Data Streaming Platform(Event Streaming Platform)
⚪ Producer
주요 고려사항
- Producer-Ack: Producer가 받는 성공 응답
- 0 : 응답 X(메시지 손실 가능성, 성공 여부 알 수 없음)
- 1 : Default, Leader가 수신하면 성공 응답(최대 한번 쓰기 보장)
- all(-1) : Follower까지 수신 완료하면(최소 한번 보장)
- 1은 장애 대응이 어느정도 가능해 보이지만 0은 장애대응을 하지 않는 느낌이다.
- 당연히 확실할 수록 느리다
- Producer-Retry: 일시적 오류를 보완하기 위한 재시도 횟수
- 횟수, 대기시간, timeout 시간, delivery.timeout(전체 프로세스 제한 시간)
- ack가 0이면 무의미
- 보통 횟수 대신 delivery.timeout을 조정
- Batch 처리
- Batch 생성 시간, Batch 크기
- 보통 100, 1000000으로
- 메시지 Send 순서
- max inflight message의 개수(이러면서 순서 꼬임)
- 비동기 요청이라고 볼 수 있다
- 여기서 같은 파티션에 대해 하나의 batch 실패를 전체 실패로 간주하는 idempotence 설정이 가능
- Page Cache
- Partition의 Segment는 OS Page Cache에 기록
- Zero Copy함(결국 받은 걸 그대로 전달하므로)
- Broker 종료 or OS에서 Flusher Thread 실행하면 디스크로 Flush 됨
- 자체 Flush 정책
- 시간 또는 메시지 수를 기준으로 fsync(Flush) 가능
- 기본값으로 유지하는 것을 권장
- 운영체재의 background Flush 기능을 더 효율적으로 허용하는 것을 선호하기 때문에 기본적으로 fsync는 비활성화 되어있음
- Flush 항목 표시하는 vmtouch라는 Linux 도구 존재
- .log 파일에 Flush 와 Flush X(OS Buffer) 항목 모두 표시됨
추가 설명
Producer Delivery Timeout
전체 프로세스가 send(버퍼 할당), batch(batch 생성), await send, retries(backoff time 즉 retry 대기시간), inflight(재시도 응답 대기시간)으로 구성되어 있는데 send 이후의 시간이 delivery time이라고 볼 수 있다.
메시지 순서 꼬임 시나리오
- 예) 실패하고 성공하면 뒤에 것이 먼저 commit 됨
- 당연히 실패한 것은 ack에 따라 retry 함(순서 밀림)
Zero Copy
User Space가 아닌 CPU 개입 없이 Page Cache와 Network Buffer 사이에서 직접 전송됨(Heap 절약, 속도 높음) CPU 연산이 필요없이 그대로 전달할 경우 사용 가능
Replica 사용 이유
- OS가 Flusher Thread를 통해 디스크로 Flush하기 전 Broker에 문제가 발생하면 데이터가 손실됨
- 복제 되어 있다면 Leader가 된 복제본에서 다시 복사해오면 되니까
- 즉 replica 없으면 영구적으로 데이터 손실됨
⚪ Replica
주요 고려사항
- zookeeper에서 Leader가 보낸 Follwer가 fetch 완료했다는 정보를 시간 안에 fetch 받지 못하면 ISR에서 제거함
- 최대 시간을 설정 가능
- Leader가 Fail 하면 새로운 ISR을 zookeepr에서 선출
- Leader가 fail하면 당연히 메시지가 손실될 수 있다.
