Introduction
지난번의 LOLJOA 프로젝트의 실험을 통해 POD 개수와 1초 안에 늘어난 동시 접속자의 수의 상관관계를 알아봤다. 하지만 결과는 실망스러웠다.
-
Auto Scaling하는 과정조차 Pod가 올라가고 liveness-Probe와 Readiness 프로브가 Pod가 완료되었음을 알린 후 HTTP Request가 처리까지의 시간이 오래 걸려 한꺼번에 1000이상의 사용자가 접속했을 때 성능의 향상은 생각하기 힘들었다.
-
그렇다면 Auto Scaling은 무엇을 위해 존재하는 것일까? Auto Scaling이 시간이 걸리는 작업이라면 Service를 사용하는 사용자의 수가 천천히 늘어 났을 때 효과가 있지 않을까? 하는 생각이 들어 직접 실험을 해보았다.(하지만 이마저도 실패로 돌아갔다.)
-
성능은 Pod를 늘릴수록 떨어졌고 우리는 Transaction을 고려하여 코딩을 한 후에도 성능의 개선은 있었지만 결과적으로 1개의 Pod가 가장 성능이 좋다. 라는 이상한 결론만 내리게 되었다.
나는 궁금한 것은 못참는다. 지난날의 궁금증을 해결하기 위해 생길 수 있는 문제를 직접 가정하여 실험을 진행하였다. 이것이 LOLLIPOP 프로젝트의 부하테스트 부분의 핵심이다.
물론 LOLJOA 프로젝트는 AWS 환경에서(비용이 적었지만) 실험 하였고 지금은 개인 프로젝트로 가상환경(Ubuntu, Master, Worker0, Worker1: 2CPU 4GB)에서 직접 Kubernetes 클러스터를 구축하여 실험하였다. 결과를 알아보자
결과
Database와 서버의 관계
일단 DB의 성능이 충분하지 않으면 아무리 서버의 개수가 늘어나도(성능이 좋아진다) 하더라도 전체 클러스터의 TPS는 좋아지지 않는다. 오히려 감소하기 까지 하였다.
-
2 APIServer / 2 Database

-
3 APIServer / 2 Database
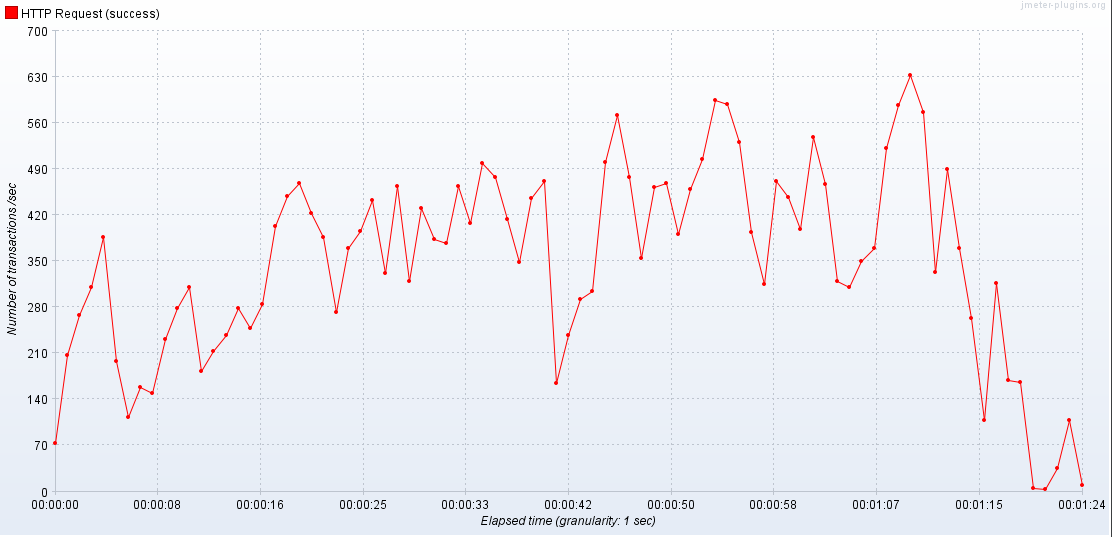
JMeter가 알려주다시피 성능이 저하된다. 이 전의 LOLJOA 프로젝트에서는 RDS에서 DB 하나를 생성하여 테스트를 진행하였었는데 이것이 문제였던 것이었다.
