논문 링크 : Very Deep Convolutional Networks for Large-Scale Image Recognition
Abstract
이 연구에서는 convolution network depth가 그 정확도에 미치는 영향을 조사한다.
매우 작은 (3×3) convolution filter를 사용하는 아키텍처를 사용하여 depth를 증가시키는 네트워크를 사용했다.
depth를 16-19 weight layer까지 늘림으로써 이전 기술 구성에 비해 상당한 개선을 이루었다.
<성과>
ImageNet Challenge 2014 submission에서 각각 localisation와 classification track에서 1순위와 2순위를 차지했다.
또한 우리의 representation이 다른 데이터셋에도 잘 일반화된다는 것을 보여준다. 여기서 state-of-art를 달성한다.
1. Introduction
ConvNets가 computer vision 분야에서 더욱 일반화되면서(more of commodity) Krizhevsky등 원래 아키텍쳐를 개선하여 더 나은 정확도를 달성하려는 시도가 있었다.
-
ex1) ILSVRC-2013에서 best-performing submission은 더 작은 receptive window size와 첫 번째 layer에 더 작은 stride를 사용
-
ex2) 다른 개선 방향은 네트워크 전체를 전체 이미지와 여러 스케일에서 밀도있게 train, test하는 것을 다룸
이 논문에서는 ConvNet architecture 디자인의 또 다른 중요한 측면인 depth에 대해서 다룬다. 이를 위해서 우리는 architecture의 다른 parameter들을 고정하고, 모든 계층에서 매우 작은 3x3 convolution filters를 사용함으로써 네트워크의 depth를 더 많은 convolution layer를 추가하여 점진적으로 늘린다.
<결과>
우리는 ILSVRC classification 및 localisation task에서 최첨단 정확도를 달성하며, 다른 이미지 recognition 데이터셋에도 적용 가능한 훨씬 더 정확한 ConvNet 아키텍처를 개발
또한, 상대적으로 간단한 파이프라인의 일부로 사용될 때도 훌륭한 성능을 발휘한다(예: 세부 조정 없이 선형 SVM으로 분류된 깊은 특징).
[논문 구성]
- Section 2 : ConvNet configurations
- Section 3 : The details of the image classification training and evaluation are then presented
- Section 4 : The configurations are compared on the ILSVRC classification task
- Section 5 : concludes the paper
2. CONVNET CONFIGURATIONS
2.1 ARCHITECURE
- fixed-input-size: 224x224 RGB image
- Preprocessing: subtracting the mean RGB value Only
- filter size: 3x3 filter
- using 1x1 filter for non linearity
- stride : 1px
- padding : 1px (for preserved resolution after convolution)
- pooling: max-pooling(2x2 pixel window, stride=2) which follow some of the conv
- Three Fully-Connected layers
- First & Second layer : 4096 channels
- Third layer : 1000 channels
- soft-max layer
- all hidden layer's activation funtion : ReLU
2.2 CONFIGURATIONS
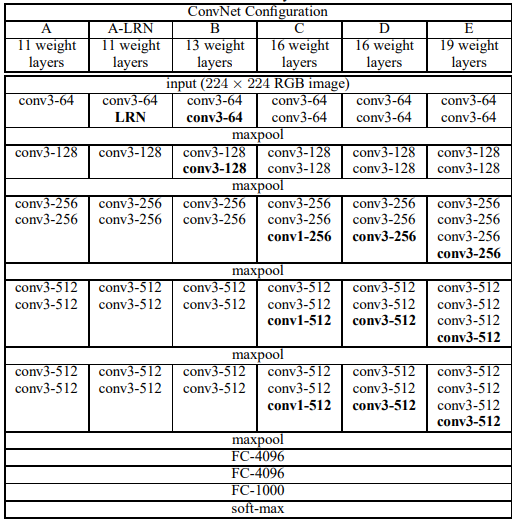
- from 11 weight layers in the network A
(8 conv. and 3 FC layers) to 19 weight layers in the network E (16 conv. and 3 FC layers). - starting from 64 in the first layer and then
increasing by a factor of 2 after each max-pooling layer, until it reaches 512
2.3 DISCUSSION
이전 연구와는 달리(11x11, 7x7 사용), 전체 네트워크에서 3x3 receptive field를 사용한다(stride 1).
두 개의 3x3 receptive field가 5x5의 effective receptive field를 가진다는 것을 알 수 있고, 3개의 3x3 receptive field는 7x7의 수용영역을 가진다.
Receptive Field란?
