시작하기 전에...
먼저, 간단하게 핵심적인 내용들부터 정리를 하고 들어가겠습니다.
Redis(REmote DIctorionary Server)는 고성능의 키-값(key-value) 구조를 가진 인메모리 데이터 스토어입니다. 주로 캐싱, 메시징 큐, 빠른 읽기/쓰기가 필요한 곳에 사용됩니다.
Redis의 특징
- 인메모리 데이터 스토어:
- Redis의 데이터는 주로 메모리에 저장됩니다. 이 때문에 디스크 기반의 데이터베이스보다 훨씬 빠른 성능을 제공합니다.
- 다양한 데이터 구조 지원:
- Redis는 단순한 키-값 저장 뿐만 아니라, 리스트, 세트, 해시, 정렬된 세트, 비트맵 등 다양한 데이터 구조를 지원합니다.
- 지속성:
- 인메모리 데이터이지만, 데이터를 디스크에 저장할 수 있는 옵션(RDB, AOF)을 제공하여 지속성을 보장합니다.
- 복제 및 확장성:
- 데이터의 복제(replication)을 지원하여 고가용성을 제공합니다. 또한, 분산 처리를 통해 확장성도 갖추고 있습니다.
- Pub/Sub 시스템:
- Redis는 발행/구독 모델을 지원하여, 메시징 시스템으로도 활용될 수 있습니다.
Redis의 역할과 동작
- 캐싱:
- Redis의 가장 일반적인 사용 사례는 캐싱입니다. 빈번하게 읽는 데이터나 계산 비용이 큰 쿼리 결과를 Redis에 저장하여, 데이터베이스의 부하를 줄이고 빠른 응답 시간을 보장합니다.
- 세션 스토어:
- 웹 애플리케이션에서 세션 정보를 Redis에 저장하여, 사용자 인증 상태를 빠르고 효율적으로 관리할 수 있습니다.
- 실시간 애플리케이션:
- 게임, 채팅, 실시간 분석 등의 애플리케이션에서 빠른 데이터 읽기/쓰기가 필요할 때 Redis를 사용합니다.
- 큐 시스템:
- Redis의 리스트와 발행/구독 기능을 활용하여 메시징 큐 시스템을 구현할 수 있습니다.
- 동작 매커니즘:
- 클라이언트는 Redis 서버와 TCP/IP를 통해 연결합니다.
- 클라이언트는 Redis 프로토콜을 사용하여 명령을 보냅니다.
- Redis 서버는 이러한 명령을 처리하고, 결과를 메모리에 저장하거나 클라이언트에 반환합니다.
위의 내용은 핵심적인 내용을 간단하게 정리한 것이고, 본격적으로 아래에서 부터 천천히 깊이 있게 살펴보겠습니다.
Redis
위에서 Redis가 무엇인지는 설명을 했습니다.
Redis는 애플리케이션 서비스를 제공하는 서버에서도 동작할 수 있지만, 가장 많이 사용하는 형태는 다른 서버에서 Redis 서버를 구축하여 사용됩니다.
여러 용도로 활용될 수 있는데, 먼저 가장 많이 사용되는 캐싱 용도로 사용하는 경우에 대해서 정리를 해보도록 하겠습니다.
캐싱
일반적으로 캐싱 전략을 위하여 Redis를 사용할 경우, Lazy Loding 방법을 통하여 데이터를 탐색합니다. 해당 방식은 읽기 전략에서 사용됩니다.
데이터에 대한 읽기 요청이 들어왔을 때, DB를 탐색하는 것이 아닌 우선 Redis서버에 데이터가 있는지 확인합니다.
Redis는 1ms 보다 낮은 속도를 자랑하기 때문에 굉장히 빠른 속도로 데이터를 검색할 것이고, 만약 데이터가 있다면 해당 데이터를 반환하여 빠른 응답을 기대할 수 있습니다.
하지만, Cache miss가 발생할 경우 데이터베이스에 조회를 하는 작업을 수행해야 하며 극단적인 상황인 경우 초기에 대량의 Cache miss가 발생하여 성능 저하를 초래할 수 있습니다.
이를 예방하기 위해서 Cache Warming을 고려해볼 수 있는데, 이것은 DB에서 Redis 서버로 직접 데이터를 전송해주는 작업을 의미합니다.
이 작업을 통해서 Cache miss의 발생을 줄일 수 있습니다.
해당 패턴을 Look Aside 패턴이라고 합니다.
다음으로 쓰기 전략을 확인해 보겠습니다.
쓰기 전략은 크게 두가지로 나눌 수 있습니다.