- 새로운 Leader가 선출될 때까지는 해당 Topic 사용 불가(retries가 0이면 NetworkException 발생)
- 결국 Relication은 Leader(선출된, 원래)를 중심으로 sync가 됨
- 장애 후 복구라면 HWM을 고려하기도 한다.*
- 내구성과 가용성(Silver bullet) 관련 파라미터
- ISR 리스트에 없는 Replica를 Leader로 선출 가능한가(파라미터)
- 최소 ISR 개수(ISR이 이거보다 작으면 Producer에서 NotEnoughReplicas 예외 수신)
- 위는 ack=all과 함께 사용되어 내구성 보장
추가 설명
메시지 중복 발생 시나리오
- ACK=all의 경우 Leader에서 장애 발생
- 선출된 Leader에 의해 선출된 Leader 기준으로 sync 후 high waterMark 갱신
- Leader가 장애가 나서 아직 Follower에 commit이 완료되지 않았으므로 producer에서 retry 시도
- 선출된 Leader 기준으로 sync가 진행되어 retry 시에 중복 메시지 발생 가능
아래는 M3, M4를 Commit하기 전에 Broker X에서 장애가 발생한 상황
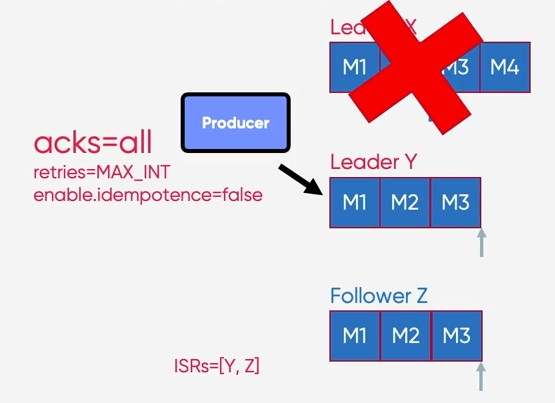
장애가 복구되어 Leader X가 살아나면 X는 Y로 부터 epoch 데이터를 받아서 Leadership이 변경된 시점(HWM)부터의 데이터는 Truncate
메시지 중복 발생 시나리오
- 위의 상황에서 ACK가 1이라면 M4가 손실될 것이다.
- 왜냐하면 M4 까지를 잘 수신했다고 Producer를 판단하기 때문
⚪ Consumer
주요 고려사항
- Group Coordinator의 Consumers의 JoinGroup 요청에 대한 대기 시간
- Consumers 각각이 Consume 할 최대 Partition 수를 요청 순서대로 매핑(Group Leader: 매핑 정보 저장)
- 연산은 Consumer에서 진행, 매핑 정보는 Broker에서 메모리 캐시 후 Zookeeper에서 유지
- 결국 Consumer 그룹 매핑 연산 및 리밸런싱 관련 연산은 Group Leader에서 진행
- 이는 Broker의 부담을 줄이기 위함
- 불필요한 Rebalancing은 피해야 함
- Rebalancing 시에 모든 Consumer가 정지함(Offset을 Commit)
추가 설명
Consumer 관련 성능 최적화
- Consumer Group 멤버 고정
- 재가입의 경우 Rebalance를 Trigger하지 않음
- session Timeout 튜닝
- heartbeat interval = session timeout / 3
- group min session timeout < session Timeout < group max session timeout
- Consumer가 재가입할 수 있는 더 많은 시간을 제공
- 장애 감지하는데 오래 걸림
- poll interval 튜닝
- Consumer가 poll 한 데이터를 처리할 수 있는 충분한 시간
- 너무 크면 놀겠지?