- 특정 뉴런이 "보는" 입력 데이터의 영역
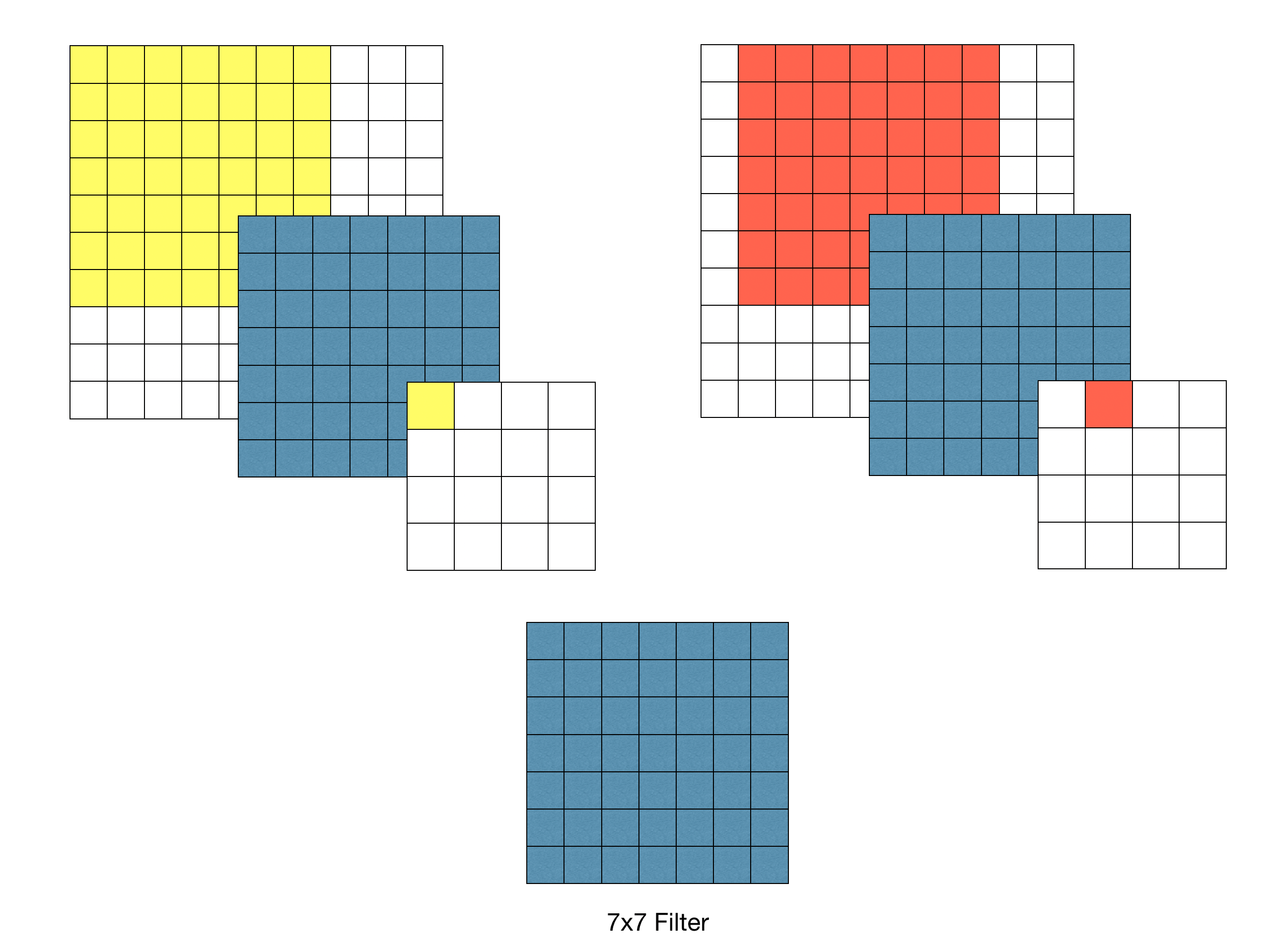
- 위 사진은 7x7 필터를 하나를 이용해 Convolution 했을 경우 출력 feature map의 한 픽셀당 보는 receptive field가 7x7이 된다.