- Write-Around
- Write-Through
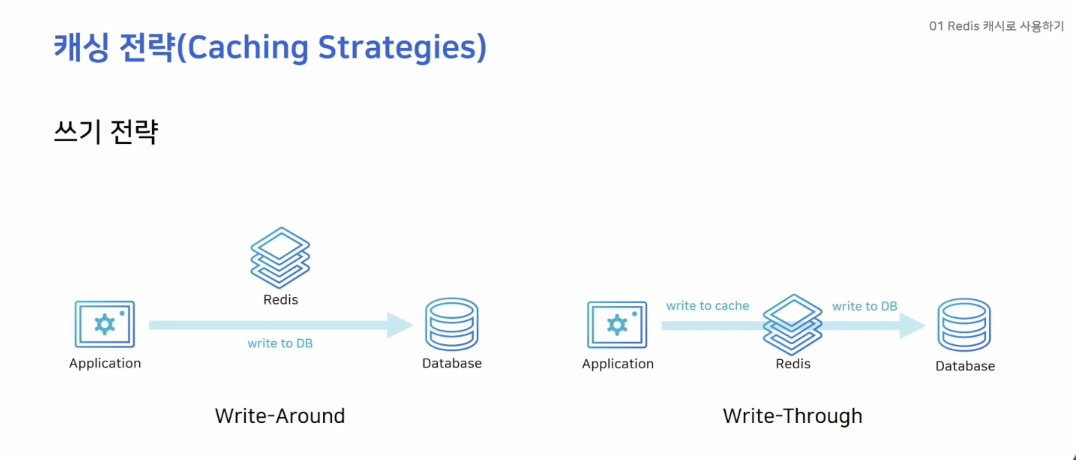
Write-Around 방식의 경우 데이터 쓰기 작업을 DB에 직접하는 방법을 의미합니다. 그리고 Cache miss가 발생했을 경우에 Cache에 데이터를 끌어오게 됩니다.
Write-Through 방식의 경우 데이터를 저장할 때 Cache 서버에 저장을 수행하고, Cache 서버에서 Database에 데이터를 저장하는 방법을 의미합니다.
해당 방식은 Cache가 항상 최신 데이터를 가지고 있다는 장점이 존재하지만, 저장할 때마다 두 단계 과정을 거쳐야하기 때문에 상대적으로 속도가 느리다는 단점이 있습니다. 그리고 저장한 데이터가 활용되지 않을 수 있는데도 불구하고 무조건적으로 캐시에 저장하기 때문에 일종의 리소스 낭비가 발생할 수 있습니다.
마지막 단점을 보완하기 위해서 expires time을 고려할 수 있긴 합니다.
타입
Redis는 여러 가지 타입을 지원합니다.
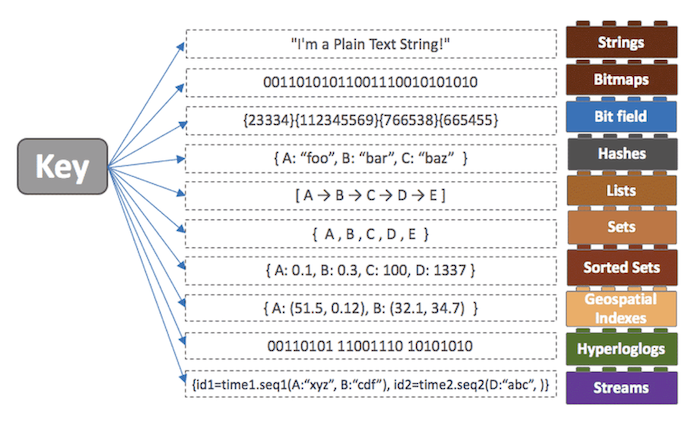
- String: 기본적인 데이터 타입, set 커맨드 이용
- Bitmaps: String의 변형, bit 단위 연산 가능
- Hashes: 하나의 키 안에 여러개의 필드와 밸류 쌍으로 데이터 저장
- Lists: 데이터를 순서대로 저장, 큐로 사용하기 적절
- Sets: 중복되지 않은 문자열의 집합
- Sorted Sets: 모든 값은 score라는 숫자 값으로 정렬, score가 같을 경우 사전 순으로 정렬
- Hyperloglogs: 굉장히 많은 데이터를 다룰 때 사용, 중복되지 않은 값의 개수를 카운트할 때 사용
- Streams: log를 저장하기 좋은 자료 구조
Hyperloglogs
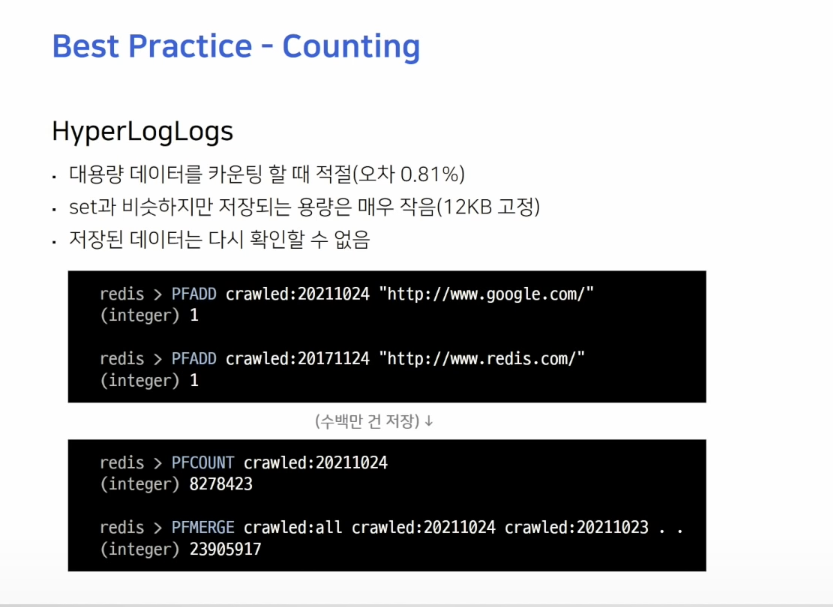
이는 Set과 비슷하지만, 대용량의 데이터를 카운트할 때 유용하게 쓰일 수 있습니다.