⚪ Partition Assignment
주요 고려사항
- RangeAssignor: Default
- 동일한 Key를 가지는 메시지에 대한 Topic 간에 co-partitioning 유리
- Topic간 Partition의 개수가 같아야함
- RoundRobinAssignor: Round Robin(번갈아 가면서 할당)
- 재할당 후 Consumer가 동일한 Partition을 유지 X(전체 다시 할당)
- 할당 불균형이 발생할 수 있음
- StickyAssignor: 최대한 많은 기존 Partition 할당을 유지하면서 최대 균형을 이룸
- Topic Partition이 하나의 Consumer에서 다른 Consumer로 이동할 때의 오버헤드를 줄임
- CooperativeStickyAssignor: 동일한 StickyAssignor를 따르지만 협력적 Rebalance 허용
- ConsumerPartitionAssignor: 인터페이스 구현하면 사용자 지정 할당 전략 사용 가능
추가 설명
Consumer Rebalance 과정
- 각 Consumer들이 JoinGroup 요청을 Group Coordinator에 전송
- 제일 먼저 들어온 Consumer가 Leader로 선정
- JoinGroup 응답 전송
- Leader Consumer가 Partition 할당 정보 연산
- 각 Consumer가 SyncGroup 요청
- SyncGroup 응답 전송
- 연산된 Partition 할당 정보 전송
Rebalancing Protocol
- Eager Rebalancing: 각 구성원은 JoinGroup 요청을 보내고 재조정에 참여하기 전에 소유한 모든 Partition 구독을 취소(Synchronization Barrier 기간이 좀 김, 내구성 높음)
- Incremental Cooperative Rebalancing Protocol : 새로 할당된 partition 중 Revoke 되어야할 Partition만 Revoke
- 특정 Consumer만 가동 중지 할 수 있음
- Consumer는 할당된 Partition 중 어떤 Partition을 재할당 해야하는지 모름
- Cooperative Sticky Assignor: Rebalancing 2번 수행
- 1번쨰 Rebalancing에서 Consumer에게 어떤 Partition을 Revoke 해야하는 지 알려줌
- 실제 consumer가 멈추는 시점은 2번째 Rebalance가 시작되는 지점 부터
⚪ EOS
주요 개념
- At-Most-Once(최대 한번)
- 메시지 손실 가능성(Topic 기록 X)
- 중복 가능성을 피하기 위해 때떄로 메시지 전달되지 않을 수 있음을 허용
- At-Least-Once(최소한번)
- ack를 Producer가 수신
- 중복 메시지를 수신할 가능성(ack를 보내기 직전에 오류 발생)
- Exactly-Once
- Producer가 메시지 전송을 다시 시도하더라도 메시지가 최종 Consumer에게 정확히 한번 전달
- 메시징 시스템과 App 간의 협력이 필요함
- Offset을 되감으면 모든 메시지를 중복 수신할 수도 있음
- Transaction 기능을 사용하여 하나의 트랜잭션 내의 모든 메시지가 모두 Write 되었는지 확인(Atoimic Message)
- Transaction 관련
- Consumer Coordinator : 각 Producer에게 Transaction Coordinator가 할당, PID 할당 및 Transaction 관리 로직 수행
- Transaction Log : Internal Topic(영구적으로 복제된 Record 저장하는 Transaction Coordinator의 상태 저장소)
- TransactionalId : Producer를 식별하기 위한 값
주요 고려사항
- 주요 Parameter
- Transaction 상태 업데이트 수신하지 않고 사전에 만료되기 전에 대기하는 시간
- Transaction에 할당된 시간
- Replication Factor, Partition 개수, min ISR 개수, Segment 크기
추가 설명
내구성을 위해 DBMS 설정, Validation 등 다양한 방식으로 메시징 시스템의 중복방지 시스템 뿐 아니라 Application에서도 중복 방지를 위한 로직이 필요함
Java Client에서 Fully Supported
1. Producer, Consumer
2. Kafka Connect
3. Kafka Streams API
4. Confluent Rest Proxy
5. Confluent ksqlDB
Transaction Coordinator : 특수한 Transaction Log를 관리하는 Broker Thread
- 일련번호(Producer Id, Sequence Number, Transaction ID)를 할당하여 Client가 메시지 헤더에 포함하여 메시지 식별
- Sequence Number는 Broker가 중복된 메시지를 skip할 수 있게 함
요구사항
- Idempotent Producer
- enable.idempotence = true : 고유한 Producer ID
- 매핑정보 .snapshot 파일로 저장(Producer ID : Sequence Number)
- Transaction API를 사용
- Consumer에서 isolation.level을 read_committed 설정
- Broker의 파라미터는 Default 값으로 설정되어 있음