서버의 성능이 올라가면 DB의 성능 또한 같이 고려해야 한다.
Pod 개수와 TPS의 관계
1번. 200명의 동시 접속(Infinite, 1초마다)
1-1. 1 APIServer / 2 Database
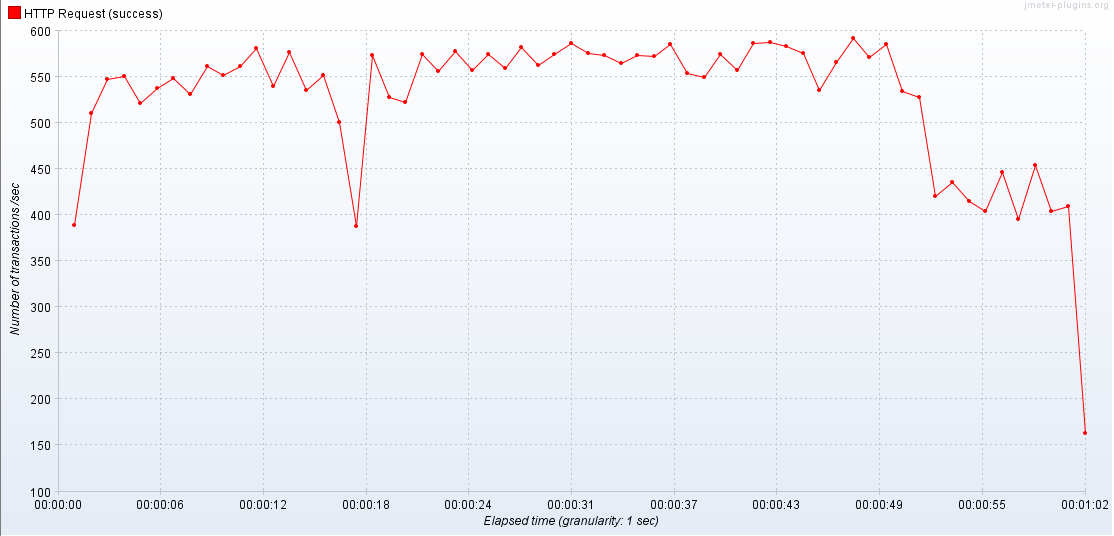
1-2. 2 APIServer / 2 Database