우선 Set과 유사하기 때문에 String 값들을 유니크하게 구분할 수 있고, 저장되는 데이터의 개수와 상관없이 모든 값이 12KB로 고정되어 저장됩니다.
대신 한번 저장된 값은 다시 불러올 수 없는데, 경우에 따라 데이터를 보호하기 위한 목적으로도 적절하게 사용할 수 있습니다.
예를 들어보자면, 웹사이트에 방문한 IP가 유니크하게 몇 개가 되는지, 하루 종일 크롤링한 URL의 개수가 몇 개인지, 검색 엔진에서 검색된 유니크한 단어가 몇 개인지 등 크고 Unique한 값을 계산할 때 적절합니다.
Messaging
Redis의 Lists는 메시징 큐로 사용하기 적절합니다. 특히 자체적으로 blocking 기능을 제공하기 때문에 적절히 사용하면 불필요한 polling을 막을 수 있습니다.
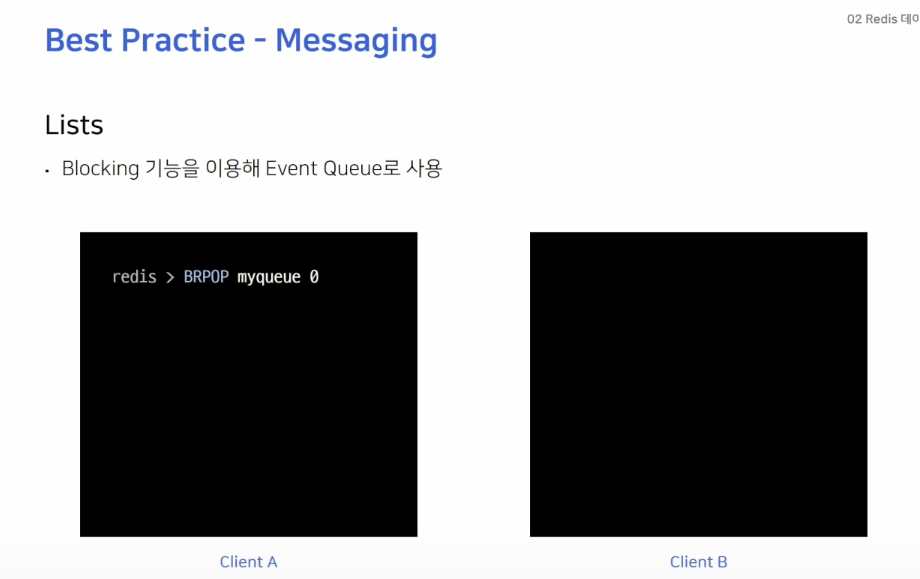
위의 예시에서 Client A가 BRPOP 커맨드를 사용해 myqueue에서 데이터를 가져오려고 하지만 리스트 안에 데이터가 없어 대기를 하고 있는 상황입니다.
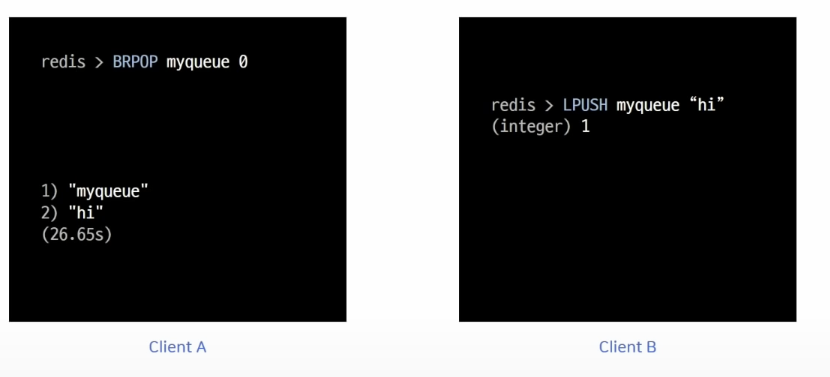
Client B가 데이터를 넣어줄 경우 Client A에서 바로 이 값을 확인할 수 있습니다.