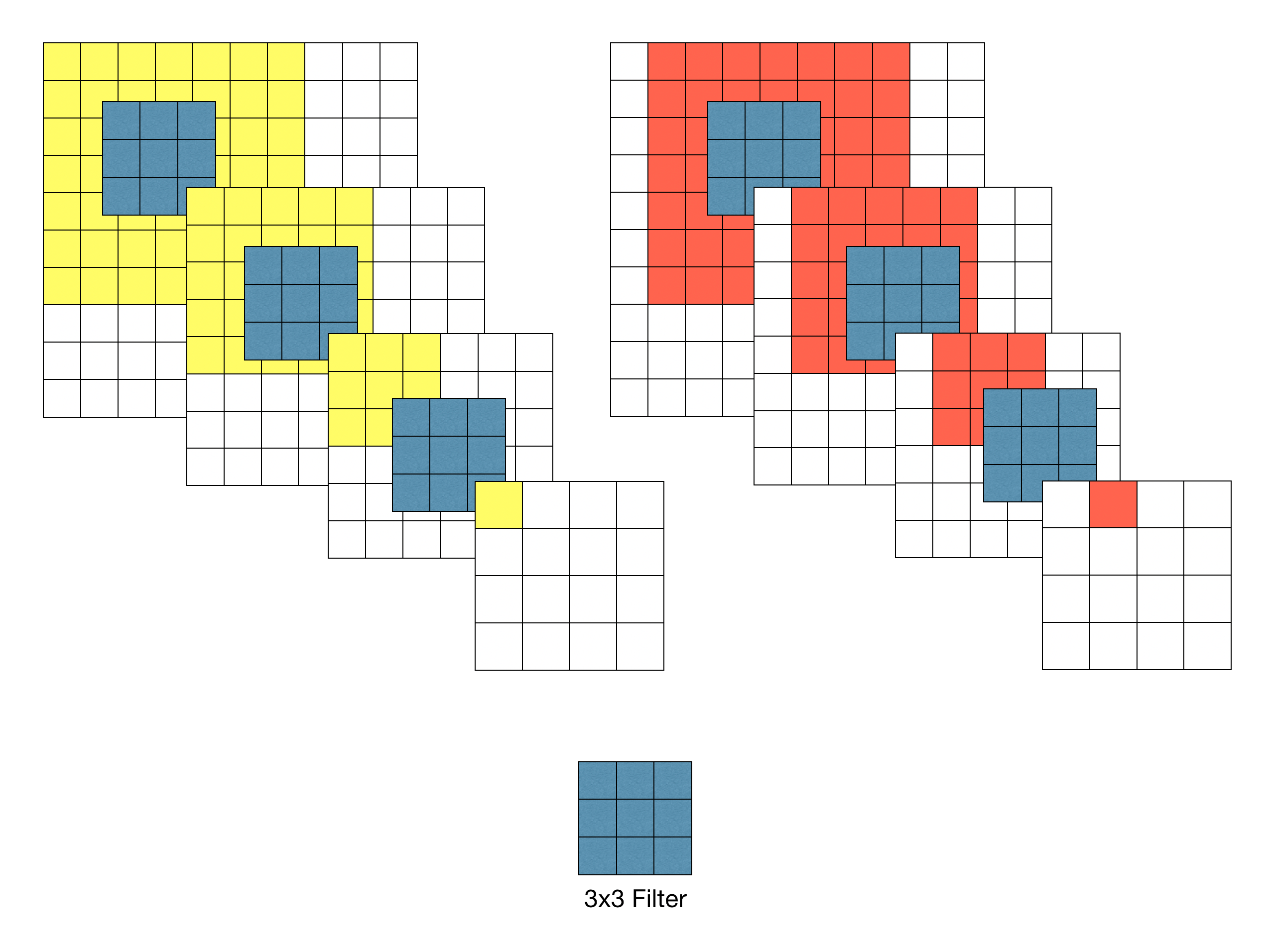
- 3x3 필터 3개를 이용할 경우 원본 이미지의 7x7 영역을 수용할 수 있다.
Q. 7x7보다 왜 3x3의 layer를 여러개 쌓았을까?
- A1. 3개의 non-linear rectification layers를 포함시켜 차별적인 decision function을 만든다.
- 여러개의 3x3 layer를 쌓음으로써 각 layer마다 비선형 활성화 함수를 적용할 수 있다.
- 이러한 비선형성때문에 모델이 더 복잡한 패턴과 관계를 학습하는데 도움이 된다.
- A2. 파라미터 수를 줄인다.
- ex) Three layer 3x3 convolution이 있고 C개의 채널로 쌓여있다고 하면, parameters는 이 되고, single 7x7 convolution의 parameters 수는 개가 된다.
Q. 1x1 Conv를 포함한 이유
- A1. 본질적으로 채널 수를 맞추기 위함도 있으나, receptive field에 영향을 주지 않고 비선형성을 증가시키는 효과도 있다.
