- 파이썬을 이용한 웹 스크래핑(크롤링)
-
준비물
bs4(BeautifulSoup) -
가상환경 활성 후
패키지 설치
import requests # requests
pip install bs4
- 크롤링 기본 구성
import requests
from bs4 import BeautifulSoup
URL = "긁어오고 싶은 (크롤링하고 싶은) 사이트의 주소"
headers = {'User-Agent' : 'Mozilla/5.0 (Windows NT 10.0; Win64; x64)AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.86 Safari/537.36'}
data = requests.get(URL, headers=headers)
soup = BeautifulSoup(data.text, 'html.parser')
- 개발자 도구에서 copy selector(선택자로 복사)
예시) 지니뮤직 월간 차트에서 순위와 곡명, 가수이름을 가져오고 싶을때
개발자 도구 -> HTML 요소에서 찾고자 하는 내용이 담긴 부분을 우클릭 -> copy -> copy selector
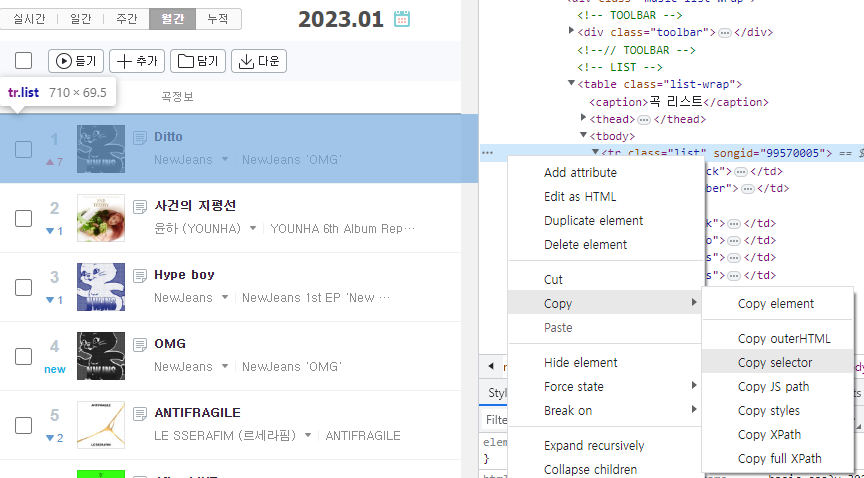
복사된 내용은 다음과 같다.
#body-content > div.newest-list > div > table > tbody > tr:nth-child(1)
tr:nth-child(1)은 부모 태그 tbody의 첫번째 자식 태그라는 의미이다.
우리는 1위 뉴진스의 Ditto에서 긁어왔으므로 tr:nth-child(1)이라고 표시되었으며
윤하의 사건의 지평선에서 내용을 가져왔다면 tr:nth-child(2)라고 표시된다.
우리는 반복문을 사용하여 차트 안 모든 곡의 정보를 가져올것이기 때문에
자식태그 정보는 불필요하다.
4. 자식 태그 정보를 제외한 내용을 변수 trs에 넣어준다.
trs = soup.select('#body-content > div.newest-list > div > table > tbody > tr')
5. 반복문을 구성한다.
for tr in trs:
title = tr.select_one('')
rank = tr.select_one('')
artist = tr.select_one('')
print(rank, title, artist)위 코드에서 변수 rank, title, arist에 들어갈 정보들을 모두 copy selector 한다.
rank는 #body-content > div.newest-list > div > table > tbody > tr:nth-child(1) > td.number
title은 #body-content > div.newest-list > div > table > tbody > tr:nth-child(1) > td.info > a.title.ellipsis
artist는 #body-content > div.newest-list > div > table > tbody > tr:nth-child(1) > td.info > a.artist.ellipsis
위 방식으로 나오나 이미 변수 trs에서 경로 tr까지 지정해 주었기에 자식 태그 부분까지 모두 지우고 사용한다.
for tr in trs:
title = tr.select_one('td.info > a.title.ellipsis')
rank = tr.select_one('td.number')
artist = tr.select_one('td.info > a.artist.ellipsis')
print(rank, title, artist)- 출력 결과
-rank

-title
 - artist
- artist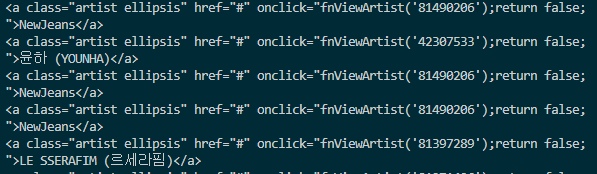
불필요한 태그 정보와 많은 공백까지 출력된다.
6. 다듬기
for tr in trs:
title = tr.select_one('td.info > a.title.ellipsis').text.strip()
rank = tr.select_one('td.number').text[0:2].strip()
artist = tr.select_one('td.info > a.artist.ellipsis').text
print(rank, title, artist)태그 등을 제외하고 텍스트만을 추출하는 .text 메소드와
공백을 제거하는 .strip() 메소드를 사용하였다.
이때 .text[0:2]는 0번째 자리부터 2번째 자리까지만을 추출한다는 의미이며
.strip()은 (), 즉 공백을 제거한다는 의미이다.
텍스트와 텍스트 사이 즉 띄어쓰기는 제거 대상으로 판단하지 않으며,
만약 데이터에서 '공백'이라는 텍스트를 제거하고 싶다면 .strip('공백') 과 같이 사용하면 된다.
- 완성본과 출력 결과
import requests
from bs4 import BeautifulSoup
headers = {'User-Agent' : 'Mozilla/5.0 (Windows NT 10.0; Win64; x64)AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.86 Safari/537.36'}
data = requests.get('https://www.genie.co.kr/chart/top200?ditc=M&rtm=N&ymd=20230101',headers=headers)
soup = BeautifulSoup(data.text, 'html.parser')
trs = soup.select('#body-content > div.newest-list > div > table > tbody > tr')
for tr in trs:
title = tr.select_one('td.info > a.title.ellipsis').text.strip()
rank = tr.select_one('td.number').text[0:2].strip()
artist = tr.select_one('td.info > a.artist.ellipsis').text
print(rank, title, artist)# 벨로그에서는 탭 인식이 안되나 반복문 안의 내용들은 탭 필수!
코드를 좀 더 잘 보여줄수 있는 툴을 빨리 찾아야겠다..

[참조]
초보도 할 수 있는 python으로 네이버에서 실시간 검색어 정보 가져오기! (2) - BeautifulSoup https://velog.io/@neulhan/%EC%B4%88%EB%B3%B4%EB%8F%84-%ED%95%A0-%EC%88%98-%EC%9E%88%EB%8A%94-python%EC%9C%BC%EB%A1%9C-%EB%84%A4%EC%9D%B4%EB%B2%84%EC%97%90%EC%84%9C-%EC%8B%A4%EC%8B%9C%EA%B0%84-%EA%B2%80%EC%83%89%EC%96%B4-%EC%A0%95%EB%B3%B4-%EA%B0%80%EC%A0%B8%EC%98%A4%EA%B8%B0-2-BeautifulSoup-1uk4asqet0
strip 메소드 설명
https://wikidocs.net/33017
https://codechacha.com/ko/python-string-strip/