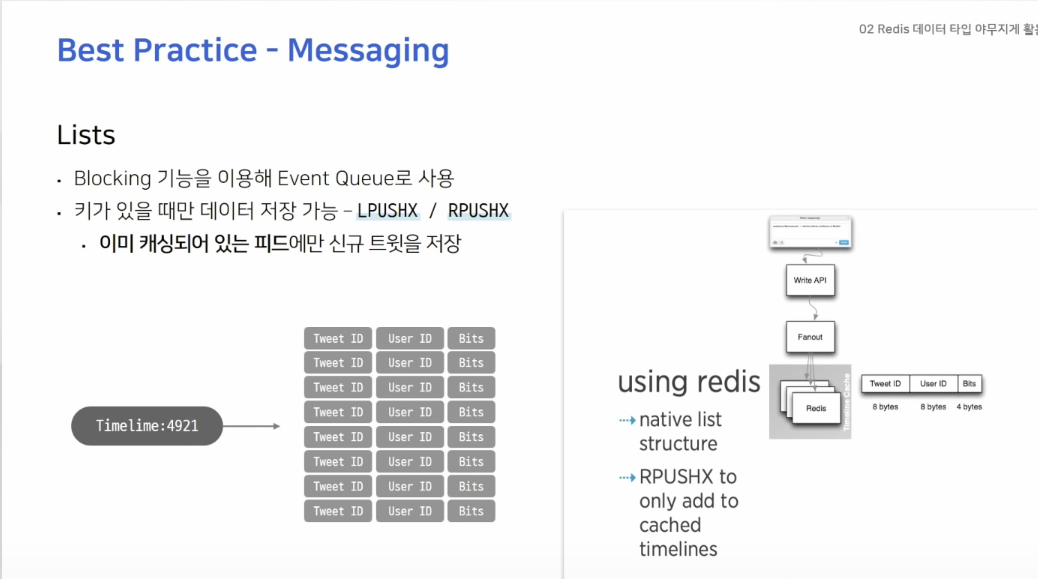
LPUSHX나 RPUSHX 같은 커맨드를 사용하면 키가 있을 때에만 그 리스트에 데이터를 추가하는데, 이것을 활용하여 사용했던 queue에만 메시지를 넣어줄 수 있기 때문에 비효율적인 데이터의 이동을 막을 수 있습니다.
인스타그램, 페이스북이나 트위터같은 SNS에는 각 유저별로 타임라인이 존재하고 타임라인에 팔로우한 사람들의 데이터를 확인할 수 있는데, 트위터에서는 각 유저의 타임라인에 보일 트윗을 캐싱하기 위해 레디스의 리스트를 사용합니다.
이때RPUSHX커맨드를 사용합니다.
이를 이용해서 트위터를 자주 이용하던 유저의 타임라인에만 새로운 데이터를 미리 캐시해 놓을 수 있으며 자주 사용하지 않는 유저는 caching key 자체가 존재하지 않기 때문에 비효율적인 작업을 방지할 수 있습니다.
Redis에서 데이터를 영구 저장하려면?
Redis는 In-memory 데이터 스토어라고 했습니다.
- 서버 재시작 시 모든 데이터 유실
- 복제 기능을 사용해도 사람의 실수 발생 시 데이터 복원 불가
- Redis를 캐시 이외의 용도로 사용한다면 적절한 데이터 백업이 필요
Redis에서는 데이터를 영구 저장하는 방법으로 두 가지 방법을 제공하고 있습니다.
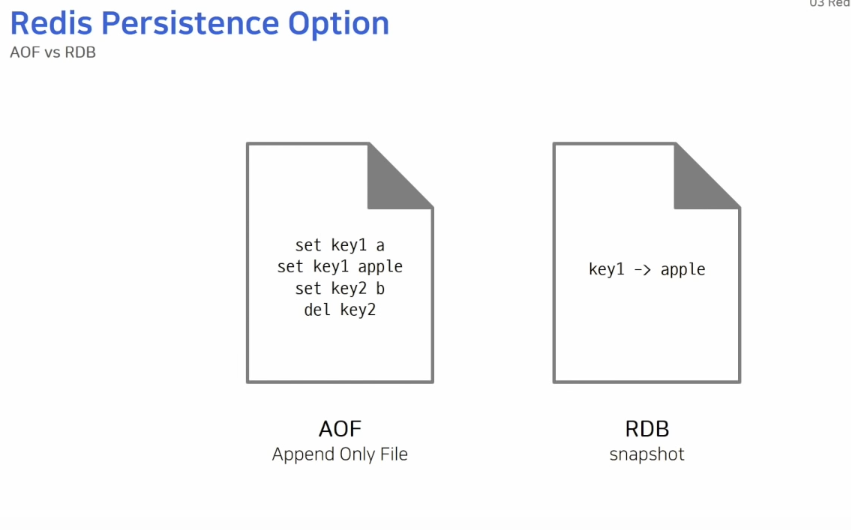
AOF는 데이터를 변경하는 커맨드가 들어오면 커맨드를 그대로 모두 저장합니다.
RDB는 스냅샷 방식으로 동작하기 때문에 저장 당시에 메모리에 있는 데이터 그대로를 사진 찍듯 찍어서 파일로 저장합니다.
AOF는 Append 동작만 수행하기 때문에 데이터가 추가되기만 해서 RDB 파일보다 커지게 됩니다. 따라서, AOF 파일은 주기적으로 압축해서 재작성되는 과정을 거쳐야 합니다.
저장 방식의 형태는 다음과 같습니다.
- AOF - 레디스 프로토콜 형태
- RDB - 바이너리 파일 형태
정리를 하자면 다음과 같습니다.
