 Oracle 인스턴스의 기본적인 구성 요소이다.
– PGA(프로그램 글로벌 영역): 서버 프로세스가 시작될 때 할당된다.
시스템 글로벌 영역
- SGA는 여러 메모리 구조로 구성됩니다.
- 공유 풀
- 데이터베이스 버퍼 캐시
- 리두로그버퍼
- 기타구조(예:잠금및래치관리,통계데이터)
- SGA에는 다음 두 가지 메모리 구조를 추가로 구성할 수 있습니다.
- 대용량 풀
- Java 풀
- 동적입니다.
- SGA_MAX_SIZE 매개변수로 크기를 조정합니다.
- SGA 구성 요소를 통해 그래뉼에 할당되고 추적됩니다.
- 연속적인 가상 메모리 할당
- 예상된 총 SGA_MAX_SIZE 기준의 그래뉼 크기
연결 설정 및 세션 생성
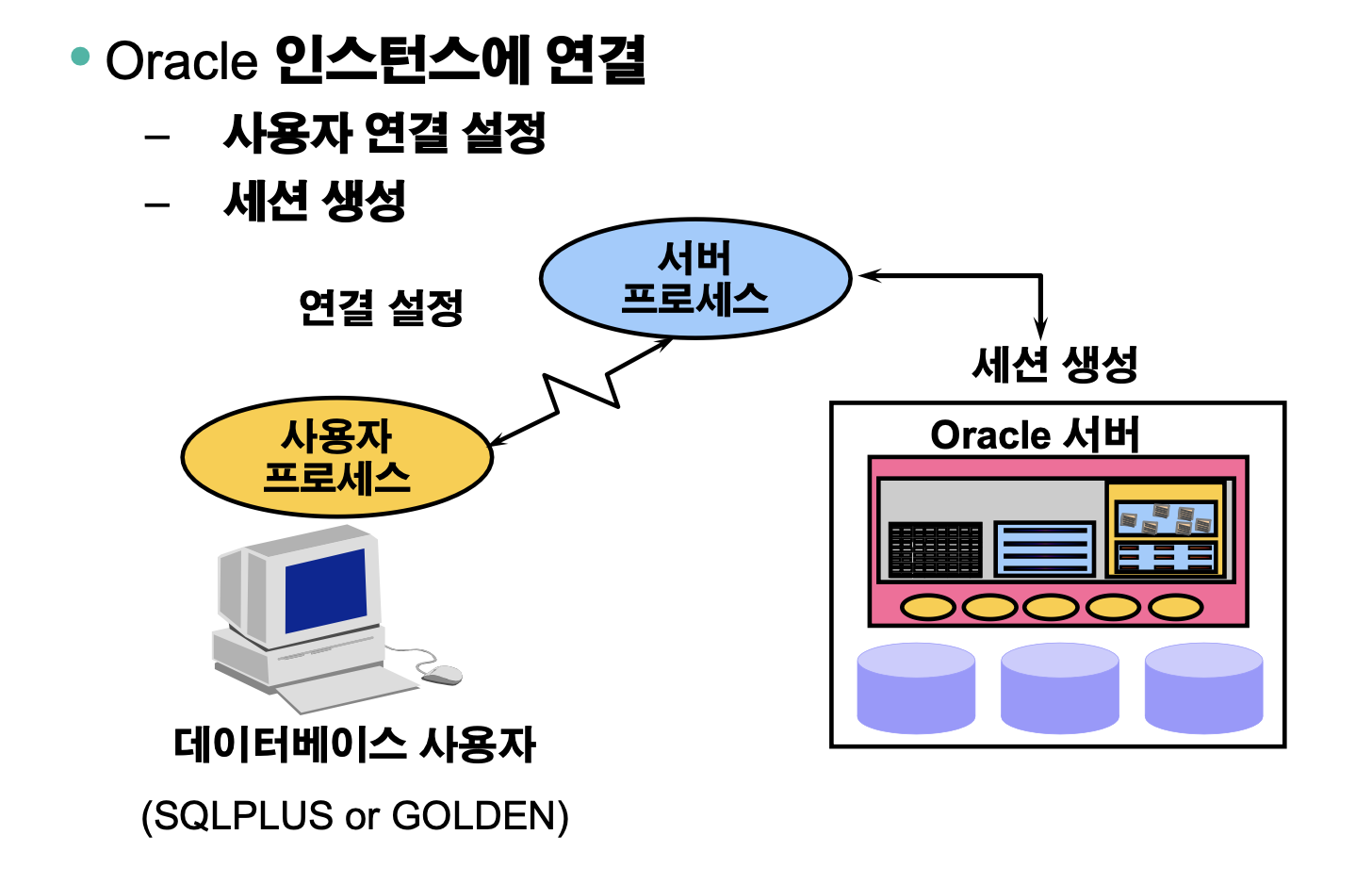
SQL문 처리
- 다음을 사용하여 인스턴스에 연결합니다.
