weight & biases
- 머신러닝 실험을 원활히 지원하기 위한 상용도구이다.
- 협업, code versioning, 실험 결과 기록 등을 제공한다.
- MLOps의 대표적인 툴이다.
예시
- 회원가입 후, 프로젝트 생성하고 진행하면 된다.
import wandb
wandb.init(project="my-test-project", entity='')
# API key 입력
# config 설정 (hyper-parameter 정보)
# for문을 사용하여 다양하게 설정 가능
config = {
"epochs" : EPOCHS,
"batch_size" : BATCH_SIZE,
"learning_rate" : LEARNING_RATE
}
# 설정한 프로젝트 이름과 config dict type으로 넣어준다.
# config를 project template에 넣어서 한다면 편하게 할 수 있다.
wandb.init(project="my-test-project", config=config)
# 아래와 같은 방식으로도 가능하다. 위의 방식이 더 편할 것이다.
# wandb.config.batch_size = BATCH_SIZE
# wandb.config.learning_rate = LEARNING_RATE
for e in range(1, EPOCHS+1):
epoch_loss = 0
epoch_acc = 0
for X_batch, y_batch in train_dataset:
X_batch, y_batch = X_batch.to(device), y_batch.to(device).type(torch.cuda.FloatTensor)
# ...
optimizer.step()
#...
# 기록하고 싶은 값을 적어주면 된다.
wandb.log({
'accuracy' : train_acc,
'loss' : train_loss
})
위와 같이 성능과 사용한 하이퍼 파라미터를 비교할 수 있다.
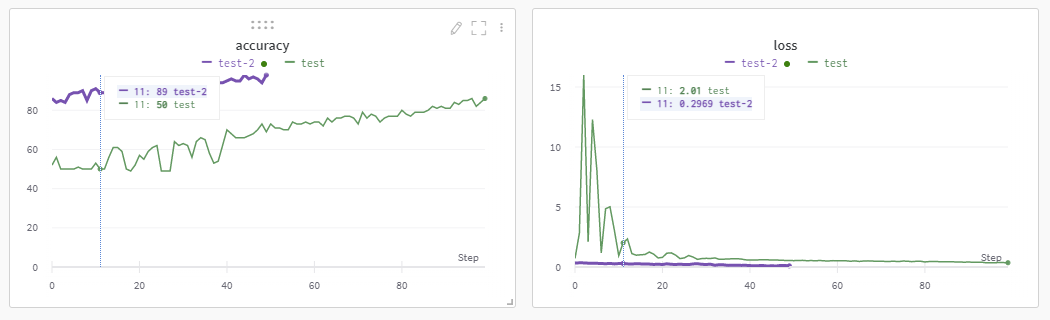

기업 단위는 쓰려면 돈 내고 써야한다는데, 쓸 수 있을 때 마음껏 쓰자!

Keep on dreaming and dreaming