- RDB (Redis Database): 메모리에 있는 데이터 전체에서 스냅샷을 작성하고, 이를 디스크로 저장하는 방식
- 특정 시간마다 여러 개의 스냅샷을 생성하고, 데이터를 복원해야 한다면 스냅샷 파일을 그대로 로딩
- 스냅샷 이후 변경된 데이터 복구 X -> 데이터 유실(loss)
- AOF(Append Only File): 데이터가 변경되는 이벤트가 발생하면 이를 모두 로그에 저장하는 방식
- 이벤트를 초 단위로 취합 및 로그 파일에 작성
- 모든 데이터의 변경 기록들을 보관하고 있으므로 최신 데이터 정보를 백업 가능
- 데이터 유실량이 적음(초 단위 데이터는 유실 가능)
- RDB 방식보다 로딩 속도가 느리고 파일이 크다.
- 추가적인 프로시저 요구
두 가지의 사용 예는 다음과 같습니다.
-
일부 데이터 손실에 영향을 받지 않는 경우(캐시로만 사용할 때), RDB
-
장애 상황 직전까지의 모든 데이터가 보장되어야 할 경우, AOF
-
강력한 내구성이 필요한 경우, RDB + AOF
-
레디스는 일반적으로 AOF와 RDB를 동시에 사용하여 데이터를 백업한다.
주기적으로 RDB 스냅샷을 생성하고, 그 사이 간격에서의 변경되는 데이터는 AOF로 저장
저장하는 방식의 설정은 수동/자동으로 설정할 수 있겠지만, RDB의 경우 시간을 기준으로 설정하여 저장하도록 설정할 수 있고, AOF는 파일의 크기를 기준으로 설정할 수 있습니다.
Redis 아키텍처 종류
Redis 아키텍처는 간단하게 말하면 3가지 종류로 나누어 집니다.
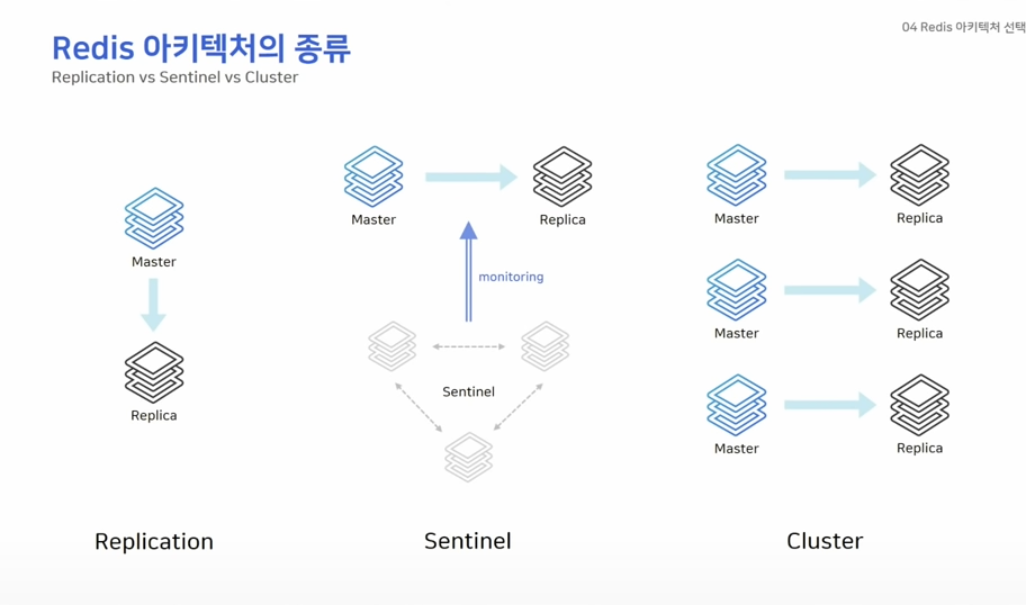
Replication은 마스터와 리플리카만 존재하는 간단한 구조입니다.
Sentinel은 마스터와 리플리카 외에 센티널 노드를 필요로 하는데, 센티널은 일반 노드들을 모니터링하는 역할을 합니다.
Cluster 구성에서는 최소 세대의 마스터가 필요하며 샤딩 기능을 제공합니다.
모든 레디스의 구조에서 복제는 비동기식으로 동작한다는 점을 알아두고 갑시다.
Replication 구성
특징을 정리하자면 다음과 같습니다.
- 단순한 복제 연결에 사용됩니다.
- HA(고가용성) 기능이 없으므로 장애 상황 발생 시 수동으로 복구해야 합니다.
- 장애 발생시, 리플리카 노드에 직접 접속해서 복제를 끊어야 하고
- 애플리케이션에서도 연결 설정을 변경해서
- 배포하는 작업이 필요
Sentinel 구성
자동 Fail Over 가능한 HA 구성(High Availability)입니다.
특징을 정리하자면 다음과 같습니다.
- Sentinel 노드가 다른 노드 감시
- 마스터가 비정상 상태일 떄 자동으로 FailOver
- 연결 정보 변경 필요 없습니다.