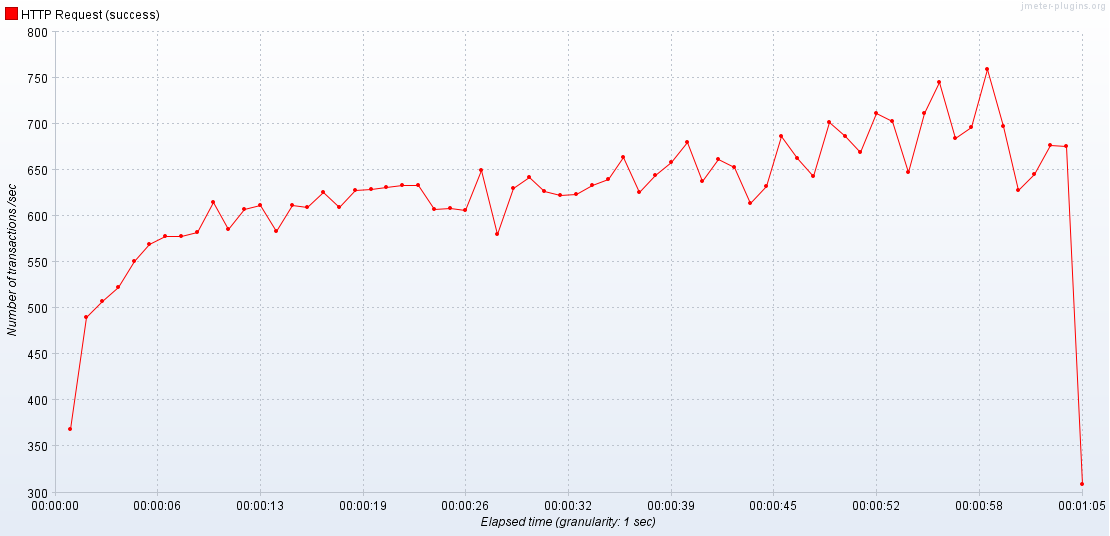
2번. 1000명의 동시 접속(Infinite, 1초마다)
2-1. 1 APIServer / 2 Database
2-2. 2 APIServer / 2 Databse
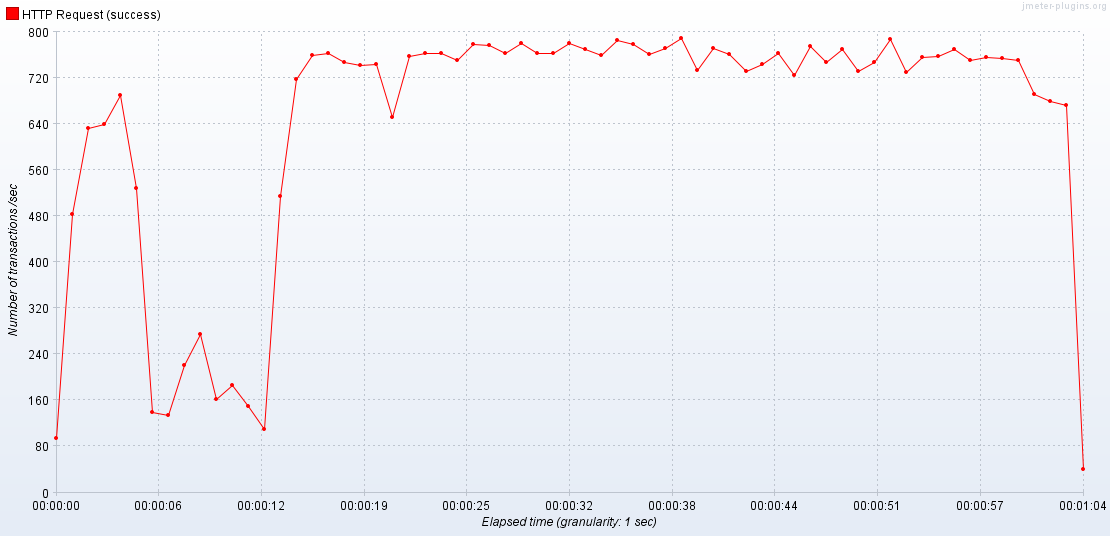
서버가 늘어나면 최대 TPS도 같이 상승한다.