- 사용자 프로세스
- 서버 프로세스
- 사용하는 Oracle 서버 구성 요소는 SQL 문 유형에 따라 다릅니다.
- 질의는 행을 반환합니다.
- DML 문은 변경 사항을 기록합니다.
- 커밋은 트랜잭션 복구를 보장합니다.
- 일부 Oracle 서버 구성 요소는 SQL 문 처리에 관여하지 않습니다.
SELECT 문 수행 순서
- PARSE
• 동일한 문장이 존재하는지 check
• 동일한 문장이 존재하면 기존 공간을 사용,
존재하지 않으면 새롭게 공간을 확보
• 문법 검사, schema 검사, 권한 검사
• 실행 계획 생성(OPTIMIZER) - BIND : bind variable을 사용하는 경우
- EXECUTE
• 찾고자 하는 block이 데이터베이스버퍼캐쉬에 존재하는지 확인 → 존재하면 그냥 사용, 존재하지 않으면 데이터파일로부터 메모리로 load
• 서버 프로세스에 의한 데이터 처리 - FETCH
SELECT 문 수행 순서
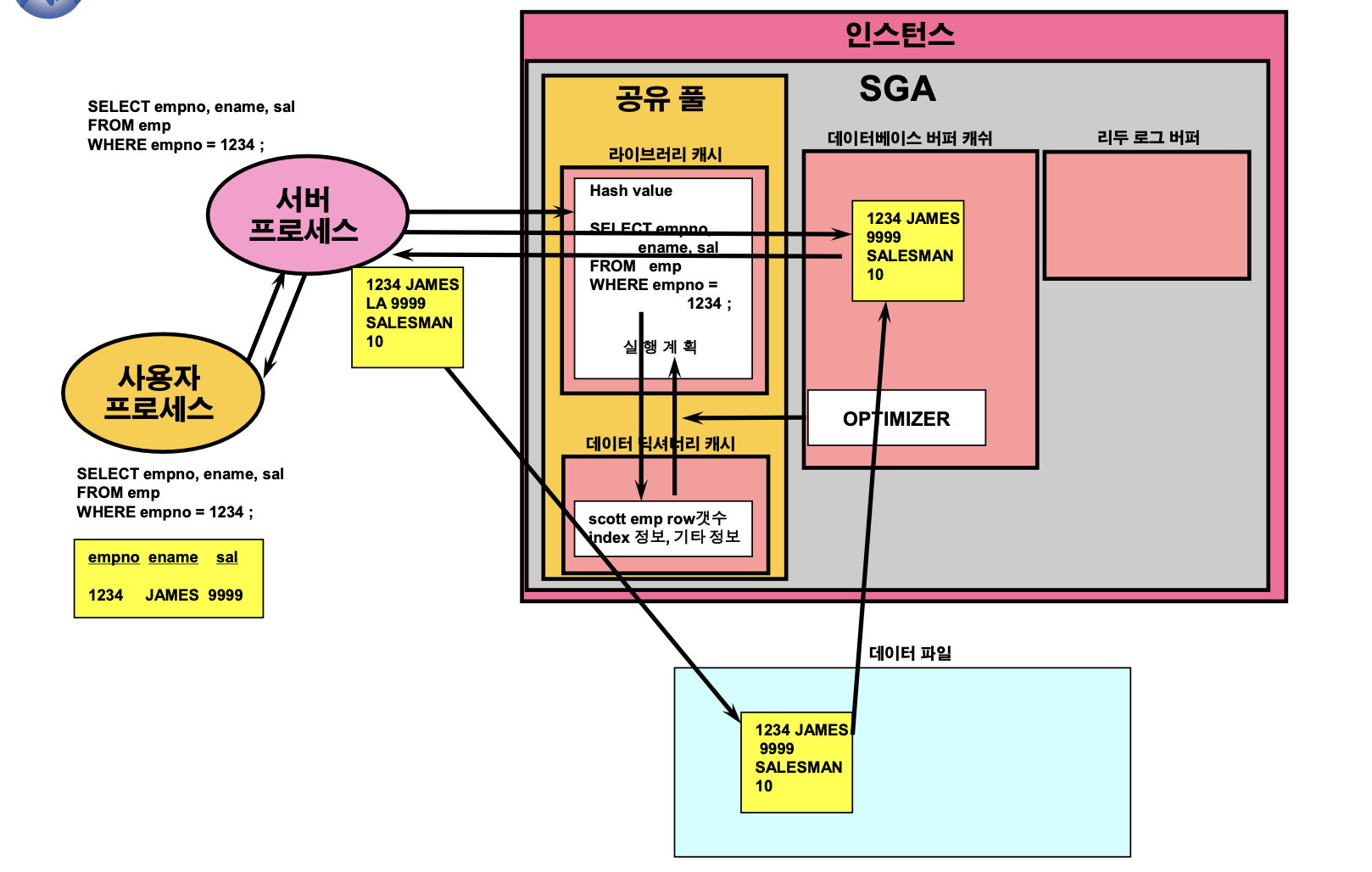
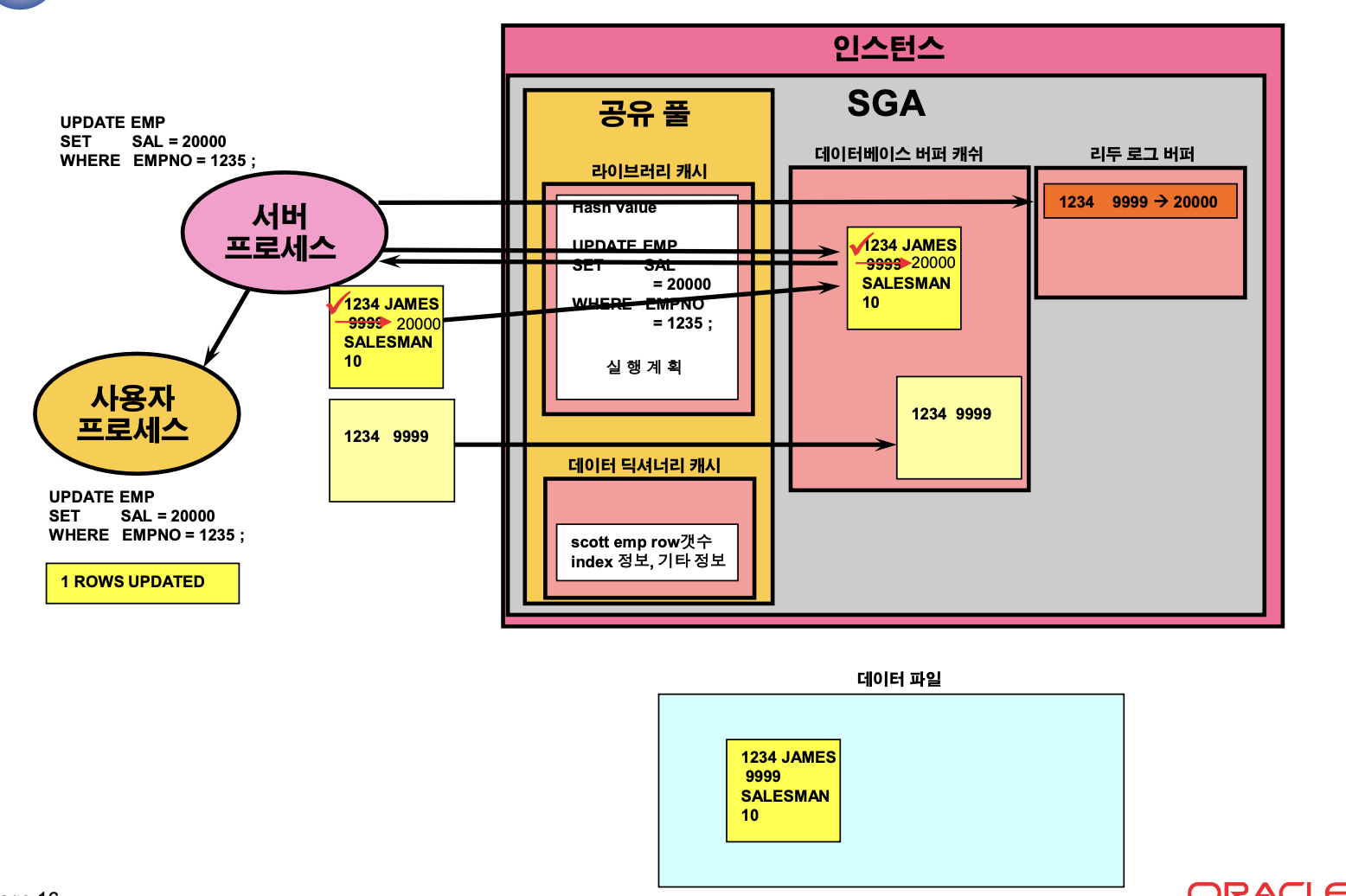