- Sentinel 노드는 항상 3대 이상의 홀수로 존재해야 합니다.
- 과반수 이상의 Sentinel이 동의해야 FailOver가 진행됩니다.
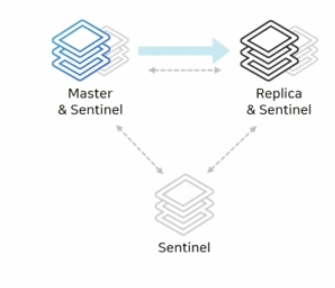
이와 같은 구성을 고려해볼 수 있습니다.
두 대의 서버에는 일반 레디스와 센티널을 함께 띄우고 최저 사양의 다른 서버에는 센티널 노드만 올려 사용할 수 있습니다.
Cluster 구성
Scale Out과 HA 구성(Hight Availability)
특징은 다음과 같습니다.
- 키를 여러 노드에서 자동으로 분할해서 저장(샤딩)
- 모든 노드가 서로를 감시하여, 마스터 비정상 상태일 때 자동으로 FailOver
- 최소 3대의 마스터 노드가 필요
선택 기준
사진으로 남겨두겠습니다.
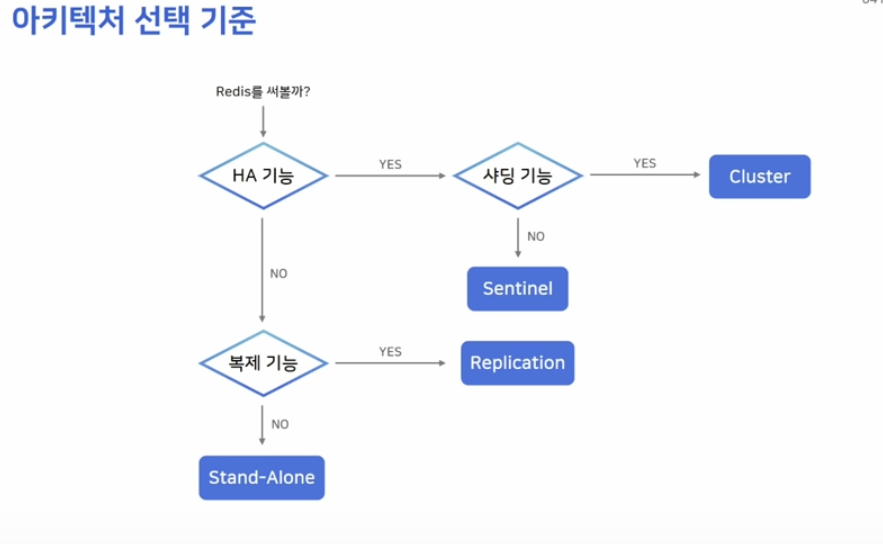
HA 가능이란 것은 자동으로 Fail Over가 가능한지를 물어보는 것과 유사합니다.
Redis 운영 팁과 장애 포인트
사용하면 안되는 커맨드
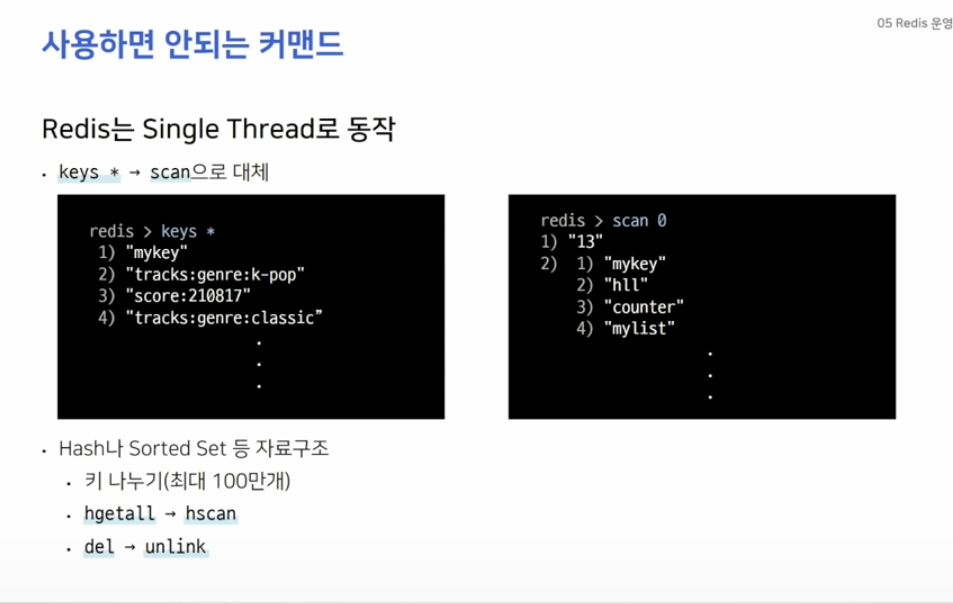
싱글 스레드로 동작하기 때문에 한 사용자가 오래 걸리는 커맨드를 사용한다면 나머지 모든 요청들은 수행할 수 없고 대기하게 됩니다.
keys는 모든 키를 보여주는 커맨드인데 이것을 scan으로 대체할 수 있습니다.
scan을 사용하면 재귀적으로 key들을 호출할 수 있습니다.