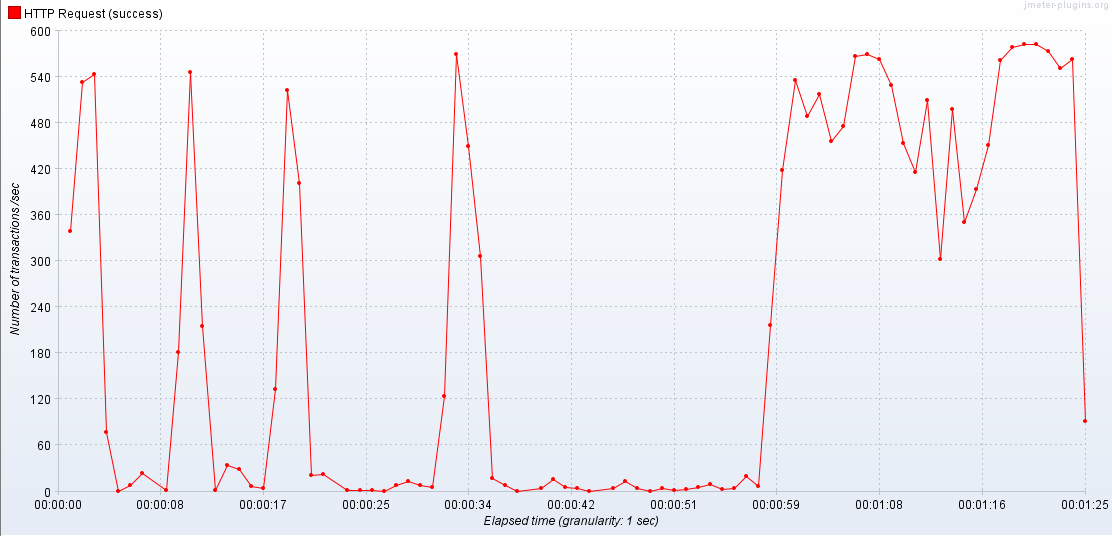
DB 자원 증가의 영향
-
2 APIServer / 2 Databse
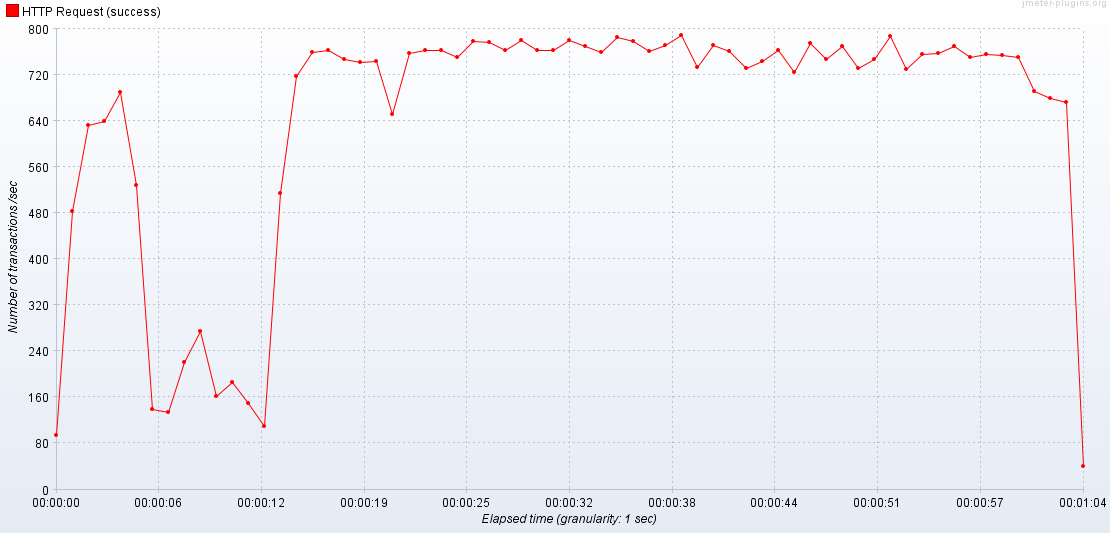
-
2 APIServer / 3 Database
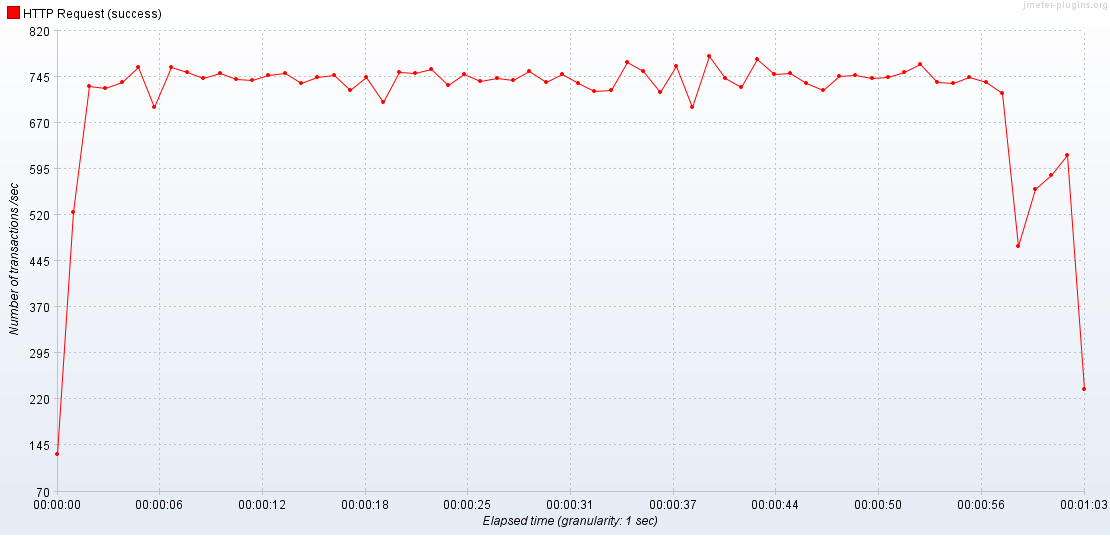
DB의 자원이 풍족할때에는 최대 TPS의 상승은 없지만 TPS가 훨씬 안정적이다.(편차가 적다.)
다다익선?