DML(UPDATE)문 수행 순서
- PARSE
• SELECT 문과 동일 - BIND
- EXECUTE
• 데이터 로드는 SELECT문과 동일
• 데이터베이스 버퍼 캐쉬에 UNDO(ROLLBACK) SEGMENT BLOCK을 점유
• 해당 로에 락을 걸면서 데이터를 변경(이후 이미지)
• UNDO SEGMENT BLOCK에 이전 이미지 기록
• 리두로그 버퍼에 리두 엔트리(이전, 이후 이미지. 로의 위치) 기록
UPDATE 문 수행 순서
ROLLBACK 및 COMMIT 처리 순서
- ROLLBACK
- UNDO SEGMENT BLOCK에 있는 이후이미지가 원
데이터블럭에 덮어 쓰여 짐 - LOCK 해제
- UNDO SEGMENT BLOCK에 있는 이후이미지가 원
- COMMIT
- REDO LOG BUFFER에 있는 REDO ENTRY들이 LGWR에 의해서 REDO LOG FILE에 쓰여짐
- LOCK 해제
ROLLBACK
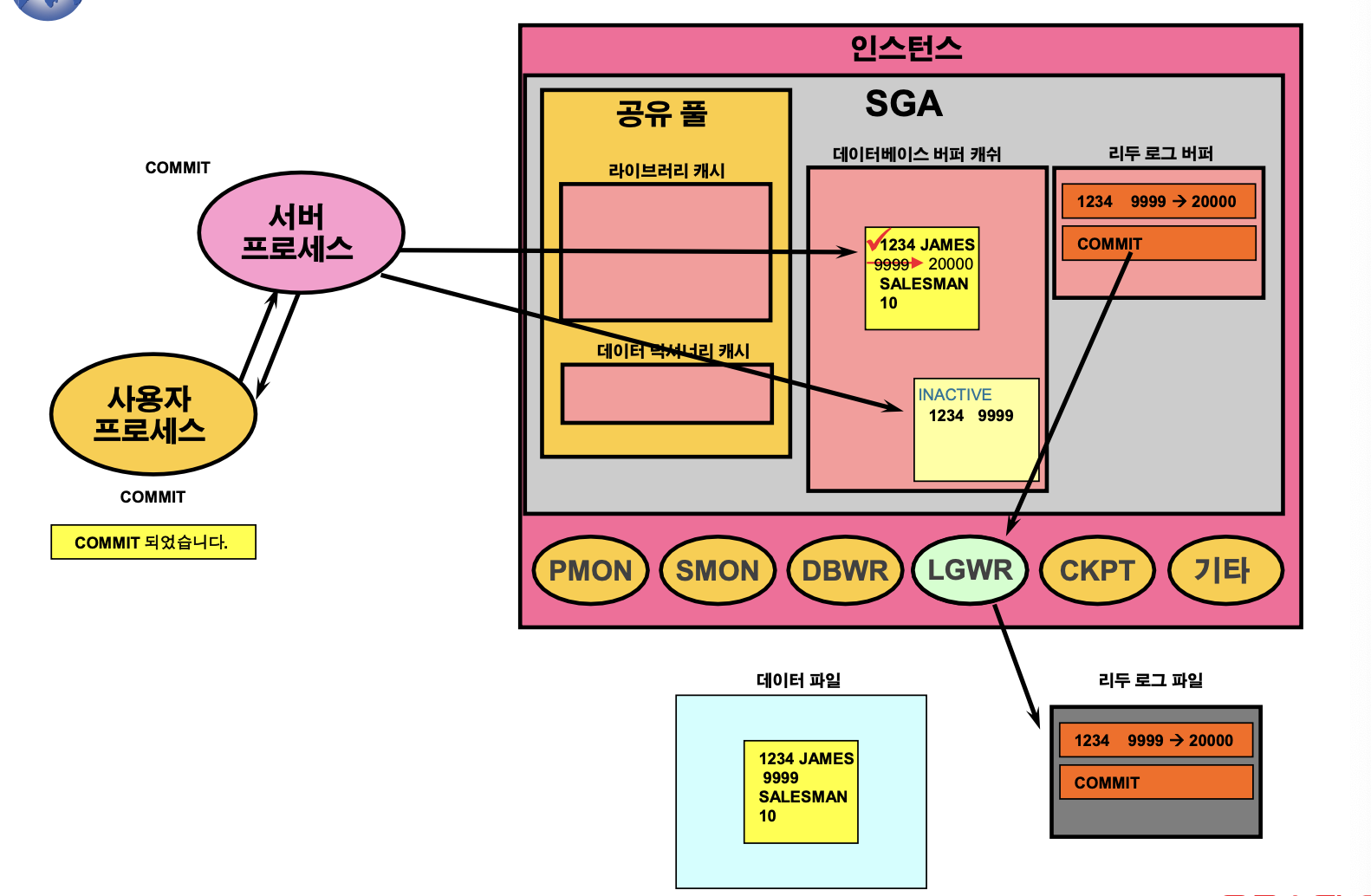
COMMIT
OPTIMIZER MODE
- RULE BASED