또한, key안에 저장되는 데이터들을 적절하게 나누기 위해서 Hash 나 Sorted Set 등 자료구조를 사용하는 것이 좋습니다.
del 커맨드를 사용한다면 데이터를 삭제하는 동안 아무런 동작을 수행할 수 없는데 이때 unlink 커맨드를 사용하여 key를 백그라운드에서 지워줄 수 있습니다.
⚡️ Redis의 싱글 스레드 ⚡️
레디스는 명령어들을 이벤트 루프(Event Loop) 방식으로 처리합니다. 즉, 클라이언트가 실행한 명령어들을 Event Queue에 적재하고 싱글 스레드로 하나씩 처리합니다.
장점
1. 멀티 스레드 환경이 아니라 Content Switching 발생 X
2. Deadlock 발생 X단점
1. 싱글 스레드이므로 전체 데이터 스캔과 같은 오버헤드가 큰 명령어를 처리하는 동안 다른 명령어를 처리할 수 없습니다. -> 응답 속도 저하
변경하면 장애를 막을 수 있는 기본 설정값

STOP-WRITES-ON-BGSAVE-ERROR 는 RDB 파일이 정상적으로 저장되지 않았을 때 레디스로 들어오는 모든 Write를 차단하는 기능을 합니다.
레디서 서버의 모니터링을 적절히 하고 있다면, 이 기능은 꺼두는 게 오히려 불필요한 장애를 막을 수 있는 방법입니다.
MAXMEMORY-POLICY 정책에 의해서 데이터를 삭제할지 말지 결정하는 것인데, 기본 값인 noeviction을 사용한다면 메모리가 가득 찼을 때 더이상 새로운 키를 저장하지 않는다는 것을 의미합니다.
lolatile-lru 정책은 가장 최근에 사용하지 않았던 key부터 삭제한다는 것을 의미합니다. 이때 expire 설정이 있는 key 값만 삭제합니다.
만약, expire 설정이 없는 key들만 남아있다면 위와 똑같은 장애 상황이 발생할 수 있습니다.
allkeys-lru 값은 모든 key에 대해 lru 방식으로 key를 삭제하겠다는 것을 의미하고 이 설정으로 인해 데이터가 가득 찼을 때 장애가 발생할 가능성은 없습니다.
Cache Stampede
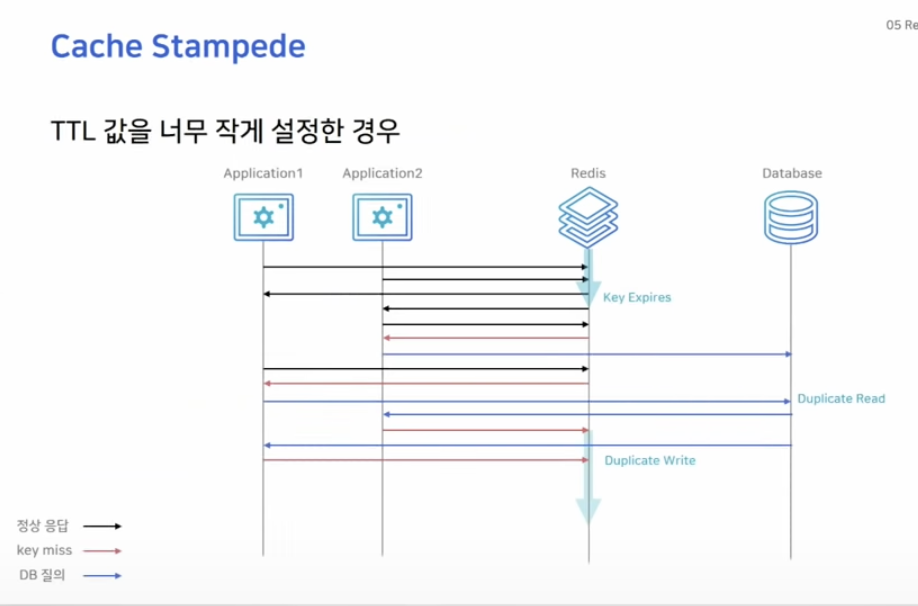
대규모의 트래픽 환경에서 TTL 값을 너무 작게 설정한 경우 Cache Stampede 현상이 발생할 가능성이 있습니다.
앞서 봤던 look aside 패턴 방식대로 동작할 때, key가 만료되는 순간에 많은 서버에서 이 key를 보고 있었다면 모든 애플리케이션 서버들이 DB에 가서 같은 데이터를 찾게 되는 duplicate read가 발생합니다.
또 읽어온 값을 레디스에 각각 write하는 duplicate write도 발생하게 됩니다.
실제로 발표자님이 말하기로, 티켓링크의 경우에 인기있는 공연이 오픈되면 그 하나의 공연 데이터를 읽기 위해 몇십 개의 애플리케이션 서버에서 커넥션이 연결된다고 합니다. 로그를 확인해가며 확인 후 TTL 시간을 넉넉하게 늘리는 것으로 해결했다고 합니다.