3 APIServer / 3 Database
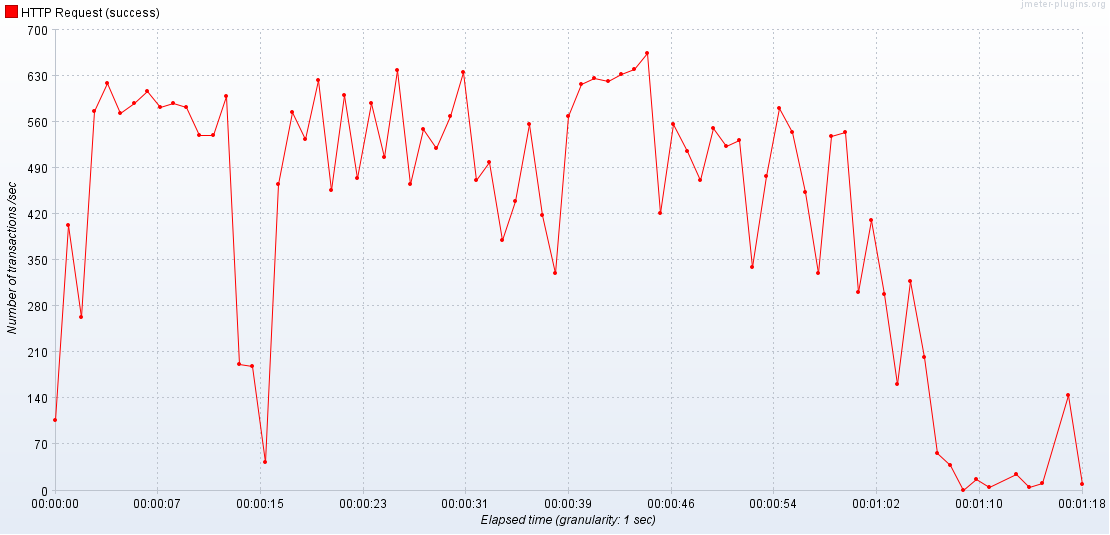
근데 이게 늘어난다고 무조건 좋은 것은 아니다. 현재 클러스터의 사양을 고려해서 Pod를 늘려야 한다. 그렇지 않으면 성능이 저하된다.
서버가 최소 1GB를 먹는다 해도(6GB / 12GB) k8s와 같이 돌리고 있기 때문에 성능을 고려하지 않고 많이 만들면 성능이 저하된다.
DB는 그럼 어떻게 늘려?
이건 다음 포스팅으로...
