4.7.1 중첩 루프 조인
중첩 for문과 같은 원리로 조건에 맞는 조인을 하는 방법
랜덤 접근에 대한 비용이 많이 증가하므로 대용량의 테이블에서는 사용하지 X
ex) "t1, t2 테이블을 조인한다"라고 하면 첫번 째 테이블에서 행을 한번에 하나씩 읽고 그 다음 테이블에서도 행을 하나씩 읽어 조건에 맞는 레코드를 찾아 결괏값을 반환
<의사 코드>
for each row in t1 matching reference key {
for each row in t2 matching reference key {
if row satisfies jion conditions, send to client
}
}💡 참고
중첩 루프 조인에서 발전한 조인할 테이블을 작은 블록으로 나눠서 블록 하나씩 조인하는 블록 중첩 루프 조인(Block Nested Loop)라는 방식도 존재
4.7.2 정렬 병합 조인
- 각각의 테이블을 조인할 필드 기준으로 정렬하고 정렬이 끝난 이후로 조인 작업을 수행하는 조인
- 조인할 때 쓸 적절한 인덱스가 없고 대용량의 테이블들을 조인하고 조인 조건으로 <,> 등 범위 비교 연산자가 있을 때 사용
4.7.3 해시 조인
- 해시 테이블을 기반으로 조인하는 방법
- 두개의 테이블을 조인한다고 했을 때 하나의 테이블의 메모리에 온전히 들어간다면 보통 중첩 루프 조인보다 더 효율적.(메모리에 올릴 수 없을 정도로 크다면 디스크를 사용하는 비용이 발생)
- 동등(=)조인에서만 사용 가능
MySQL의 경우 MySQL8.0.18 릴리스와 함께 이 기능을 사용할 수 있게 되었으며 이를 기반으로 하는 조인의 과정을 살펴보자.
MySQL의 해시 조인 단계
- 빌드 단계, 프로브 단계로 나뉜다.
빌드 단계
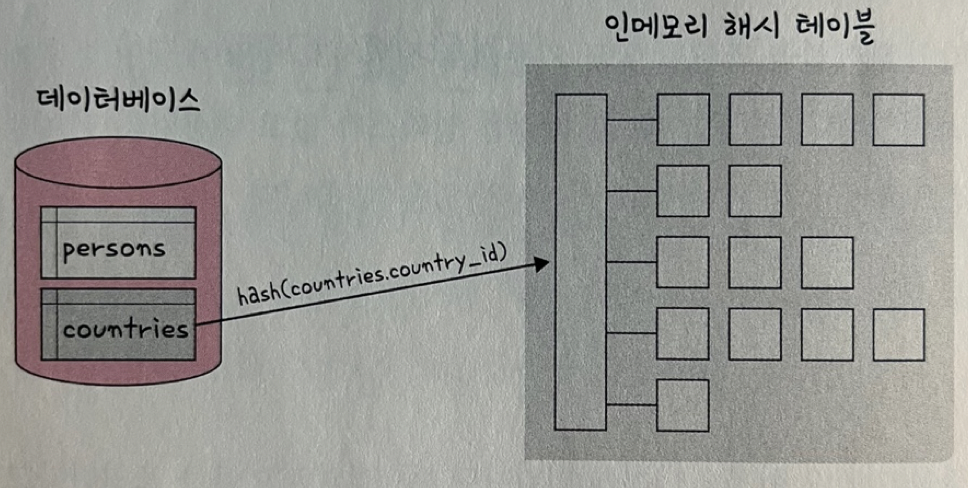
- 입력 테이블 중 하나를 기반으로 메모리 내 해시 테이블을 빌드하는 단계
- persons와 countries라는 테이블을 조인한다고 했을 때 둘 중에 바이트가 더 작은 테이블을 기반으로 해서 테이블을 빌드
- 또한 조인에 사용되는 필드가 해시 테이블의 키로 사용.
(countries.country_id가 키로 사용되는 것 확인 가능)
프로브 단계
- 프로브 단계 동안 레코드 읽기를 시작하며, 각 레코드에서 'Person.country_id'에 일치하는 레코드를 찾아서 결괏값으로 반환
- 이를 통해 각 테이블은 한 번씩만 읽게 되어 중첩해서 두개의 테이블을 읽는 중첩 루프조인보다 보통은 성능이 더 좋다. 참고로 사용 가능한 메모리양은 시스템 변수 join_buffer_size에 의해 제어되며, 런타임 시에 조정 가능

[참고링크]

개발 기록장