MaxMemory 값 설정
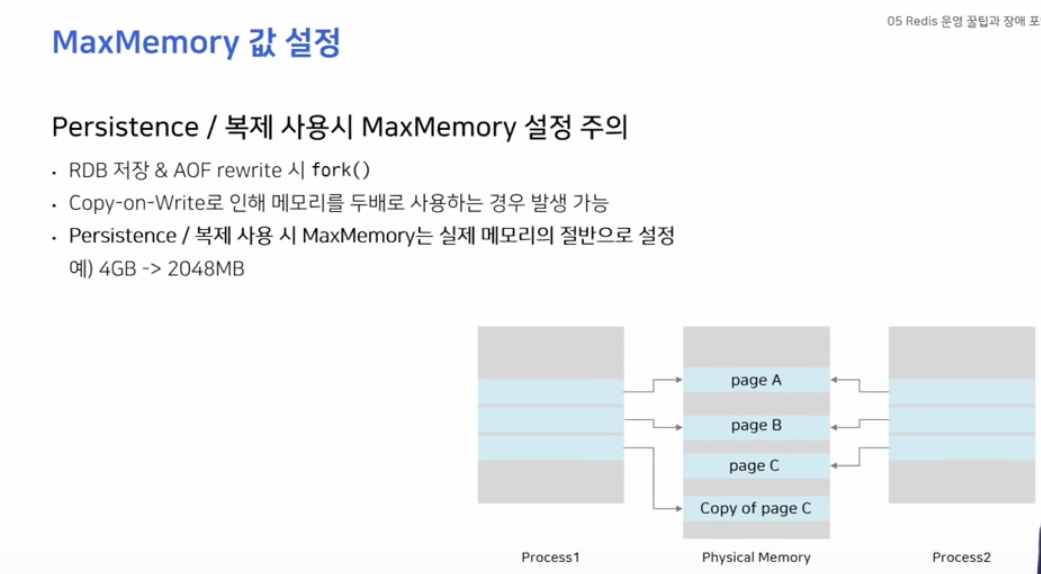
레디스는 데이터를 파일로 저장할 때 fork()를 통해 자식 프로세스를 생성합니다.
자식 프로세스로 백그라운드에서는 데이터를 파일로 저장을 하고 있지만 원래의 프로세스는 계속해서 일반적인 요청을 받아 데이터를 처리하고 있습니다.
이 과정에서 Copy-on-Write 동작으로 인해 메모리 사용률이 2배로 증가하는 상황이 발생할 수 있습니다.
이것은 영구 저장뿐만이 아닌 복제 기능에서도 주의해야 합니다.
복제 연결을 처음 시도하거나, 혹은 연결이 끊겨 재시도를 할 때에 새로 RDB 파일을 저장하는 과정을 거치기 때문입니다.
따라서 MaxMemory의 값을 실제 메모리의 절반 정도로 설정해주는 것이 좋습니다.
Memory 관리
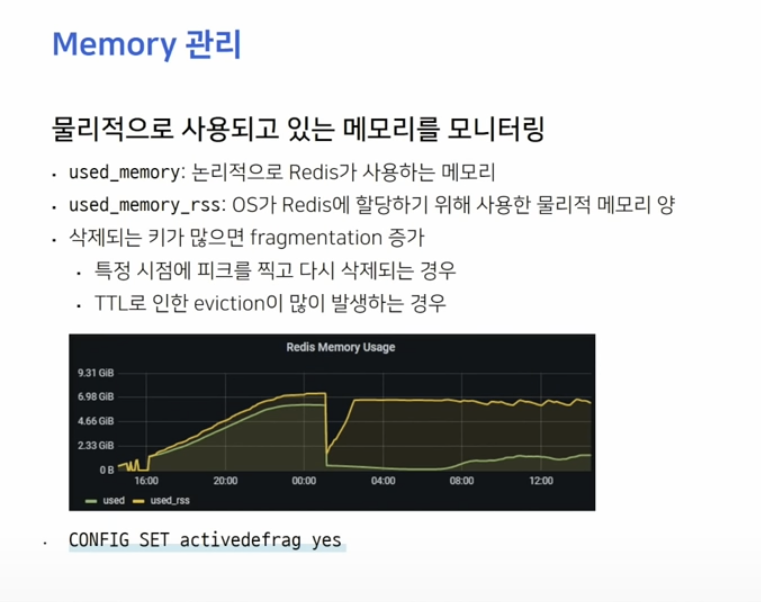
모니터링 할 때 used_memory 값이 아닌 used_memory_Rss 값을 보는 게 더 중요합니다.
공식 문서에서도 단편화가 많이 발생했을 떄 activedefrag 값을 yes로 켜두고, 평소에는 끄는 것을 권장합니다.
최종 정리
Redis는 인메모리 데이터 저장 방식을 사용하기 때문에, 언뜻 보면 서버에서 사용하는 자료 구조를 활용하면 될 것 같이 보일 수 있지만 분산된 환경에서 매우 효과적인 성능을 자랑하기 때문에 요즘 같은 대규모 네트워크 시장에서 많이 사용될 수 있습니다.
참고한 자료