3. CLASSIFICATION FRAMEWORK
3.1 TRAINING
학습은 Alexnet 과정을 따라가며(input image crop 과정 제외) train은 momentum을 가진 mini-batch gradient descent를 사용하여multinomial logistic regression objective(여러 개의 클래스를 대상으로 분류 문제를 해결)를 최적화한다.
- Batch size : 256
- momentum : 0.9 (L2 regularization)
- weight decay :
- dropout : 0.5 (first two fully-connected layers)
- learning rate : initally set to , and then decreased by a factor of 10 when the validation set accuracy stopped improving
- 여기서는 총 3번 감소시킴
- learning was stopped after 370k iterations(74 epoch)
AlexNet보다 더 많은 parameter 수와 더 큰 depth를 가지고 있었음에도 네트워크가 수렴하기 까지 더 적은 epoch를 필요로 했는데, 그 이유는 아래의 두 가지 이유 때문이다.
- 더 깊은 depth와 더 작은 conv로 인해 부과된 implict regularisation
- 특정 layer의 pre-initialisation
적절하지 않은 가중치는 gradient를 불안정하게 하기 때문에 가중치를 초기화하는 것은 매우 중요하다. 이러한 문제를 해결하기 위해서 가중치를 랜덤으로 초기화하여 훈련했다.
아키텍쳐가 깊어질수록, net A의 처음에 4개의 conv layers와 마지막 FC layer들을 초기화했다. pre-initialisation된 layer들은 learning rate를 감소하지 않았고 학습 도중에 바뀌도록 했다. random initialisation에 대해서, 평균이 0이고 분산이 인 normal distiribution에서 가중치를 샘플링했다. biase는 0으로 초기화했다.
고정된 224x224 size의 input image를 얻기 위해서, rescaled된 training images로부터 randomly cropped했다(한 SGD iteration 당 one crop). 그리고 training set을 더 다양하게 만들기 위해서 잘린 부분은 random horizontal flipping, random RGB color shift를 했다. 더 자세한 방법은 아래에 나온다.
Training image size
S는 rescaled된 train image의 가장 작은 side라고 하자. 이미지가 crop된 size는 224 × 224로 고정되어 있지만, 원칙적으로 S는 224보다 작지 않은 어떤 값이든 가질 수 있다.
S = 224의 경우 잘린 부분은 train image에서 가장 짧은 부분을 224로 맞춰주며, 원래 사이즈의 비율을 지키며 resizing 한다.(isotropically-rescaled)
S를 설정하는 데에는 2가지 접근법이 있다.
- single-scale training
- 를 256이나 384로 고정시킨다. 만약 size를 384로 고정시킨 경우 speed-up을 위해서 size를 256으로 고정시켜 pre-trained 된 모델을 사용하고, 초기 learning rate를 보다 작게 설정한다. (이미 많이 학습이 진행되었기 때문)
- multi-scale training
- 를 256~512 사이의 값으로 random하게 rescaled한다. image의 object들은 크기가 각각 다를 수 있기 때문에, size를 다르게 해서 train하는 것은 학습에 도움을 준다. (Scale Jittering)
speed-up을 위해서 고정 S = 384로 pre-trained 된 single-scale 모델의 모든 layer를 fine-tuning하여 multi-scale 모델을 훈련했다.
3.2 TESTING
이미 fully-convolution network는 전체 이미지에 적응했기 때문에, sample multiple-crop은 필요하지 않다. training scale S와 test size인 Q를 맞춰 줄 필요는 없으나, 맞춰주면 성능이 더 좋아진다.
FC connected layer는 먼저 convolution layer으로 변환된다. (첫 번째 FC layer는 7 × 7로, 마지막 두 FC layer로 1 × 1로).
이미지의 horizontal filpping으로 test set agumentation. 이미지를 분류할 때 원본 이미지와 뒤집힌 이미지를 모두 사용하고, 두 이미지에 대한 softmax 확률을 평균내어 이미지의 최종 점수를 결정.
완전 합성곱 네트워크가 전체 이미지에 적용되기 때문에, 테스트 시간에 multiple crop을 할 필요가 없다. 이는 각 crop 대해 네트워크를 다시 계산해야 하므로 효율적이지 않다.
4. CLASSIFICATION EXPERIMENTS
추후 추가 ...
5. CONCLUSION
-
large scale image classification을 위한 deep conv networks(최대 19 layer)를 평가했다.
-
conv architecture를 이용하여 ImageNet challenge dataset에서 SOTA를 찍었으며, classification accuracy에서 depth의 이점을 입증했다.
Reference
1. https://inhovation97.tistory.com/44
2. https://codebaragi23.github.io/machine%20learning/1.-VGGNet-paper-review/
3. https://deep-learning-study.tistory.com/398