- 수행가능한실행계획들을구함
- ranking system에 따라서 순위를 결정
- 가장빠른순위를선택하여수행
- COST BASED
- 수행가능한실행계획들을구함
- 통계정보를근거로하여각실행계획의비용을산정
- 가장적은비용의SQL을선택하여수행
RULE vs cost OPTIMIZER
SELECT 주문일자, 상품, 수량 FROM 주문 WHERE 주문일자 = ‘20070101’ AND 수량 > 1000 ;
주문일자와 수량 컬럼에 각각 인덱스가 걸려있는 경우
- 예상실행계획
- 주문일자 : path 10(bounded range search)
- 수량 : path 11(unbounded range search)
- full table scan : path 15
- 해당 되는 로의 수에 관계없이 무조건 주문 일자 인덱스를 사용
rule vs COST OPTIMIZER
SELECT 주문일자, 상품, 수량 FROM 주문 WHERE 주문일자 = ‘20070101’ AND 수량 > 1000 ;
주문일자와 수량 컬럼에 각각 인덱스가 걸려있는 경우
- 예상실행계획
- 주문일자 인덱스 이용 : 예상 비용→35
- 수량인덱스이용:예상비용→10
- full table scan : 예상 비용→5
- 예상 비용(cost)을 비교하여 가장 비용이 낮은 full table scan을 선택하므로 일반적으로 효율적인 실행계획이 수행 됨.
- 단점: cost 비교가 항상 올바른 것은 아니다.
OPTIMIZER MODE 설정
- INSTANCE LEVEL
- OPTIMIZER_MODE = CHOOSE | RULE | FIRST_ROWS | FIRST_ROWS_n | ALL_ROWS
- SESSION LEVEL
- ALTER SESSION SET OPTIMIZER_MODE = CHOOSE | RULE | FIRST_ROWS | FIRST_ROWS_n | ALL_ROWS
- STATEMENT LEVEL
- 힌트사용
공유풀
- 다음을 저장하는 데 사용됩니다.
- 가장최근에실행한SQL문
- 가장 최근에 사용한 데이터 정의
- 두 가지 주요 성능 관련 메모리 구조로 구성됩니다.
- 라이브러리 캐시
- 데이터 딕셔너리 캐시
- SHARED_POOL_SIZE
- 매개변수로 크기를 조정합니다.
