연관성 분석 (Association Analysis)
- 대규모 데이터셋에서 항목 간 관련성을 파악하는 탐색적 데이터 분석 기법
- 장바구니 분석 (Market Basekt Anlaysis)
- 서열분석 (Sequence Analysis)
- A를 구매한 후, B 구매
- 컨텐츠 기반 추천 (Contents-based Recommendation)의 기본 방법론
- 유튜브, 넷플릭스
예시로, 마트에서는 다양한 상품을 판다. 그 중, 빵이랑 우유를 같이 구매하는 경우가 많다면, 빵과 우유의 관련성이 높다고 판단할 수 있다. 이를 통해, 빵을 산 사람에게 우유를 추천하거나 우유를 산 사람에게 빵을 추천함으로 판매량을 높일 수 있다.
실제 예시로, 월마트에서 맥주와 기저귀를 같이 구매하는 경우가 많아 기저귀와 맥주를 같이 배치해 판매한 경우가 있다.
지지도, 신뢰도, 향상도
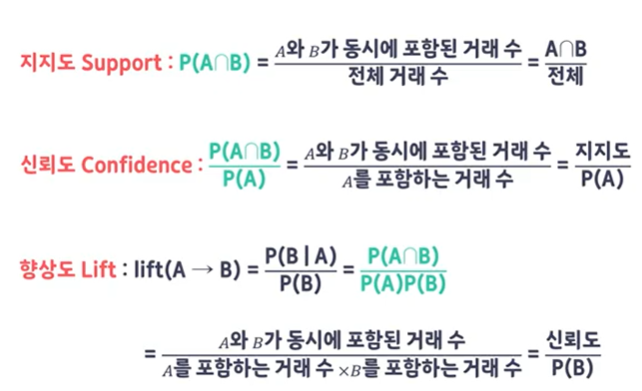
지지도 (Support)
- 데이터 전체에서 상품 A와 상품 B를 동시에 포함한 거래의 비율

신뢰도 (Confidence)
- 상품 A를 포함한 거래 중, 상품 A와 B가 같이 포함된 확률

향상도(Lift)
- A가 구매되지 않았을 때 품목 B의 구매 확률 대비 A가 구매됐을 때 품목 B의 구매확률의 증가 비
- 1: 관련이 없음, 상호 독립적인 관계, > 1: 양의 상관관계, < 1: 음의 상관관계

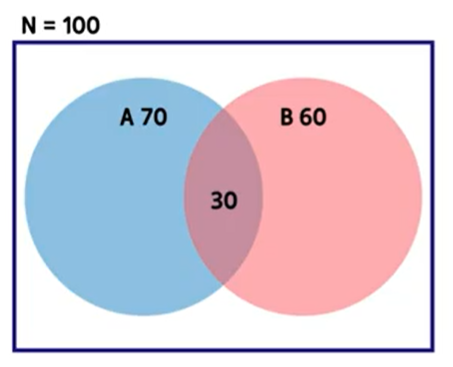
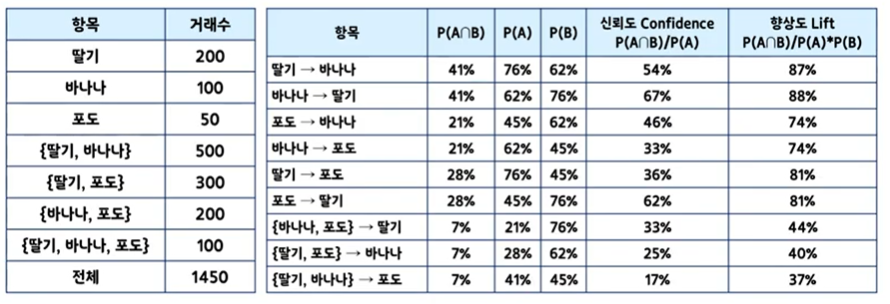
예시
연관성 분석의 장단점
장점
- 분석 결과가 이해하기 쉽고 실제 적용하기에 용이
- 특별한 분석 방향이나 목적이 없을 때, 연관성 분석으로 탐색하기 가능
단점
- 정답이 정해져 있지 않은 비지도 학습이라 품목이 많아질수록 비효율적이다.
- 품목이 많아질수록 연관성 규칙이 더 많이 발견
- 의미성에 대해 사전 판단이 필요
- 상당 수의 계산과정이 필요

유사한 품목을 한 범주로 일반화하거나 적절히 구분되는 큰 범주로 분석한 후, 중요한 일부 범주만 세부 분석을 하기도 한다.
Apriori 알고리즘
- 최소 지지도 이상의 빈발 항목 집합만 찾아내서 연관규칙을 계산
- 최소지지도 이상의 한 항목집합이 빈발(frequent)하다면, 이 항목집합의 모든 부분집합 역시 빈발항목집합으로 연관규칙 계산에 포함
- 최소지지도 미만의 한 항목집합이 비빈발(infrequent)하다면, 이 항목집합을 포함하는 모든 집합은 비빈발항목집합으로 가지치기(pruning)
- 이후 최소신뢰도 기준(Minimum Confidence Criteria)를 적용해서, 최소 신뢰도에서 미달하는 연관규칙은 다시 제거하여 반복 작업을 수행
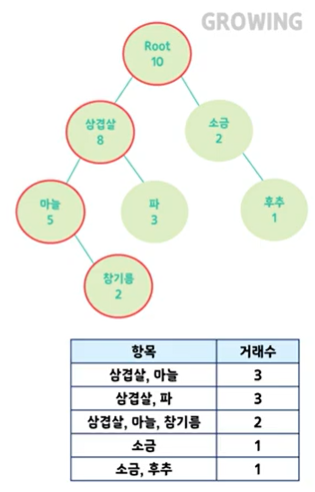
FP-Growth 알고리즘
- Frequent Pattern Tree 생성
- 거래 빈도가 높은 순으로 상품 나열
- Root 노드를 만들고 빈도가 높은 순으로 노드 추가
- 어떤 아이템이 들어왔을 때, 트리를 통해 추천 아이템 전달
- 분할 정복 방식을 통해 Apriori 알고리즘보다 더 빠르게 빈발항목집합을 추출
Reference

Keep on dreaming and dreaming